



Model Bahasa Besar adalah jenis model pembelajaran mendalam yang digunakan untuk mendukung aplikasi pemrosesan bahasa alami (NLP). Mereka didasarkan pada arsitektur jaringan saraf yang dalam dan dilatih pada kumpulan data besar berupa teks berlabel atau tidak berlabel.
Salah satu manfaat model ini adalah mereka dapat mempelajari berbagai pola penggunaan bahasa dan dapat dilatih untuk menghasilkan keluaran yang bermakna atau mengklasifikasikan data. Model seperti model sequence-to-sequence proyek Google Brain atau OpenAI GPT-3 dapat digunakan untuk menghasilkan keluaran suara untuk tugas pemrosesan bahasa alami seperti sistem dialog, menjawab pertanyaan, pemahaman bahasa alami, dan pembuatan teks.
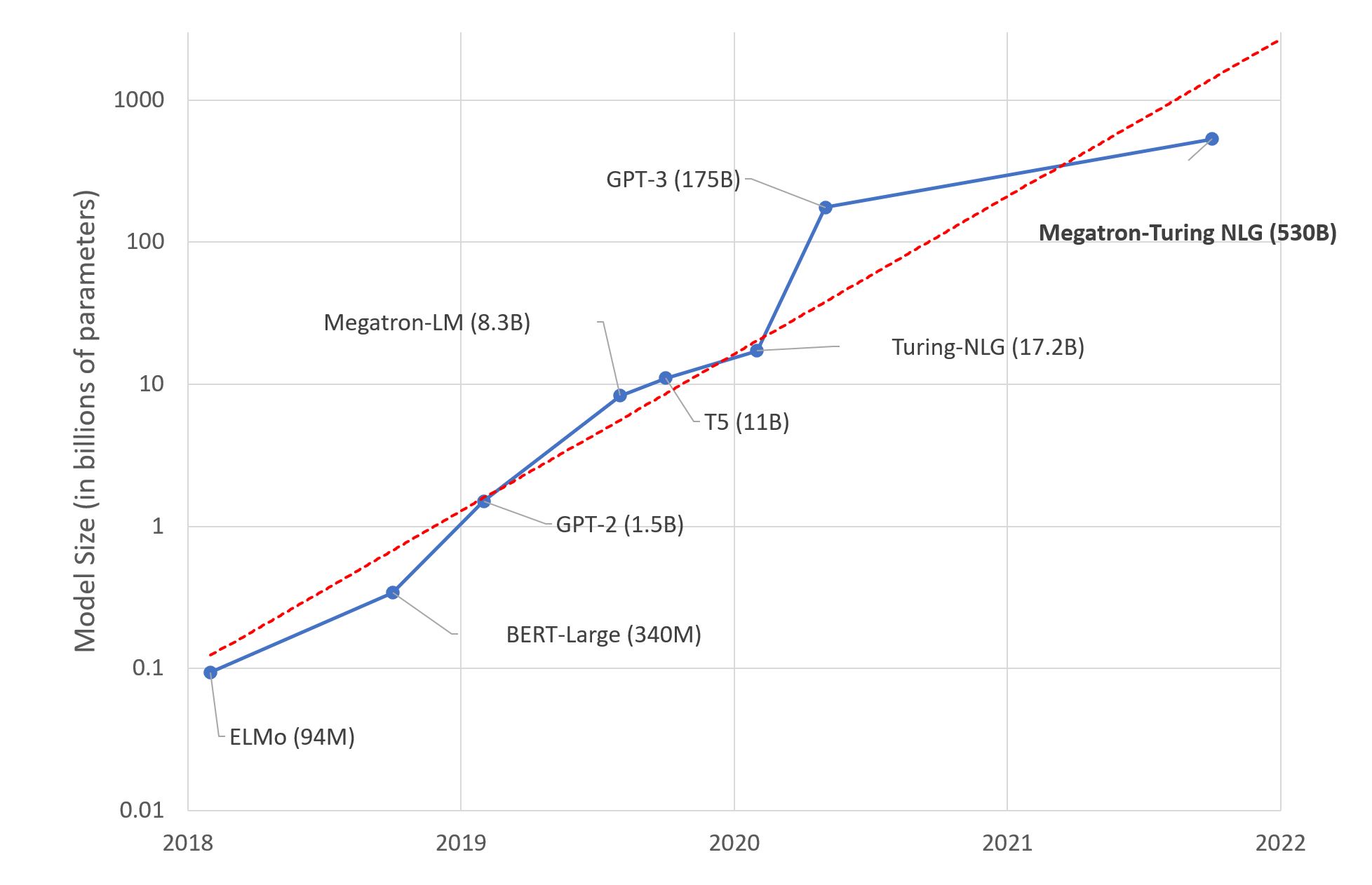
Model Bahasa Besar sering dibandingkan dengan jenis model lain seperti jaringan saraf berulang dan mesin berbasis aturan. Keuntungan utama menggunakan model bahasa berukuran besar adalah model tersebut dapat diskalakan dengan baik dengan data pelatihan. Tidak seperti RNN, jarak antara node input dan output dalam model bahasa besar jauh lebih besar, yang memungkinkan lebih banyak lapisan dan representasi terdistribusi lebih baik. Selain itu, model dapat dengan mudah diperbarui dan disesuaikan bahkan setelah diterapkan.
Dengan semakin besarnya ukuran kumpulan data dan meningkatnya permintaan akan aplikasi bahasa alami yang kompleks, penggunaan model bahasa berukuran besar menjadi semakin penting. Dengan memanfaatkan kekuatan model besar ini, ilmuwan komputer dapat mengembangkan aplikasi berbasis AI yang lebih baik sehingga dapat memahami bahasa dengan lebih akurat.
