



潜在语义分析(LSA)是一种用于自然语言处理(NLP)和信息检索(IR)领域的信息处理技术。它是一种数学算法,试图依靠向量空间模型来破译文本文档中使用的单词之间的关系。 LSA 试图揭示不同文档中各种单词之间的“潜在”或隐藏关系,以便更准确地理解语义关系。
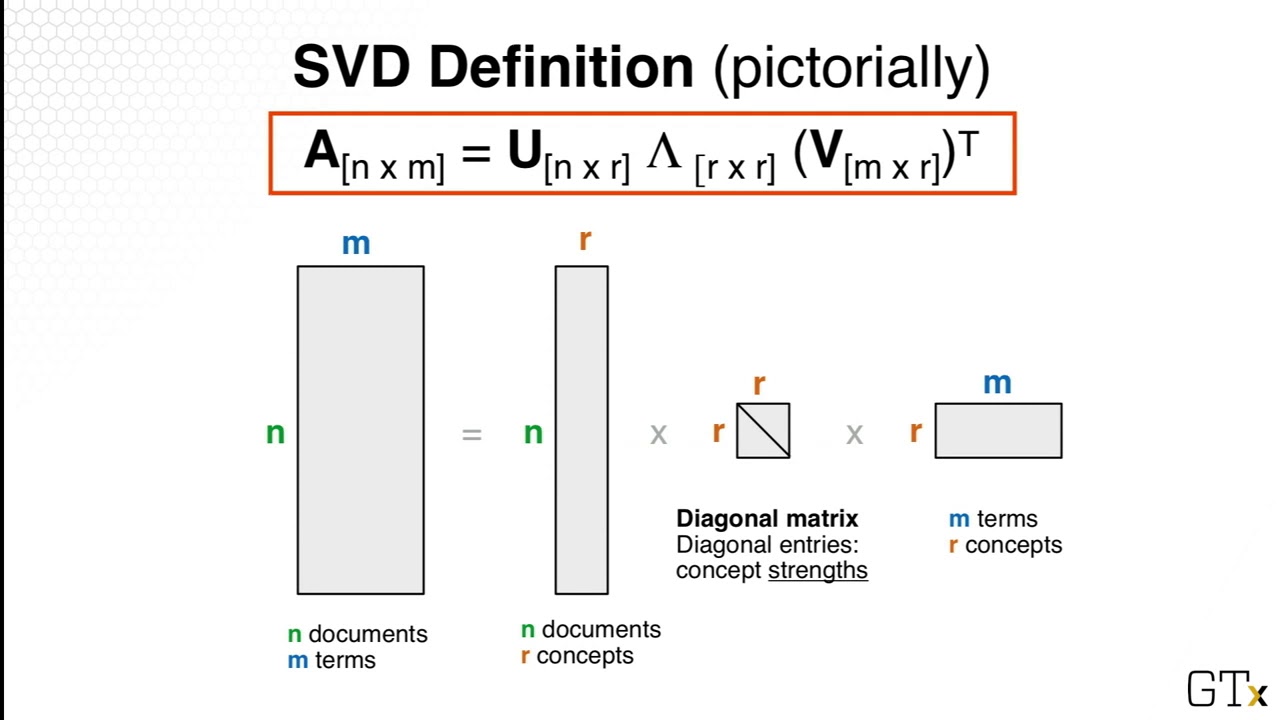
它由加州大学伯克利分校教授 Peter Landauer 和他的同事 John Daugman 于 1987 年首次提出。基本技术包括使用值矩阵分析文档中术语的出现情况。它采用矩阵代数和奇异值分解来降低原始矩阵的维数,创建文档的向量空间模型。然后,该向量图就成为识别语义关系的基础。
LSA 已用于 Web 浏览器中的自动完成功能、问答系统和文档分类等应用中。它也是查找与某些主题相关的文章和文档的有用工具。一种特殊的应用是搜索引擎优化:通过利用 LSA,搜索引擎算法可以更好地识别查询结果与正在执行的特定查询的相关性。
在学术领域,LSA 用于识别教育系统中的学科知识、识别文本语料库中隐藏的趋势以及检测抄袭。 LSA 还被用于心理学研究,以帮助识别人类认知和语言理解的重要方面。
由于其能够揭示潜在语义关系,LSA 已成为自然语言处理和信息检索任务中越来越流行的工具。其应用范围从搜索引擎优化到学术研究,使其成为各种用户的宝贵工具。
