



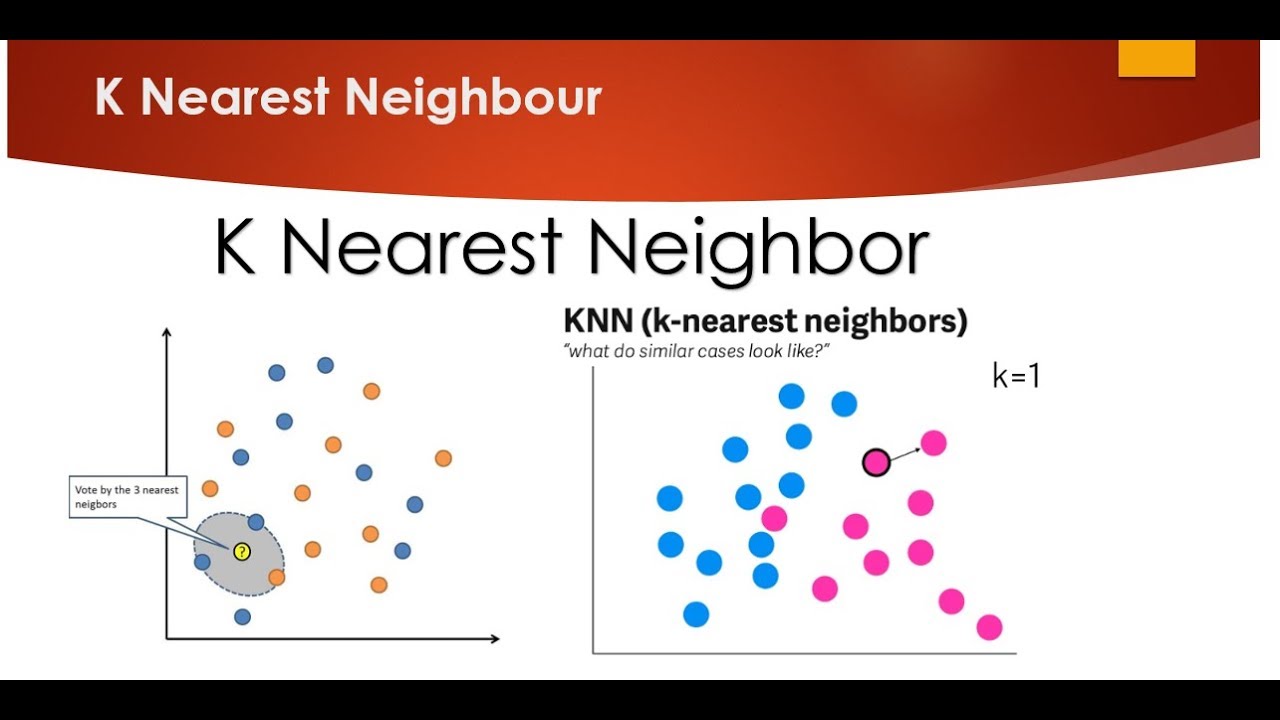
K-Nearest Neighbours (k-NN) is an algorithm used in machine learning and is important in data science. It is based off the idea of instance-based learning, with the goal of predicting the class of a given data point by looking at the closest k-nearest neighbours of the data point.
The algorithm works by first measuring the distance between the given data point and each of its k-nearest neighbours, which can be done using a variety of techniques such as the Euclidean distance. After the distances have been calculated, the algorithm will then select the k nearest neighbour data points and classify the given data point with the same class label as the majority of the k-NNs.
The advantage of this algorithm is that it is simple to understand and fairly efficient in terms of computational power. It also does not require a lot of training and the data does not need to be brought into any specific form before it can be used.
However, there are some drawbacks to the k-NN algorithm. It can be slow to process large datasets, as it needs to compute the distance between the given data point and its neighbours for each iteration. Additionally, the k-NN can be seen to overfit the training data as its predictions are heavily dependent on the closest data points.
In summary, k-Nearest Neighbours (k-NN) is a simple and effective algorithm that is widely used in machine learning. By measuring the distance between a given data point and its k-nearest neighbours, the k-NN is able to make predictions based on the majority class of these neighbours. However, the k-NN can also be prone to overfitting the training data and can be slow on large datasets.
