



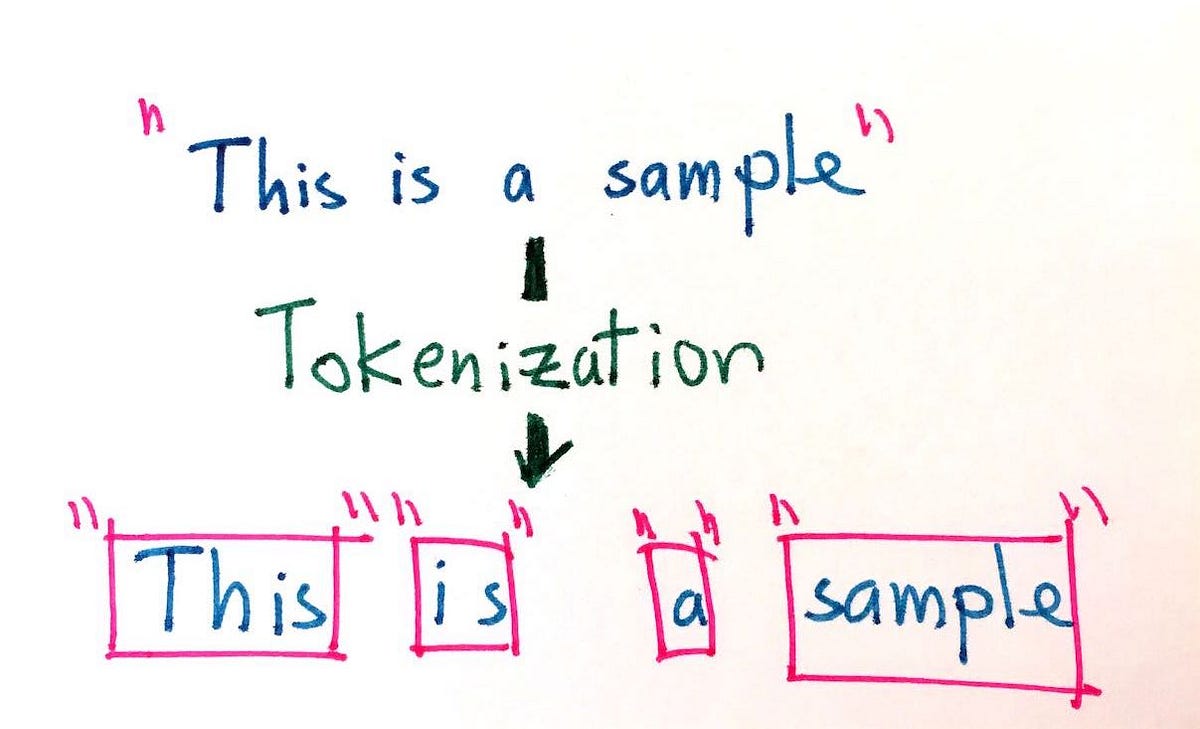
자연어 처리에서 토큰화는 텍스트를 단어, 구문 또는 토큰이라고 하는 기타 의미 있는 요소의 작은 그룹으로 나누는 프로세스입니다. 이는 감정 분석, 텍스트 요약, 기계 번역 등 많은 자연어 처리(NLP) 작업의 공통 구성 요소입니다. 일반적으로 토큰화에는 텍스트를 토큰으로 나눌 위치 결정, 특정 문자나 단어 제거, 일부 표준에 따라 결과 토큰 정규화(예: 모든 것을 소문자로 변환) 등 여러 단계가 포함됩니다.
토큰화는 많은 NLP 애플리케이션에서 필수적인 프로세스입니다. 왜냐하면 많은 경우 문장이나 문구의 의미는 단어가 나타나는 맥락에 따라 달라질 수 있기 때문입니다. 예를 들어, 문서에서 특정 문구를 찾을 때 의미를 적절하게 일치시키기 위해 텍스트를 작은 덩어리로 나누어야 할 수도 있습니다. 이것이 문서 검색 및 정보 추출에서 토큰화가 중요한 역할을 하는 이유입니다.
문장을 토큰화할 때 목표는 텍스트의 가장 작은 의미 있는 단위를 식별하는 것입니다. 이는 개별 단어만큼 작을 수도 있고 형태소(단어의 일부)일 수도 있습니다. 예를 들어, "read"라는 단어를 "read"(동사) 및 "er"(명사 접미사)로 토큰화하면 시스템이 단어 간의 어휘 관계 유형을 이해하는 데 도움이 될 수 있습니다.
토큰화는 추가 처리를 위해 특정 텍스트 부분을 분리하는 데에도 사용됩니다. 이는 핵심 문구나 이름과 같은 텍스트에서 중요한 정보를 추출하는 데 자주 사용됩니다. 또한 토큰화를 사용하여 텍스트의 패턴을 감지할 수 있습니다. 예를 들어, 문구 길이로 텍스트를 토큰화하면 특정 문장의 어조를 결정하는 데 사용할 수 있습니다.
텍스트의 개별 요소를 분리하는 것 외에도 토큰화를 사용하여 텍스트를 기계 학습 알고리즘에 더 쉽게 적용할 수 있도록 정규화할 수도 있습니다. 예를 들어 시스템이 소문자 단어만 인식하도록 훈련된 경우 토큰화를 통해 대문자와 소문자 단어를 모두 인식할 수 있습니다.
전반적으로 자연어 처리의 토큰화는 언어를 처리하고 이해하는 강력한 도구입니다. 텍스트를 더 작은 토큰이나 문구로 분할함으로써 시스템은 더 쉽게 관련 정보를 추출하고, 패턴을 감지하고, 텍스트를 정규화할 수 있습니다.
