



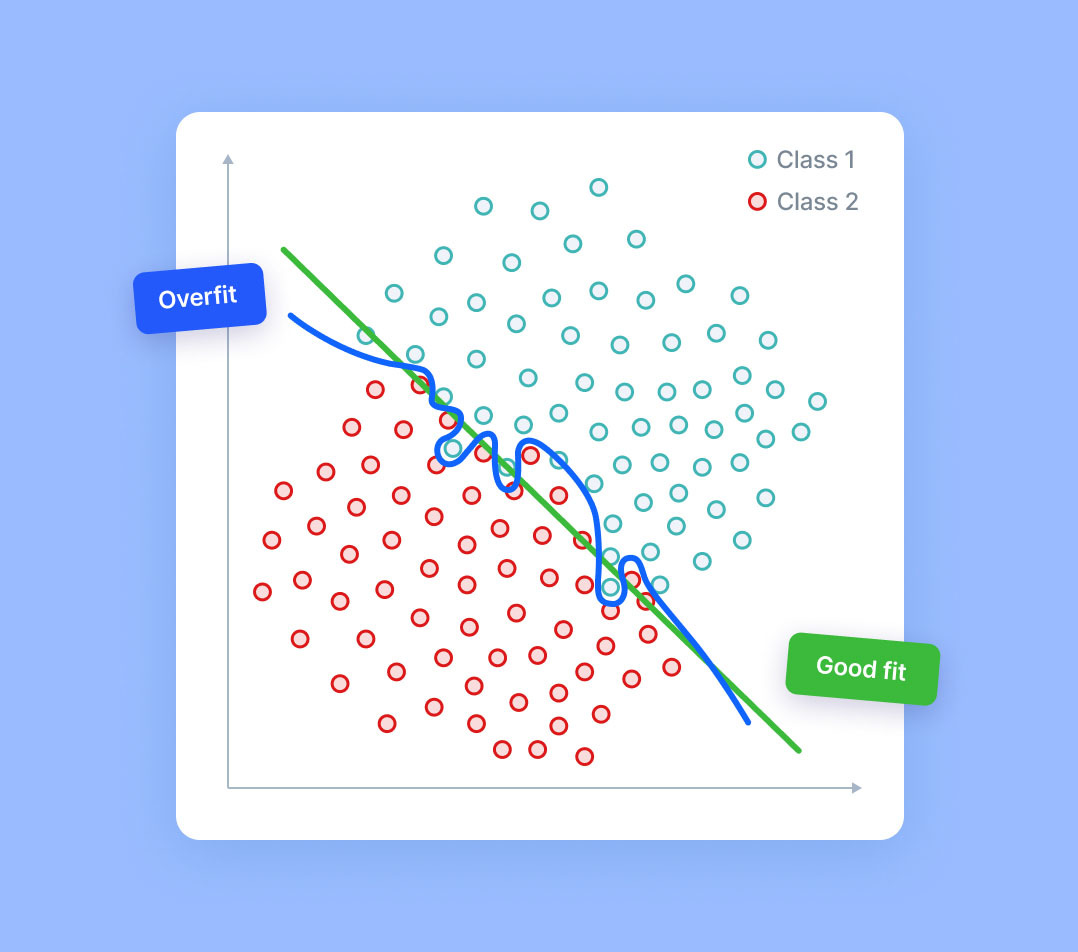
Overfitting in machine learning is a common phenomenon in which a model or algorithm fits the training data so well that it fails to generalize on new data. It occurs when a model is too complex, with too many parameters or features relative to the amount of data. It tends to describe the noise in the data instead of underlying signal, leading to high accuracy rates on training data but poor performance on unseen data.
Overfitting can be caused by a number of factors, including having overly complex models that do not capture the underlying trends in the data, or having too many features relative to the amount of training data available. It can also be caused by using models that provide too much flexibility, such as those with polynomial or higher-order relationships between features. Overfitting can lead to models that are overly sensitive to specific data points, and can thus fail to generalize to future data.
To prevent overfitting, it is necessary to keep the model complexity low by deliberately removing certain features or by using regularization methods. Such techniques can also introduce additional bias into the model, but this can still be preferable to overfitting. Cross validation can also be used to identify when a model begins to overfit the data. Keeping a validation set separate from the training data is important, as it can used to verify the model’s accuracy. Finally, ensemble methods such as boosting can be employed to further reduce the chances of overfitting.
