



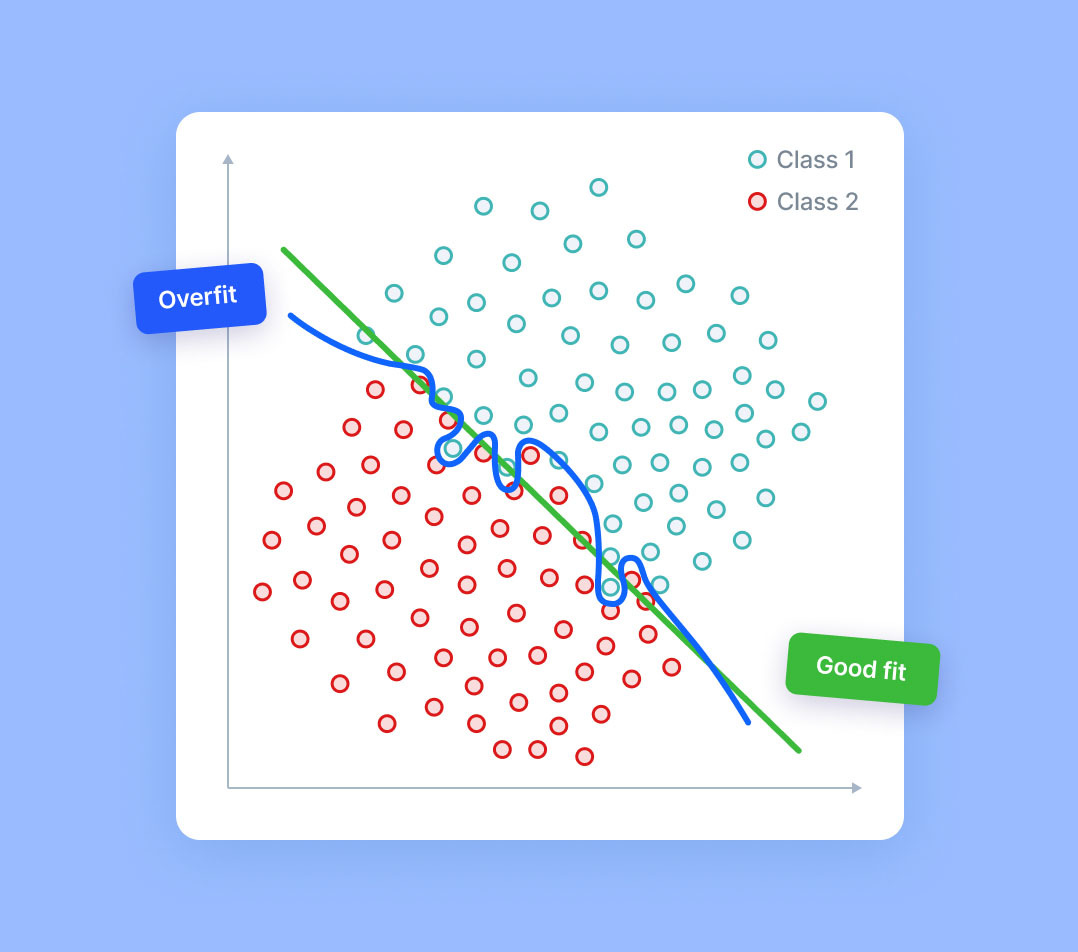
기계 학습의 과적합은 모델이나 알고리즘이 훈련 데이터에 너무 잘 맞아서 새 데이터에 대한 일반화에 실패하는 일반적인 현상입니다. 이는 데이터 양에 비해 매개변수나 기능이 너무 많아 모델이 너무 복잡할 때 발생합니다. 이는 기본 신호 대신 데이터의 노이즈를 설명하는 경향이 있어 훈련 데이터에서는 정확도가 높지만 보이지 않는 데이터에서는 성능이 저하됩니다.
과적합은 데이터의 기본 추세를 포착하지 못하는 모델이 지나치게 복잡하거나 사용 가능한 학습 데이터 양에 비해 기능이 너무 많은 등 다양한 요인으로 인해 발생할 수 있습니다. 또한 기능 간 다항식 또는 고차 관계가 있는 모델과 같이 너무 많은 유연성을 제공하는 모델을 사용하여 발생할 수도 있습니다. 과대적합은 특정 데이터 포인트에 지나치게 민감한 모델로 이어질 수 있으며, 따라서 향후 데이터로 일반화하지 못할 수 있습니다.
과적합을 방지하려면 의도적으로 특정 기능을 제거하거나 정규화 방법을 사용하여 모델 복잡성을 낮게 유지해야 합니다. 이러한 기술은 모델에 추가 편향을 유발할 수도 있지만 여전히 과적합보다 더 나을 수 있습니다. 교차 검증은 모델이 데이터에 과적합되기 시작하는 시기를 식별하는 데에도 사용할 수 있습니다. 모델의 정확성을 확인하는 데 사용할 수 있으므로 검증 세트를 교육 데이터와 별도로 유지하는 것이 중요합니다. 마지막으로 부스팅과 같은 앙상블 방법을 사용하여 과적합 가능성을 더욱 줄일 수 있습니다.
