



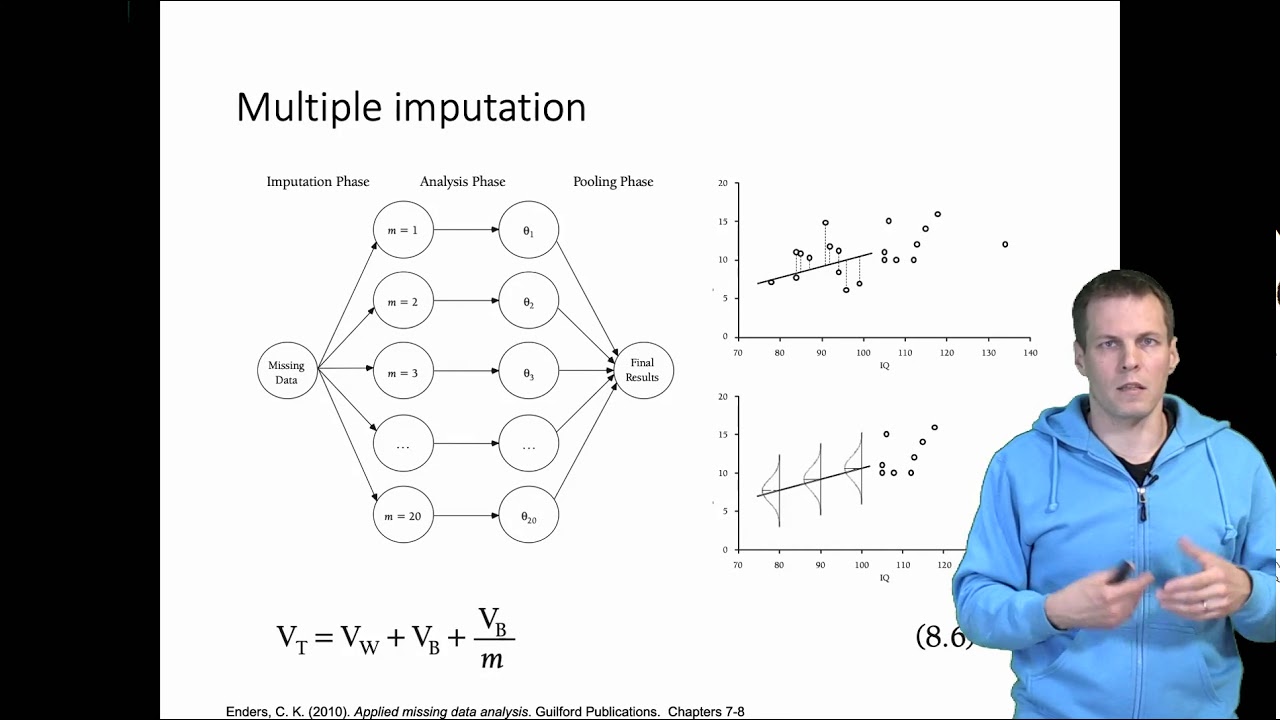
A imputação de dados é um processo de preenchimento de valores ausentes, geralmente dentro de um conjunto de dados. É uma técnica comum de limpeza de dados usada em análise de dados e aprendizado de máquina. A imputação de dados pode ajudar a produzir uma melhor compreensão dos dados, preenchendo os valores faltantes com estimativas sensatas.
Existem várias técnicas diferentes de imputação de dados, incluindo média, mediana, moda, k-vizinhos mais próximos, regressão linear e muito mais.
A imputação de média é um método simples de preencher valores faltantes com a média ou média dos valores existentes. Isso geralmente é feito calculando a média dos valores válidos e, em seguida, substituindo os valores ausentes por esse cálculo.
A imputação da mediana é semelhante à imputação da média, mas a mediana em vez da média é usada para substituir os valores ausentes. Neste caso, a mediana dos valores existentes é determinada e então este valor é utilizado para preencher os valores faltantes.
A imputação de modo é um método de imputação de dados diferente onde a moda ou o valor mais frequente é usado para preencher os valores ausentes.
K-vizinhos mais próximos (KNN) é um algoritmo de aprendizado de máquina frequentemente usado na imputação de dados. Este algoritmo analisa os k vizinhos mais próximos dos valores ausentes e, em seguida, calcula a média desses pontos para substituir os valores ausentes.
A regressão linear é outra técnica de imputação de dados que funciona ajustando um modelo linear aos dados existentes. Os valores ausentes são então previstos com base nos coeficientes do modelo.
A imputação de dados é uma etapa importante na análise de dados e no aprendizado de máquina e deve ser usada criteriosamente. É importante decidir sobre os métodos de imputação corretos para seus dados e ter cuidado para evitar ajuste excessivo ou enviesamento do conjunto de dados.
