



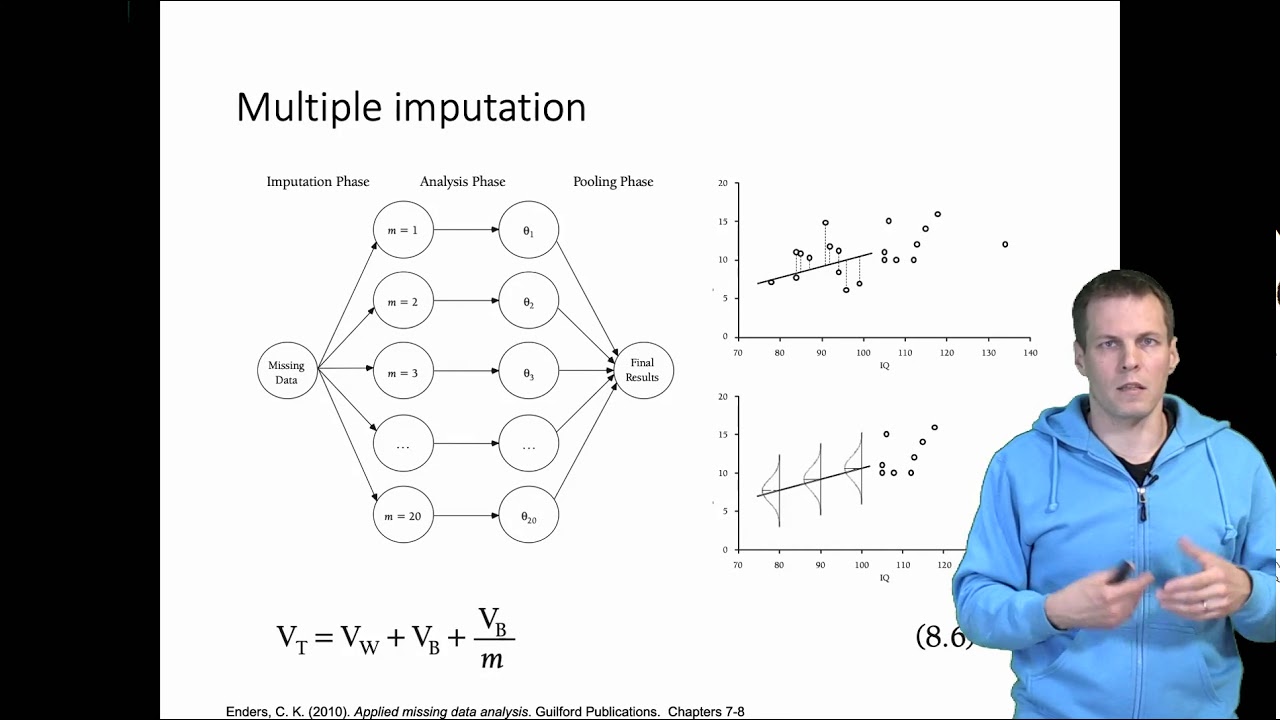
데이터 대체는 일반적으로 데이터 세트 내에서 누락된 값을 채우는 프로세스입니다. 데이터 분석 및 기계 학습에 사용되는 일반적인 데이터 정리 기술입니다. 데이터 대치는 합리적인 추정치로 누락된 값을 채워 데이터를 더 잘 이해하는 데 도움이 될 수 있습니다.
평균, 중앙값, 모드, k-최근접 이웃, 선형 회귀 등을 포함한 여러 가지 데이터 대치 기술이 있습니다.
평균 대체는 기존 값의 평균 또는 평균으로 결측값을 채우는 간단한 방법입니다. 이는 일반적으로 유효한 값의 평균을 계산한 다음 누락된 값을 해당 계산으로 대체하여 수행됩니다.
중앙값 대체는 평균 대체와 유사하지만 평균 대신 중앙값을 사용하여 누락된 값을 대체합니다. 이 경우 기존 값의 중앙값을 결정한 다음 이 값을 사용하여 누락된 값을 채웁니다.
모드 대체는 모드 또는 가장 빈번한 값을 사용하여 누락된 값을 채우는 다른 데이터 대체 방법입니다.
KNN(K-Nearest Neighbors)은 데이터 대치에 자주 사용되는 기계 학습 알고리즘입니다. 이 알고리즘은 누락된 값에 대한 k-최근접 이웃을 살펴본 다음 이러한 점의 평균을 취해 누락된 값을 대체합니다.
선형 회귀는 기존 데이터에 선형 모델을 맞추는 방식으로 작동하는 또 다른 데이터 대치 기술입니다. 그러면 모델의 계수를 기반으로 결측값이 예측됩니다.
데이터 대체는 데이터 분석 및 기계 학습의 중요한 단계이므로 신중하게 사용해야 합니다. 데이터에 대한 올바른 대치 방법을 결정하고 데이터세트의 과적합이나 편향을 방지하기 위해 주의를 기울이는 것이 중요합니다.
