



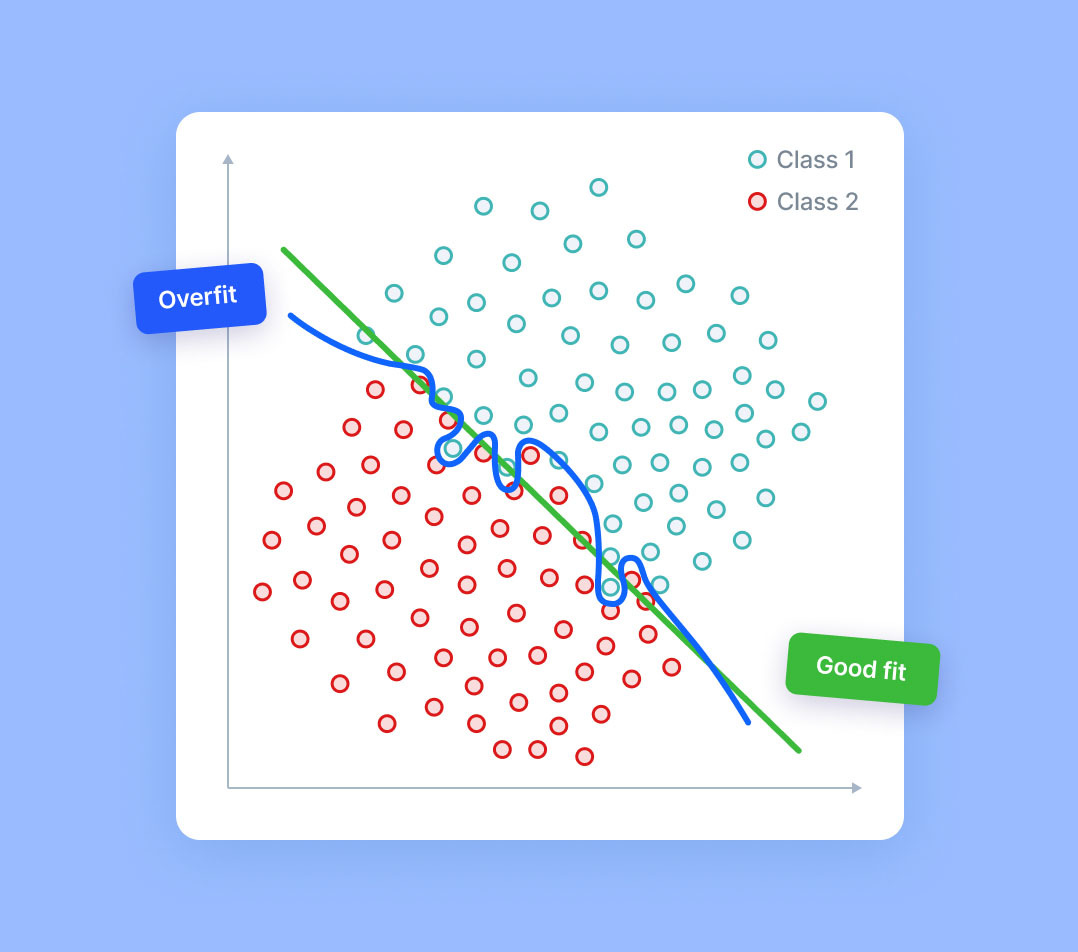
机器学习中的过度拟合是一种常见现象,其中模型或算法非常适合训练数据,以至于无法对新数据进行泛化。当模型过于复杂、相对于数据量而言参数或特征过多时,就会发生这种情况。它倾向于描述数据中的噪声而不是底层信号,导致训练数据的准确率很高,但对看不见的数据的性能较差。
过度拟合可能是由多种因素引起的,包括模型过于复杂,无法捕捉数据的潜在趋势,或者相对于可用训练数据量而言,特征过多。它还可能是由于使用提供过多灵活性的模型造成的,例如特征之间具有多项式或高阶关系的模型。过度拟合可能会导致模型对特定数据点过于敏感,从而无法推广到未来的数据。
为了防止过度拟合,有必要通过故意删除某些特征或使用正则化方法来保持较低的模型复杂性。此类技术还可能会给模型带来额外的偏差,但这仍然比过度拟合更好。交叉验证还可用于识别模型何时开始过度拟合数据。将验证集与训练数据分开非常重要,因为它可以用来验证模型的准确性。最后,可以采用增强等集成方法来进一步减少过度拟合的可能性。
