



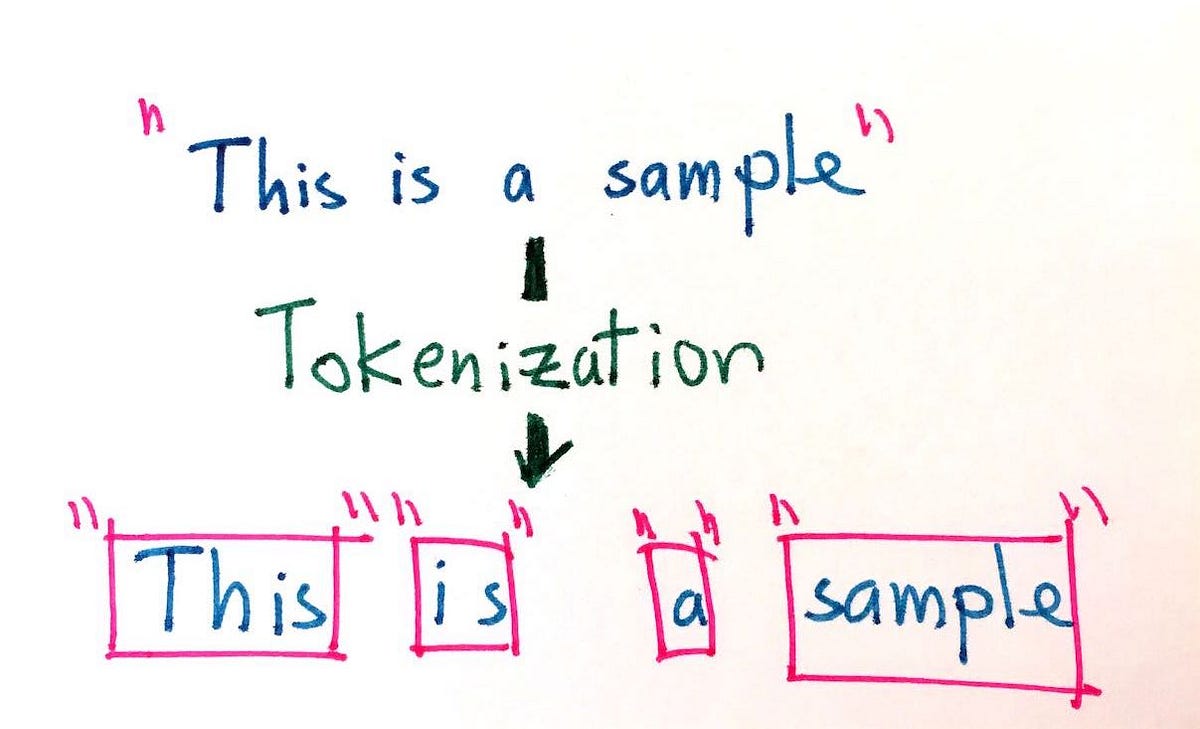
Tokenisasi dalam Natural Language Processing adalah proses memecah sepotong teks menjadi kelompok kata, frasa, atau elemen bermakna lainnya yang lebih kecil yang disebut token. Ini adalah komponen umum dari banyak tugas pemrosesan bahasa alami (NLP), seperti analisis sentimen, peringkasan teks, dan terjemahan mesin. Secara umum, tokenisasi melibatkan beberapa langkah, termasuk menentukan tempat memecah teks menjadi token, menghapus karakter atau kata tertentu, dan menormalkan token yang dihasilkan menurut beberapa standar (seperti mengubah semuanya menjadi huruf kecil).
Tokenisasi adalah proses penting dalam banyak aplikasi NLP karena, dalam banyak kasus, arti kalimat atau frasa mungkin bergantung pada konteks kemunculan kata tersebut. Misalnya, saat mencari frasa tertentu dalam dokumen, teks mungkin perlu dipecah menjadi potongan-potongan kecil agar sesuai dengan maknanya. Inilah sebabnya mengapa tokenisasi memainkan peran penting dalam pengambilan dokumen dan ekstraksi informasi.
Saat memberi token pada sebuah kalimat, tujuannya adalah untuk mengidentifikasi unit terkecil yang bermakna dari teks. Ini bisa berupa kata-kata individual atau bahkan hanya morfem (bagian dari sebuah kata). Misalnya, mengubah kata “read” menjadi “read” (kata kerja) dan “er” (akhiran kata benda) dapat membantu sistem memahami jenis hubungan leksikal antar kata.
Tokenisasi juga digunakan untuk mengisolasi bagian teks tertentu untuk diproses lebih lanjut. Ini sering digunakan untuk mengekstrak informasi penting dari teks, seperti frasa kunci atau nama. Selain itu, tokenisasi dapat digunakan untuk mendeteksi pola dalam teks. Misalnya, dengan memberi token pada teks berdasarkan panjang frasa, ini dapat digunakan untuk menentukan nada kalimat tertentu.
Selain mengisolasi elemen teks individual, tokenisasi juga dapat digunakan untuk menormalkan teks agar lebih sesuai dengan algoritma pembelajaran mesin. Misalnya, jika suatu sistem dilatih untuk hanya mengenali kata-kata dalam huruf kecil, tokenisasi akan memungkinkan sistem mengenali kata-kata dalam huruf besar dan kecil.
Secara keseluruhan, tokenisasi dalam pemrosesan bahasa alami adalah alat yang ampuh untuk memproses dan memahami bahasa. Dengan memecah teks menjadi token atau frasa yang lebih kecil, sistem dapat lebih mudah mengekstrak informasi yang relevan, mendeteksi pola, dan menormalkan teks.
