



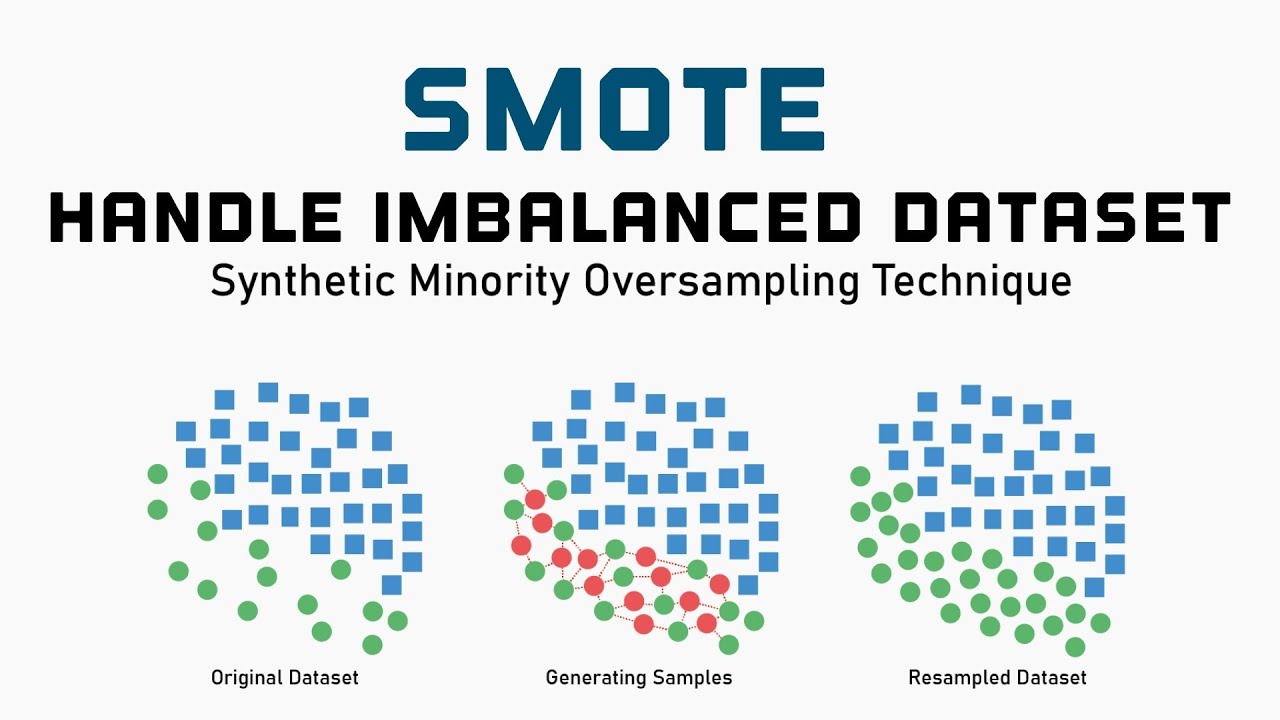
SMOTE(Synthetic Minority Over-sampling Technique)는 기계 학습의 데이터 밸런싱에 사용되는 오버샘플링 기술입니다. Chawla et al.에 의해 소개되었습니다. 2002년에 출시되었으며 종종 기계 학습을 위한 전처리 단계로 구현됩니다.
SMOTE의 주요 목표는 소수 클래스를 보다 균형 있게 표현하여 데이터 세트의 균형을 맞추는 것입니다. 이는 기존 소수 클래스 사이를 선형으로 보간하여 합성 데이터 포인트를 생성하여 훨씬 더 큰 소수 클래스 인스턴스 샘플을 생성하는 방식으로 작동합니다.
SMOTE는 다양한 시나리오에서 사용될 수 있습니다. 예를 들어 소수 클래스가 다수 클래스에 비해 불균형하게 나타나는 텍스트 분류 및 다중 클래스 분류 문제에 사용할 수 있습니다. 생체 인식, 사기 탐지, 의료 진단에도 유용합니다.
SMOTE 프로세스에는 특정 수의 소수 인스턴스를 무작위로 선택한 다음 각 소수 인스턴스에 대해 새로운 합성 데이터 포인트 생성에 사용할 이웃을 결정하는 작업이 포함됩니다. 새로운 데이터 포인트는 소수 인스턴스의 특징 벡터를 취하고 각 특징에 대한 가우스 분포에서 난수를 취하여 형성된 무작위 벡터를 추가하여 생성됩니다.
SMOTE는 불균형 데이터 문제를 처리하는 효율적이고 효과적인 기술로, 더 나은 학습과 더 정확한 모델을 가능하게 합니다. 그러나 오버샘플링으로 인해 모델이 지나치게 단순화되고 정확도가 낮아질 수 있으므로 다중 클래스 데이터 세트를 처리하는 데 적합하지 않을 수 있습니다. 또한 연구자들은 SMOTE에서 생성된 새로운 데이터 포인트를 분류하려고 할 때 어려움을 겪었습니다.
