



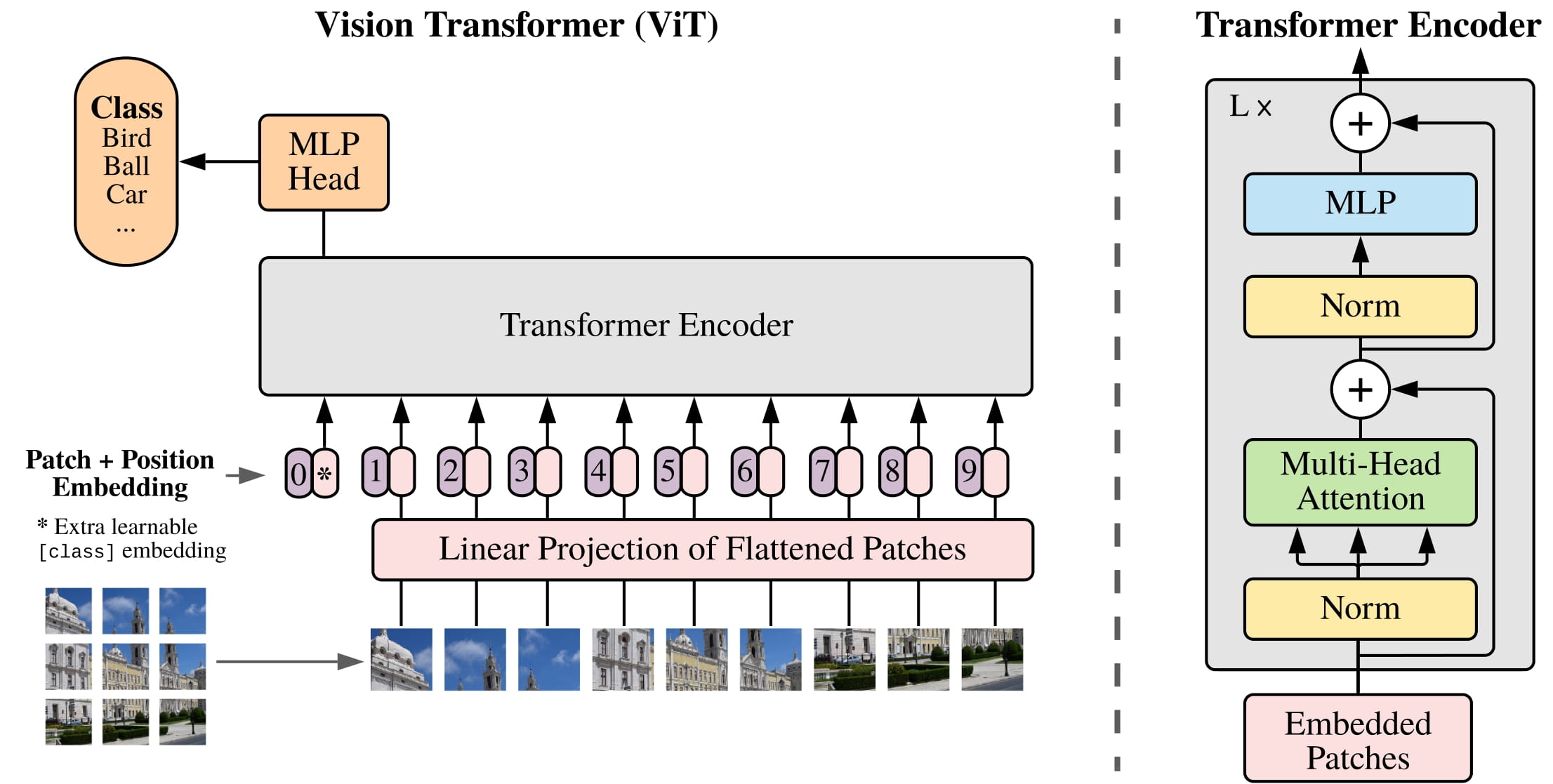
ViT (Vision Transformer) は、コンピューター ビジョン タスク用に開発された新しい人工ニューラル ネットワーク アーキテクチャです。このアーキテクチャは、2020 年 10 月に Google Research の研究者によって提案されました。これは、畳み込みニューラル ネットワーク (CNN) やその他のトランスフォーマー ベースのモデルなどの既存のアーキテクチャを改良したもので、高解像度の画像サイズに効率的にスケーリングできます。
このアーキテクチャは、(1) ビジョン トランスフォーマー (ViT) と (2) トークン埋め込みの 2 つのコンポーネントで構成されます。ビジョン トランスフォーマーは、固定された手作りのフィルターを使用する CNN とは対照的に、ネットワークが画像のさまざまな部分の表現を学習できるようにするアテンション メカニズムを使用します。アテンション メカニズムは、多数のパラメーターの必要性を排除するのにも役立ち、ViT が標準の CNN よりも高速かつ効率的にトレーニングできるようになります。
2 番目のコンポーネントであるトークン埋め込みは、画像データを圧縮形式で表現するために使用されます。 「トークン」は画像内のデータポイントです。トークン埋め込みを使用してこのデータを低次元空間に埋め込み、ViT が高解像度画像を処理できるようにします。
ViT は、画像分類、物体検出、インスタンスのセグメンテーションなど、さまざまな視覚タスクで高精度を達成できます。自然言語処理などのタスクにも使用できるため、コンピューター ビジョンと自然言語処理 (NLP) の両方にとって強力な追加機能となります。
ViT アーキテクチャはコンピューター ビジョンと NLP タスクに革命をもたらし、より高い精度でより効率的なトレーニング時間を可能にしました。多くの企業や団体でさまざまな用途に採用されています。いくつかの例には、Amazon の DeepRacer や NVIDIA の RTX GPU などがあります。
