



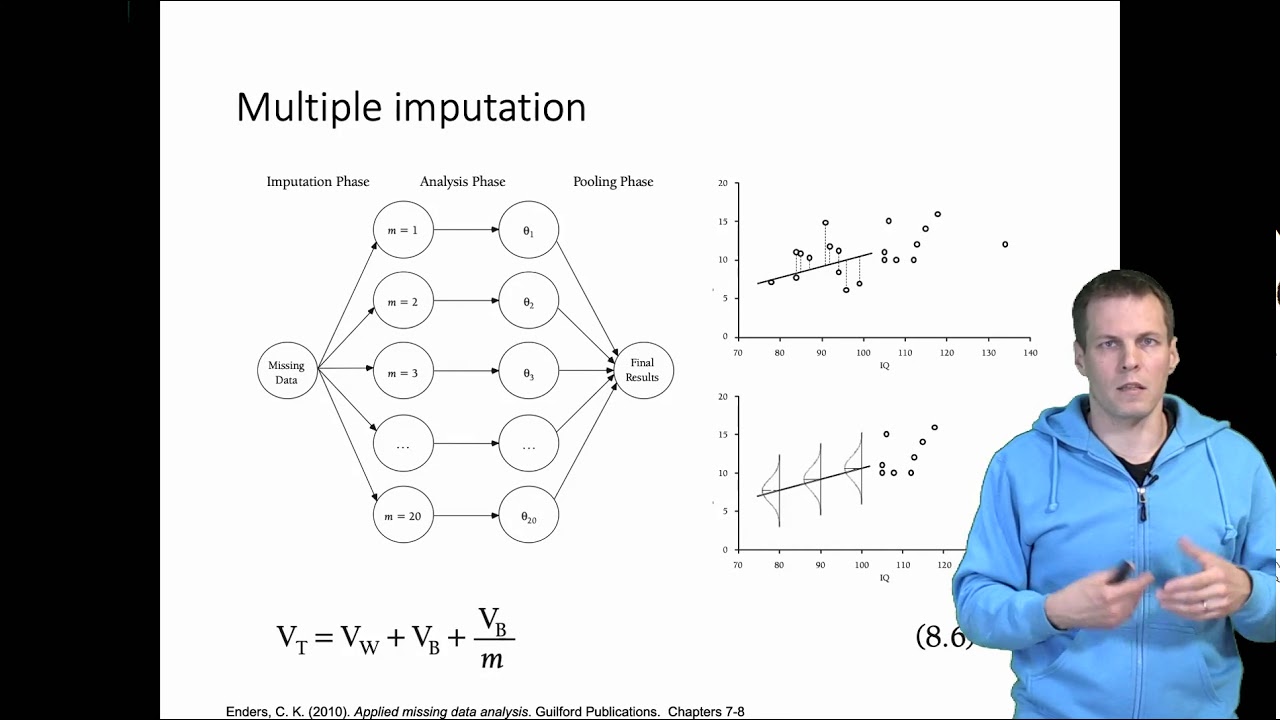
Data imputation is a process of filling in missing values, usually within a dataset. It is a common data cleaning technique used in data analysis and machine learning. Data imputation can help produce a better understanding of the data by filling in the missing values with sensible estimates.
There are several different data imputation techniques, including mean, median, mode, k-nearest neighbors, linear regression, and more.
Mean imputation is a simple method of filling in missing values with the mean or average of the existing values. This is generally done by computing the mean of the valid values and then replacing the missing values with that computation.
Median imputation is similar to mean imputation, but the median instead of the mean is used to replace missing values. In this case, the median of the existing values is determined and then this value is used to fill in the missing values.
Mode imputation is a different data imputation method where the mode or most frequent value is used to fill in the missing values.
K-nearest neighbors (KNN) is a machine learning algorithm that is often used in data imputation. This algorithm looks at the k-nearest neighbors to the missing values and then takes the average of these points to replace the missing values.
Linear regression is another data imputation technique that works by fitting a linear model to the existing data. The missing values are then predicted based on the coefficients in the model.
Data imputation is an important step in data analysis and machine learning and should be used judiciously. It is important to decide on the right imputation methods for your data and use caution to avoid overfitting or biasing the dataset.
