



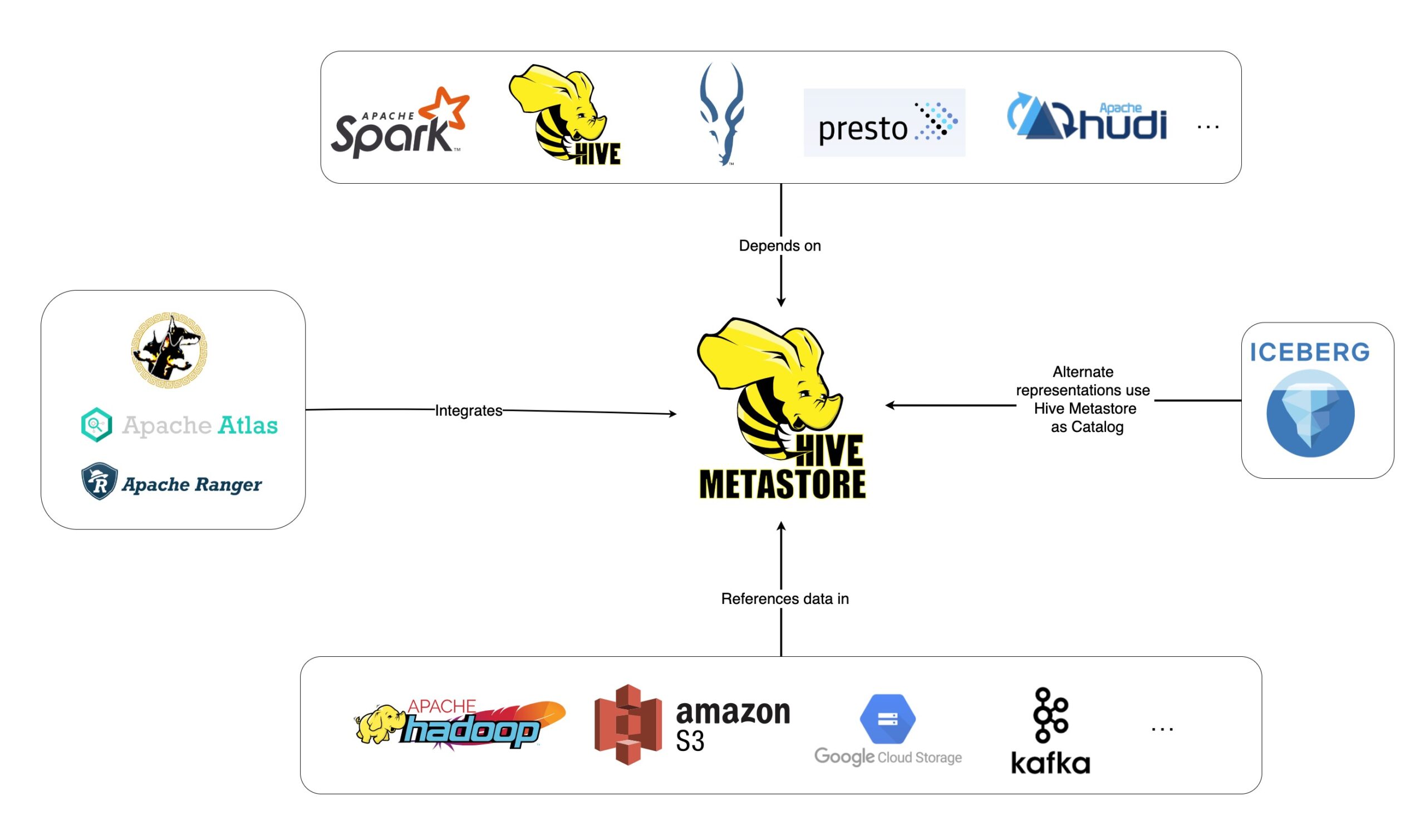
Apache Hive è una soluzione software di data warehousing open source per interrogare e analizzare i dati archiviati all'interno di un sistema di archiviazione distribuito estremamente scalabile. È stato creato come progetto open source dalla Apache Software Foundation nel 2008. Apache Hive viene utilizzato principalmente per attività di gestione e analisi dei dati su set di dati di grandi dimensioni archiviati nel file system distribuito Hadoop (HDFS). Fornisce un'interfaccia simile a SQL per interrogare e gestire i dati archiviati in HDFS. Hive è basato su Hadoop e quindi fornisce un modo per interagire e gestire i dati archiviati in Hadoop. Hive è progettato per consentire un accesso ad hoc ed esplorativo ai dati fornendo un linguaggio simile a SQL, consentendo agli utenti di interrogare i propri dati.
Hive fornisce una serie di funzioni di elaborazione dati, inclusa la possibilità di unire, trasformare e riepilogare i dati su diversi sistemi di archiviazione. Fornisce un set completo di funzionalità come indicizzazione, partizionamento e bucket, consentendo agli utenti di caricare i propri dati in modo ottimale. Inoltre, Hive fornisce supporto per tipi di dati e metaprogrammazione, consentendo agli utenti di astrarre dati e scrivere attività di manipolazione dei dati in modo più intuitivo.
Apache Hive è noto anche per il suo ampio supporto per le UDF (funzioni definite dall'utente). Questa funzionalità consente agli utenti di creare le proprie UDF personalizzate per elaborare e analizzare i dati. Apache Hive è anche in grado di gestire e lavorare con dati in streaming e in tempo reale, rendendolo più adatto per applicazioni come Machine Learning e AI.
In conclusione, Apache Hive è un potente strumento per la gestione dei dati su un cluster Hadoop. La sua vasta libreria di funzioni e l'interfaccia simile a SQL consentono agli utenti di interrogare, analizzare e trasformare i dati in modo rapido ed efficiente. Apache Hive offre una piattaforma completa per lavorare con i Big Data, rendendolo uno strumento prezioso per sviluppatori e data scientist.
