



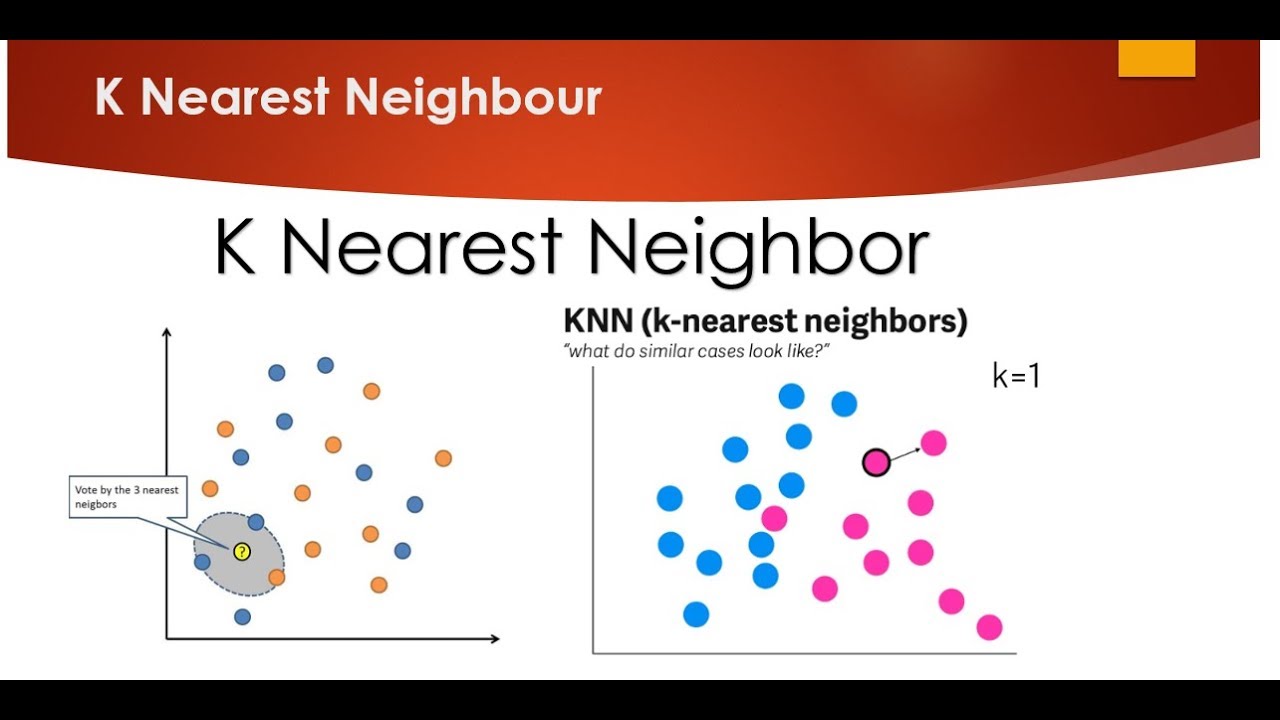
K-Nearest Neighbors (k-NN) adalah algoritma yang digunakan dalam pembelajaran mesin dan penting dalam ilmu data. Hal ini didasarkan pada ide pembelajaran berbasis instance, dengan tujuan memprediksi kelas dari suatu titik data tertentu dengan melihat k-tetangga terdekat dari titik data tersebut.
Algoritme ini bekerja dengan terlebih dahulu mengukur jarak antara titik data tertentu dan masing-masing k tetangga terdekatnya, yang dapat dilakukan dengan menggunakan berbagai teknik seperti jarak Euclidean. Setelah jarak dihitung, algoritma kemudian akan memilih k titik data tetangga terdekat dan mengklasifikasikan titik data tersebut dengan label kelas yang sama dengan mayoritas k-NN.
Kelebihan algoritma ini adalah mudah dipahami dan cukup efisien dalam hal daya komputasi. Hal ini juga tidak memerlukan banyak pelatihan dan data tidak perlu dibawa ke dalam bentuk tertentu sebelum dapat digunakan.
Namun, terdapat beberapa kelemahan pada algoritma k-NN. Memproses kumpulan data yang besar bisa jadi lambat, karena perlu menghitung jarak antara titik data tertentu dan tetangganya untuk setiap iterasi. Selain itu, k-NN terlihat overfit dengan data pelatihan karena prediksinya sangat bergantung pada titik data terdekat.
Singkatnya, k-Nearest Neighbors (k-NN) adalah algoritma sederhana dan efektif yang banyak digunakan dalam pembelajaran mesin. Dengan mengukur jarak antara titik data tertentu dan k-tetangga terdekatnya, k-NN mampu membuat prediksi berdasarkan kelas mayoritas dari tetangga tersebut. Namun, k-NN juga rentan mengalami overfitting pada data pelatihan dan lambat pada kumpulan data besar.
