



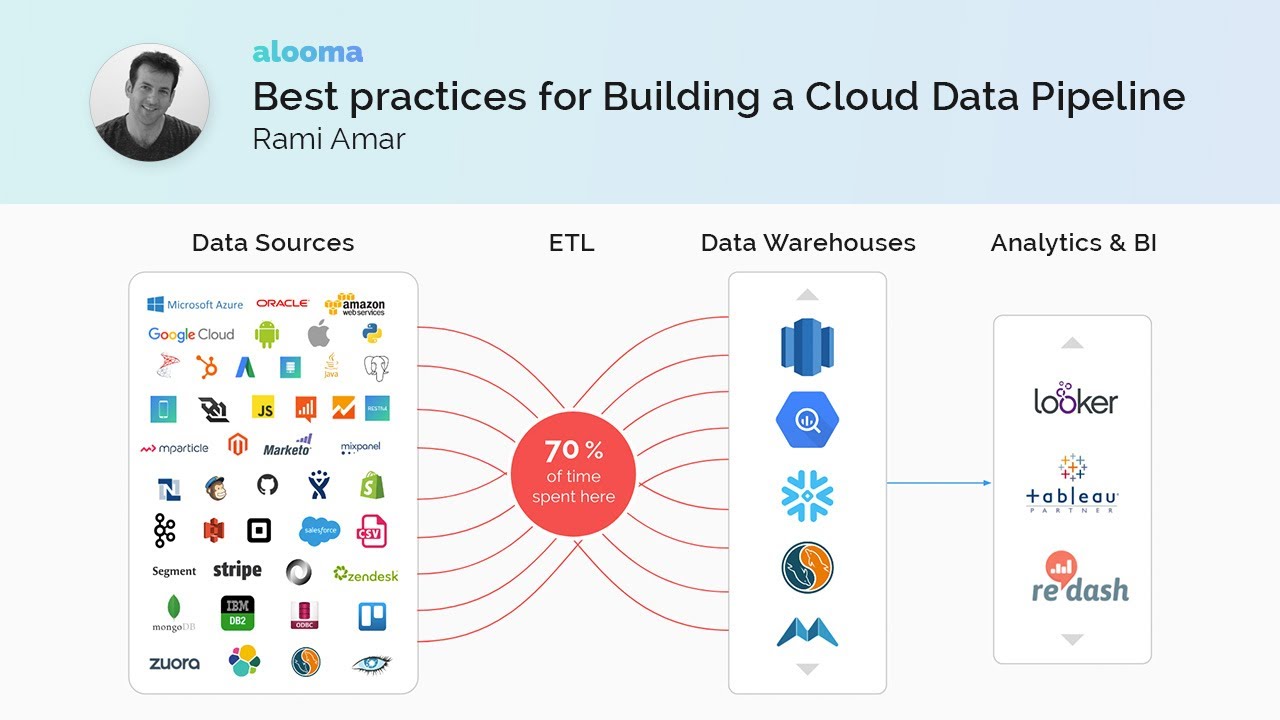
データ パイプラインとは、抽出、変換、読み込み (ETL)、データ管理、データ分析などのデータ処理タスクに使用されるテクノロジを指します。これらは、1 つ以上のソースからデータを抽出し、ユーザーの要件に従ってデータを処理し、後の処理または分析のためにターゲット ストレージにデータを非同期的にロードするために使用されます。
データ パイプラインは、あるソースから別のソースにデータを移動する自動化された方法を提供し、ユーザーが最小限の労力で膨大な量の情報を迅速に転送できるようにします。これらは、データ ウェアハウス、データ レイク、ビッグ データ プロジェクトなどのアプリケーションでよく使用されます。これらのアプリケーションでは、データを複数のソースから収集し、下流システムで読み取り可能な形式に変換する必要があります。
データ パイプラインでは、通常、メッセージ キュー (MQ) システムまたは抽出、変換、ロード (ETL) システムが使用されます。 MQ システムはキューを利用してソースからデータを取り込み、それを下流にフィードします。この方法により、大量のデータをリアルタイムでストリーミングできます。 ETL システムでは、さまざまなソースからデータを取得でき、ターゲット ストレージにロードする前に、ユーザー定義のルールに従ってデータをさらに変換できます。
データ パイプラインを使用すると、データ駆動型プロジェクトのパフォーマンスとスケーラビリティを向上させることができます。これらは、ポイント A からポイント B にデータを転送するための費用対効果が高く、安全で信頼性の高い方法を提供します。さらに、データ パイプラインは、システムを通過するすべてのデータに関連付けられたメタデータを追跡するのに役立ち、ユーザーが簡単に分析して理解できるようになります。データ。
全体として、データ パイプラインはデータ エンジニアリング プロジェクトの重要な部分です。これらは、データ フローの複雑さを軽減し、データの整合性を確保し、スケーラビリティを提供するのに役立ちます。さらに、より高速なデータ転送とより効率的なデータ分析が可能になるため、データ分析の効率が向上します。
