



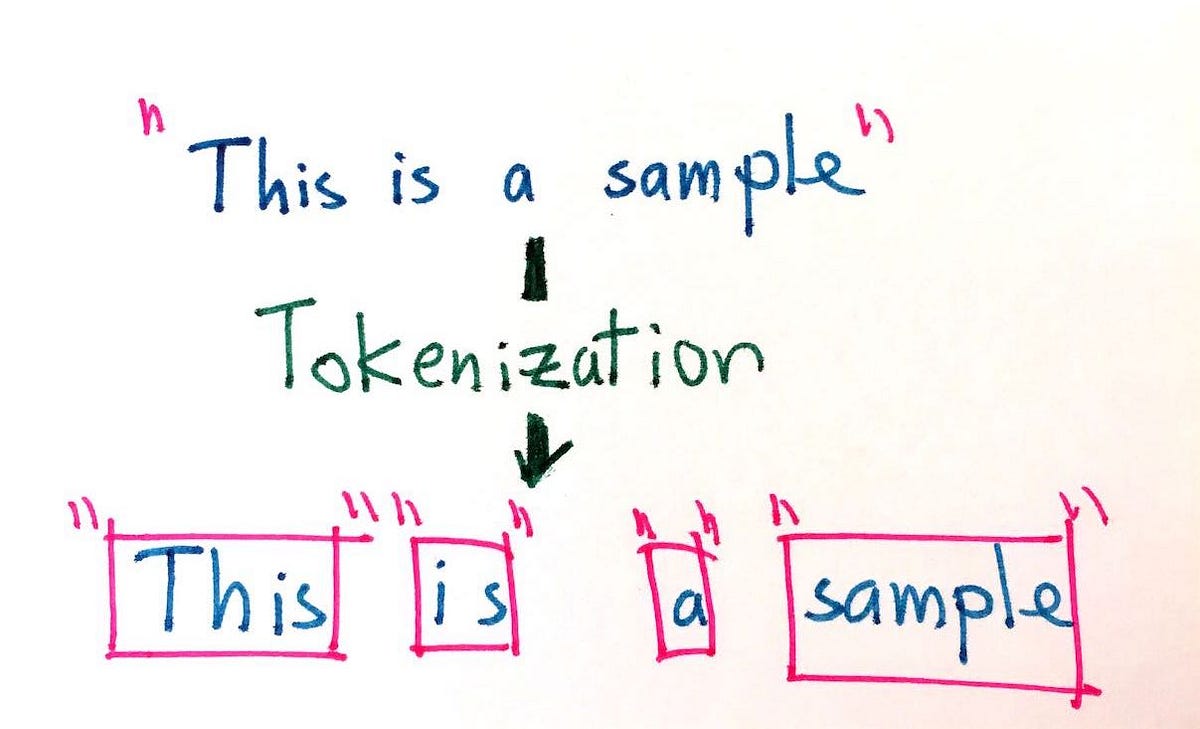
Tokenization in Natural Language Processing is the process of breaking a piece of text into smaller groups of words, phrases, or other meaningful elements called tokens. It is a common component of many natural language processing (NLP) tasks, such as sentiment analysis, text summarization, and machine translation. In general, tokenization involves several steps, including determining where to break the text into tokens, removing certain characters or words, and normalizing the resulting tokens according to some standard (such as transforming everything to lowercase).
Tokenization is an essential process in many NLP applications because, in many cases, the meaning of a sentence or phrase may depend on the context in which the words appear. For example, when looking for a particular phrase in a document, it may be necessary to break the text into small chunks to properly match the meaning. This is why tokenization plays an important role in document retrieval and information extraction.
When tokenizing a sentence, the goal is to identify the smallest meaningful units of the text. This can be as small as individual words or even just morphemes (parts of a word). For example, tokenizing the word “read” into “read” (a verb) and “er” (a noun suffix) can help the system understand the type of lexical relations between words.
Tokenization is also used to isolate specific pieces of text for further processing. This is often used to extract important information from the text, such as key phrases or names. Additionally, tokenization can be used to detect patterns in text. For example, by tokenizing text by phrase length, it can be used to determine the tone of a particular sentence.
In addition to isolating individual elements of text, tokenization can also be used to normalize the text in order to make it more amenable to machine learning algorithms. For example, if a system is trained to only recognize words in lowercase, tokenization would enable it to recognize both uppercase and lowercase words.
Overall, tokenization in natural language processing is a powerful tool for processing and understanding language. By breaking the text into smaller tokens or phrases, systems can more easily extract relevant information, detect patterns, and normalize the text.
