



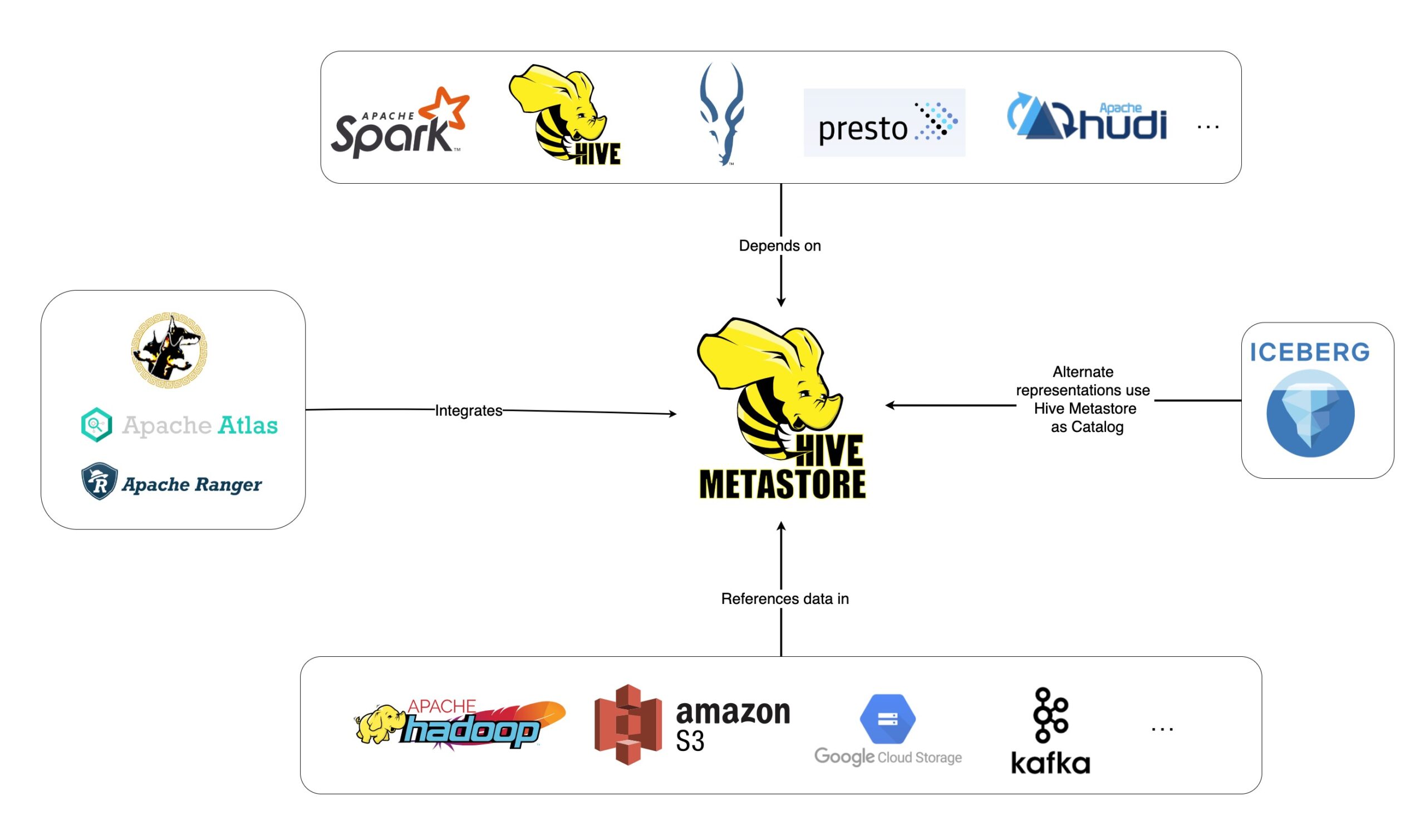
Apache Hive는 대규모로 확장 가능한 분산 스토리지 시스템에 저장된 데이터를 쿼리하고 분석하기 위한 오픈 소스 데이터 웨어하우징 소프트웨어 솔루션입니다. 2008년 Apache Software Foundation에서 오픈 소스 프로젝트로 만들어졌습니다. Apache Hive는 주로 하둡 분산 파일 시스템(HDFS)에 저장된 대규모 데이터 세트에 대한 데이터 관리 및 분석 작업에 사용됩니다. HDFS에 저장된 데이터를 쿼리하고 관리하기 위한 SQL과 유사한 인터페이스를 제공합니다. Hive는 Hadoop을 기반으로 구축되었으므로 Hadoop에 저장된 데이터와 상호 작용하고 관리하는 방법을 제공합니다. Hive는 SQL과 유사한 언어를 제공하여 사용자가 데이터를 쿼리할 수 있도록 함으로써 데이터에 대한 임시 및 탐색적 액세스를 지원하도록 설계되었습니다.
Hive는 다양한 스토리지 시스템에서 데이터를 결합, 변환 및 요약하는 기능을 포함하여 다양한 데이터 처리 기능을 제공합니다. 인덱싱, 파티셔닝, 버킷팅과 같은 포괄적인 기능 세트를 제공하여 사용자가 최적의 방식으로 데이터를 로드할 수 있도록 합니다. 또한 Hive는 데이터 유형 지원 및 메타프로그래밍을 제공하므로 사용자는 보다 직관적인 방식으로 데이터를 추상화하고 데이터 조작 작업을 작성할 수 있습니다.
Apache Hive는 UDF(사용자 정의 함수)에 대한 광범위한 지원으로도 유명합니다. 이 기능을 통해 사용자는 자신만의 사용자 정의 UDF를 생성하여 데이터를 처리하고 분석할 수 있습니다. Apache Hive는 또한 스트리밍 및 실시간 데이터를 관리하고 작업할 수 있으므로 기계 학습 및 AI와 같은 애플리케이션에 더 적합합니다.
결론적으로 Apache Hive는 Hadoop 클러스터의 데이터 관리를 위한 강력한 도구입니다. 광범위한 기능 라이브러리와 SQL과 유사한 인터페이스를 통해 사용자는 데이터를 빠르고 효율적으로 쿼리, 분석 및 변환할 수 있습니다. Apache Hive는 빅 데이터 작업을 위한 포괄적인 플랫폼을 제공하므로 개발자와 데이터 과학자에게 귀중한 도구입니다.
