



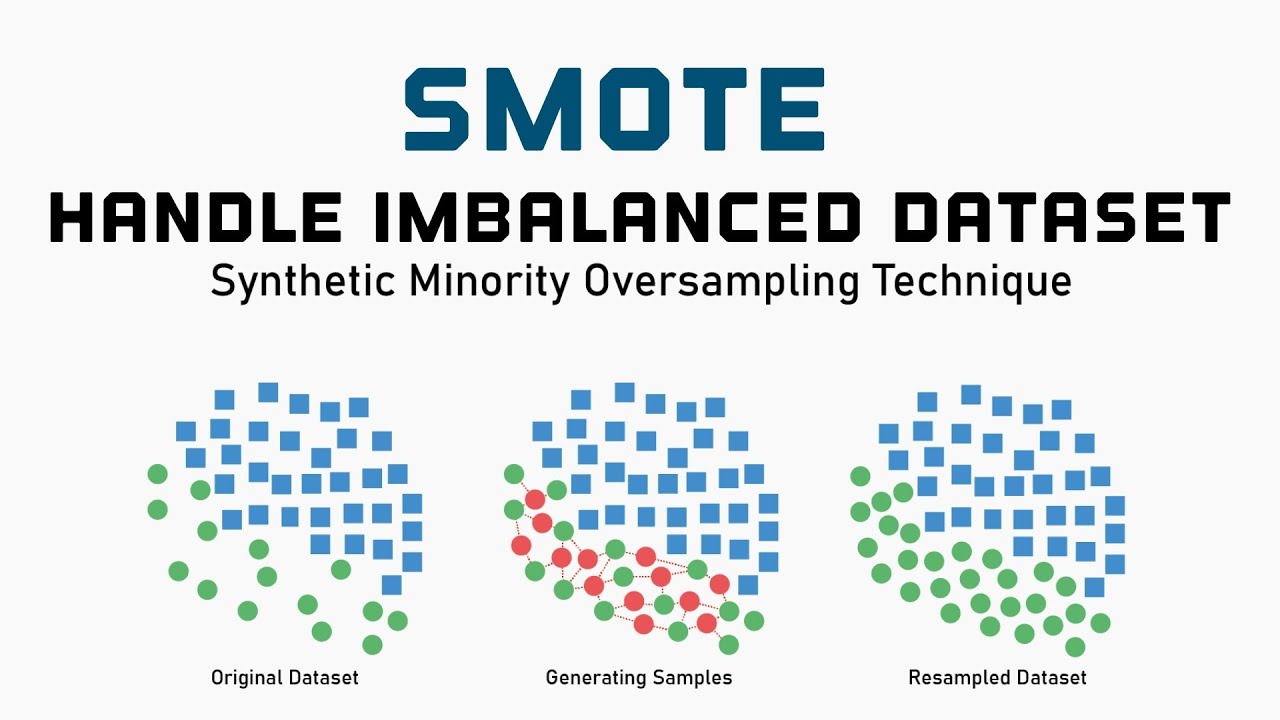
SMOTE (Synthetic Minority Over-sampling Technique) is an oversampling technique used in data balancing in machine learning. It was introduced by Chawla et al. in 2002, and is often implemented as a preprocessing step for machine learning.
The main aim of SMOTE is to balance datasets by providing a more balanced representation of minority classes. It works by generating synthetic data points by linearly interpolating between existing minority classes, creating a much larger sample of minority class instances.
SMOTE can be used in a variety of different scenarios. For example, it can be used in text categorization and multi-class classification problems, where the minority classes are disproportionately represented compared to the majority. It is also useful in biometrics, fraud detection and medical diagnosis.
The process of SMOTE involves selecting a certain number of minority instances randomly, and then, for each of those minority instances, decide on a neighbour to be used in the generation of new synthetic data points. The new data points are generated by taking the feature vector of the minority instance, and adding a random vector formed by taking a random number from a Gaussian distribution for each feature.
SMOTE is an efficient and effective technique for dealing with the imbalanced data problems, allowing for better learning and a more accurate model. However, it may not be ideal for dealing with multiclass datasets, as its oversampling may lead to oversimplified models and low accuracy. Additionally, researchers have struggled when trying to classify the new data points generated by SMOTE.
