



잠재 의미 분석(LSA)은 자연어 처리(NLP) 및 정보 검색(IR) 분야에서 사용되는 정보 처리 기술입니다. 벡터 공간 모델을 사용하여 텍스트 문서에 사용된 단어 간의 관계를 해독하려는 수학적 알고리즘입니다. LSA는 의미론적 관계를 보다 정확하게 이해하기 위해 다양한 문서에 있는 다양한 단어 간의 '잠재적' 또는 숨겨진 관계를 찾아내려고 시도합니다.
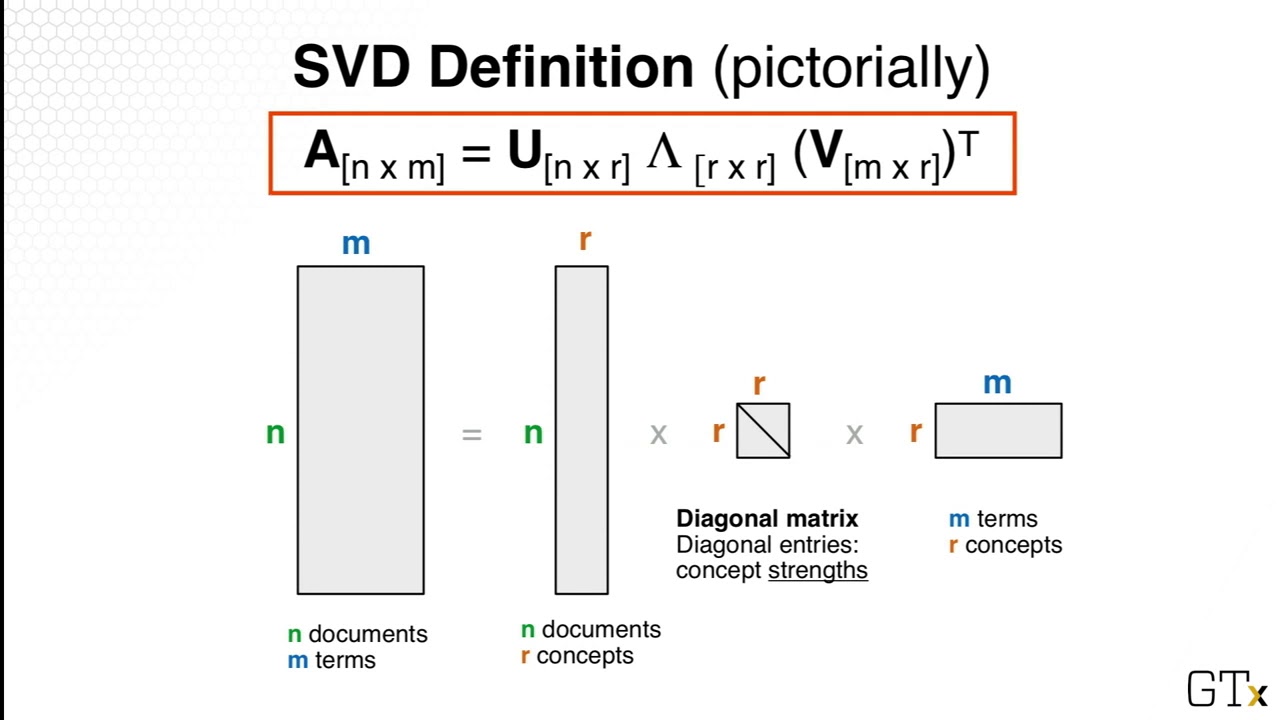
이는 1987년 캘리포니아 대학 버클리 대학의 Peter Landauer 교수와 그의 동료 John Daugman이 처음 제안한 것입니다. 기본 기술에는 값 행렬을 사용하여 문서에서 용어의 발생을 분석하는 것이 포함됩니다. 행렬 대수학 및 특이값 분해를 사용하여 원본 행렬의 차원을 줄이고 문서의 벡터 공간 모델을 생성합니다. 이 벡터 맵은 의미론적 관계를 식별할 수 있는 기초가 됩니다.
LSA는 웹 브라우저의 자동 완성 기능, Q&A 시스템, 문서 분류 등의 응용 분야에 사용되었습니다. 또한 특정 주제와 관련된 기사 및 문서를 찾는 데 유용한 도구입니다. 특정 응용 프로그램 중 하나는 검색 엔진 최적화입니다. LSA를 활용하면 검색 엔진 알고리즘이 수행 중인 특정 쿼리에 대한 쿼리 결과의 관련성을 더 잘 식별할 수 있습니다.
학술 분야에서 LSA는 교육 시스템의 학문적 지식을 식별하고, 텍스트 말뭉치의 숨겨진 추세를 식별하고, 표절을 탐지하는 데 사용됩니다. LSA는 또한 인간 인지 및 언어 이해의 중요한 측면을 식별하는 데 도움이 되는 심리학 연구에서도 사용되는 것으로 나타났습니다.
LSA는 잠재 의미 관계를 찾아내는 능력으로 인해 자연어 처리 및 정보 검색 작업을 위한 점점 더 널리 사용되는 도구가 되었습니다. 검색 엔진 최적화부터 학술 연구까지 응용 범위가 다양하므로 다양한 사용자에게 귀중한 도구입니다.
