



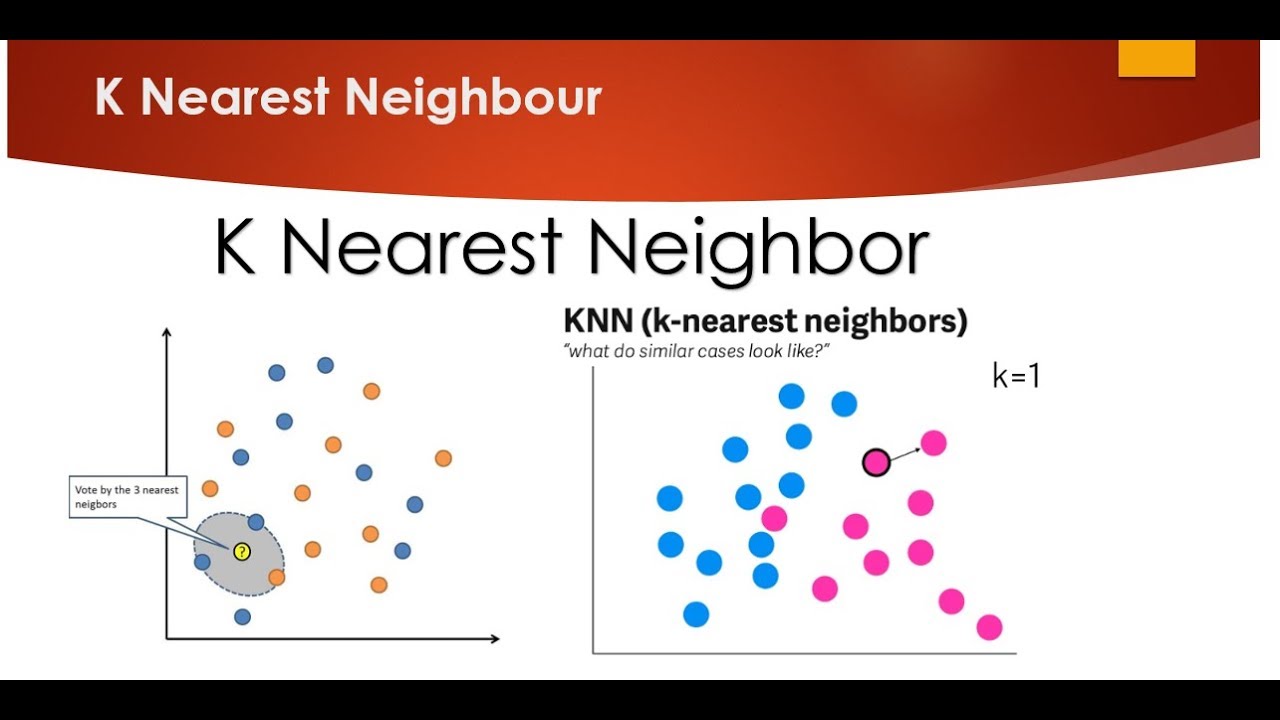
k-NN(K-Nearest Neighbors)은 기계 학습에 사용되는 알고리즘으로 데이터 과학에서 중요합니다. 이는 데이터 포인트의 가장 가까운 k-최근접 이웃을 보고 주어진 데이터 포인트의 클래스를 예측하는 것을 목표로 하는 인스턴스 기반 학습 아이디어를 기반으로 합니다.
알고리즘은 먼저 주어진 데이터 포인트와 각 k-최근접 이웃 사이의 거리를 측정하는 방식으로 작동하며, 이는 유클리드 거리와 같은 다양한 기술을 사용하여 수행할 수 있습니다. 거리가 계산된 후 알고리즘은 k개의 가장 가까운 이웃 데이터 포인트를 선택하고 대부분의 k-NN과 동일한 클래스 레이블을 사용하여 지정된 데이터 포인트를 분류합니다.
이 알고리즘의 장점은 이해하기 쉽고 계산 능력 측면에서 상당히 효율적이라는 것입니다. 또한 많은 교육이 필요하지 않으며 데이터를 사용하기 전에 특정 형식으로 가져올 필요도 없습니다.
그러나 k-NN 알고리즘에는 몇 가지 단점이 있습니다. 각 반복마다 주어진 데이터 포인트와 이웃 사이의 거리를 계산해야 하므로 대규모 데이터 세트를 처리하는 데 속도가 느려질 수 있습니다. 또한 k-NN은 예측이 가장 가까운 데이터 포인트에 크게 의존하기 때문에 훈련 데이터에 과적합되는 것으로 볼 수 있습니다.
요약하면 k-NN(k-Nearest Neighbors)은 기계 학습에서 널리 사용되는 간단하고 효과적인 알고리즘입니다. k-NN은 주어진 데이터 포인트와 k-가장 가까운 이웃 사이의 거리를 측정함으로써 이러한 이웃의 대다수 클래스를 기반으로 예측을 할 수 있습니다. 그러나 k-NN은 훈련 데이터에 과적합되기 쉽고 대규모 데이터세트에서는 속도가 느려질 수도 있습니다.
