



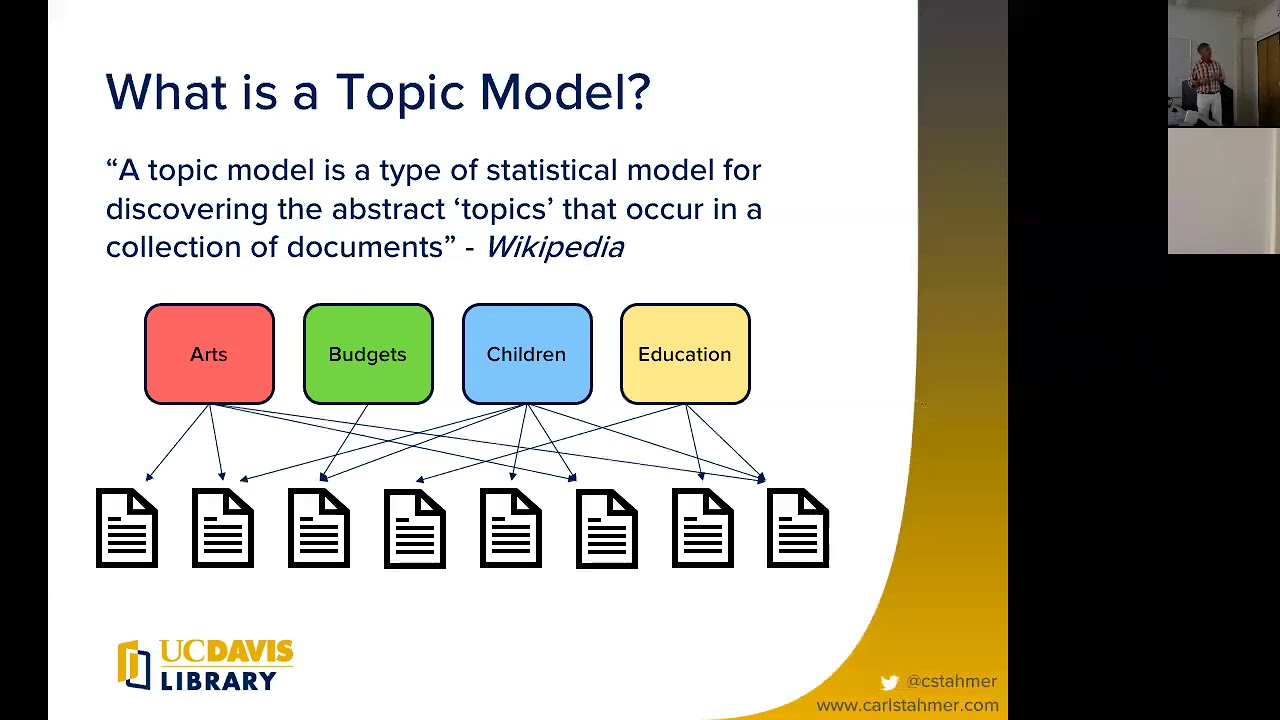
주제 모델링은 대규모 텍스트 데이터 세트의 숨겨진 구조를 밝히는 것을 목표로 하는 기계 학습에 사용되는 비지도 학습 기술입니다. 이는 문서 모음에 숨겨진 추상적인 주제를 발견하는 데 사용되는 통계 모델링의 한 유형입니다. 문서의 내용을 주제별로 묶어 기존의 키워드 추출보다 효과적으로 문서의 내용을 요약하는 데 사용됩니다.
주제 모델링은 텍스트 요약, 대규모 텍스트 데이터 세트의 추세 식별, 주제 식별과 같은 다양한 애플리케이션에 사용됩니다. 예측 모델의 정확도를 높이고 데이터의 구조를 이해하는 데 사용할 수 있습니다.
주제 모델링의 주요 목적은 문서를 문서에 자주 함께 나타나는 단어 클러스터를 나타내는 "주제"로 나누는 것입니다. 그런 다음 주제는 주제 벡터라고 하는 단어 분포로 표시되며, 이 벡터의 확률은 특정 주제에 속하는 단어의 확률을 정의합니다.
대부분의 경우 주제 모델링 프로세스를 시작하기 전에 주제 수를 지정해야 합니다. 그런 다음 소프트웨어는 각 단어에 할당된 주제 확률을 기반으로 각 문서에 주제를 할당합니다.
주제 모델링에 사용되는 가장 널리 사용되는 알고리즘 중 하나는 대규모 문서 모음에서 분류 구조를 학습하는 생성 모델인 LDA(Latent Dirichlet Allocation)입니다. 여러 주제를 표현하는 유연성과 효율성으로 인해 주제 모델링에 점점 더 인기가 높아지고 있습니다.
주제 모델링은 대량의 구조화되지 않은 데이터를 분석하고, 숨겨진 패턴을 발견하고, 해석 가능한 결과를 생성할 수 있으므로 데이터 과학자를 위한 강력한 도구입니다. 또한 텍스트를 이해하고 수동으로 요약하는 데 소요되는 시간을 줄여 데이터의 그래픽 표현을 더 쉽게 해석할 수 있습니다. 또한 토픽 모델링은 오디오, 이미지, 비디오 등 다양한 유형의 데이터에 적용할 수 있습니다.
