



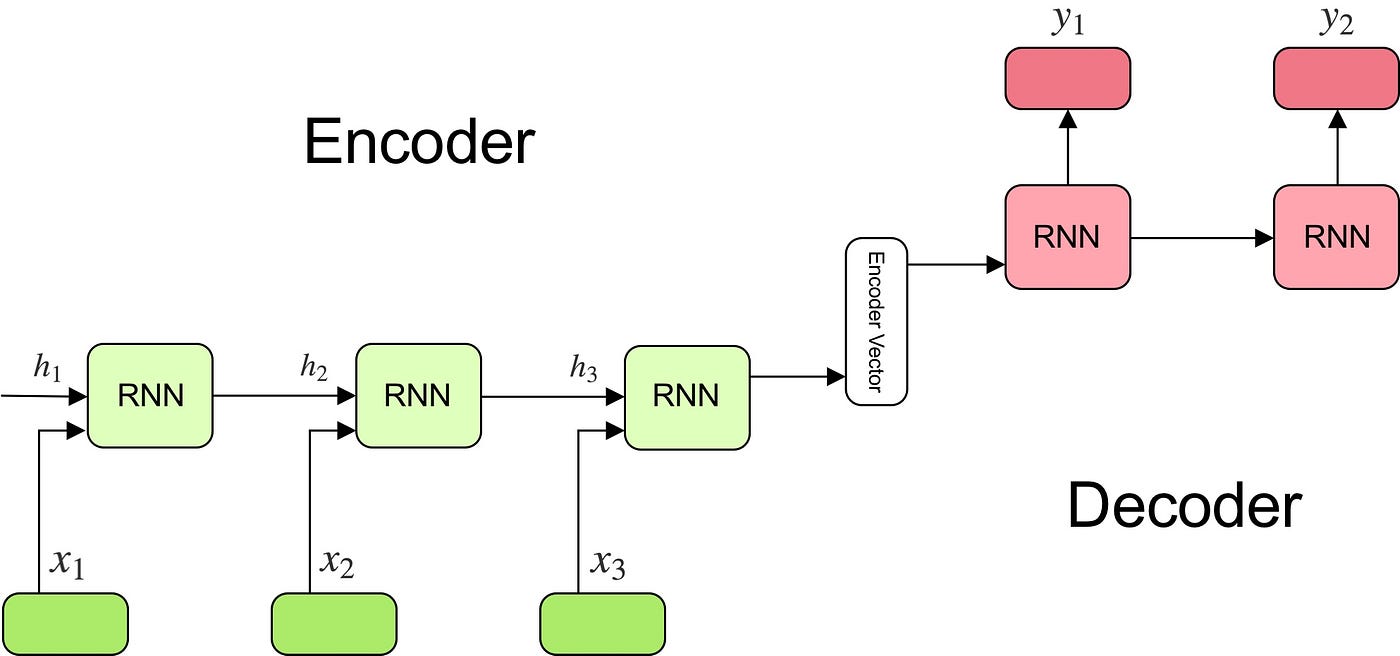
I modelli Sequence-to-Sequence (Seq2Seq) sono un tipo di reti neurali artificiali utilizzate per attività quali l'elaborazione del linguaggio naturale, la traduzione automatica e i sistemi conversazionali. I modelli Seq2Seq consentono a una macchina di apprendere da una serie di sequenze di input e di emettere una serie di sequenze di risposta.
Il modello Seq2Seq è tipicamente costituito da un “codificatore” e un “decodificatore”. Il codificatore accetta una sequenza di simboli in ingresso e restituisce una rappresentazione normalizzata dell'intera sequenza. Questa rappresentazione normalizzata viene quindi inserita nel decodificatore, che prende i dati normalizzati e restituisce una sequenza di simboli di output.
Il vantaggio principale dei modelli Seq2Seq è che non è necessario che la sequenza di output e la sequenza di input abbiano la stessa lunghezza. Ciò consente a un modello Seq2Seq di gestire attività complesse come la traduzione di testo da una lingua a un'altra o la generazione di una risposta a una frase di input.
I modelli Seq2Seq hanno trovato molte applicazioni nella traduzione automatica, nell'elaborazione del linguaggio naturale, nel riconoscimento vocale, nei sistemi di dialogo e molto altro. Recentemente, Seq2Seq è stato utilizzato anche nel campo della visione artificiale, consentendo a una macchina di “comprendere” un’immagine e generare una risposta adeguata.
I modelli Seq2Seq offrono un modo intuitivo per affrontare molte attività di machine learning che non possono essere facilmente risolte con i tradizionali approcci di apprendimento supervisionato o non supervisionato. I modelli Seq2Seq hanno anche il vantaggio di poter essere addestrati su set di dati relativamente piccoli.
