



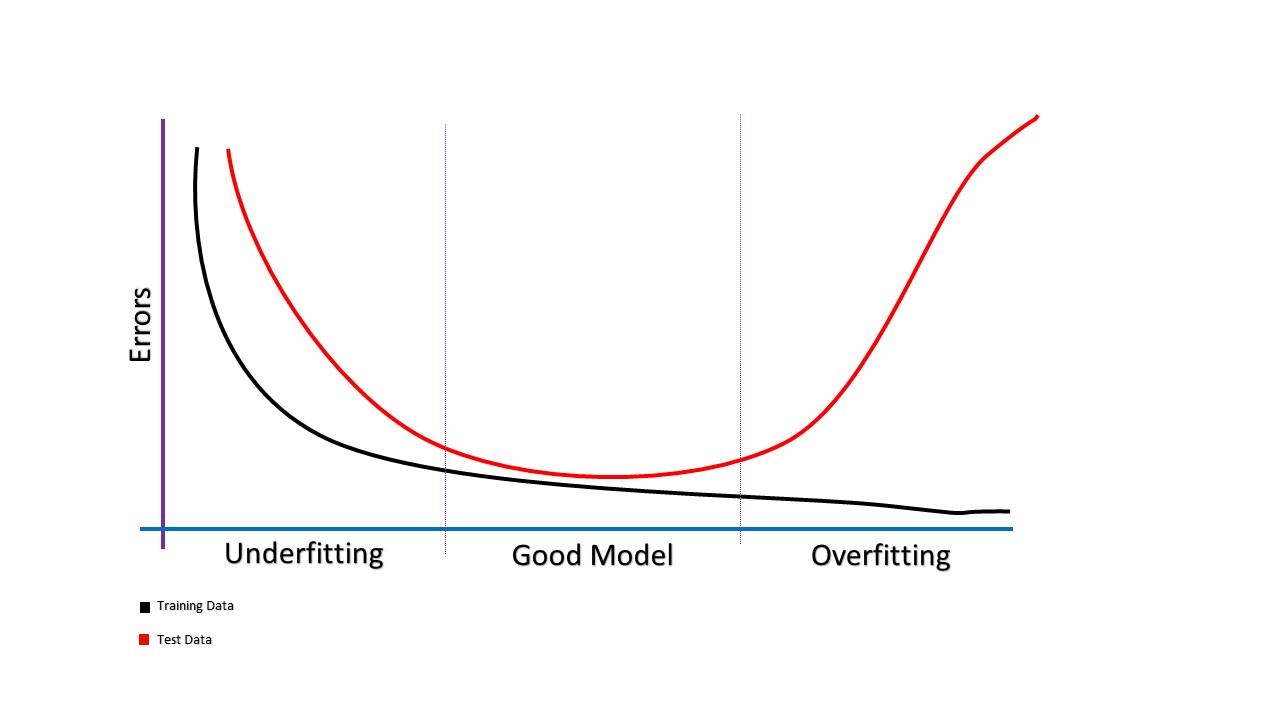
アンダーフィッティングとは機械学習で使用される用語で、トレーニング データに適合しないモデル、または予測能力が低いモデルを指します。これは、モデルが単純すぎてデータの基礎となる構造を把握できない場合に発生します。アンダーフィッティングは「高バイアス」とも呼ばれ、モデルの複雑さのレベルが不十分で入力と期待される出力の関係を捉えることができない場合に発生します。
アンダーフィッティングは、トレーニング データで生成された誤差を測定することで評価できます。誤差が大きすぎる場合は、モデルがデータの基礎となる構造を捕捉できないことを示唆しています。アンダーフィッティングの一般的な症状には、偏り (予測値が一貫して高すぎるか低すぎることを意味します)、高い分散 (さまざまな例で誤差が大きいことを意味します)、および精度の低さが含まれます。
アンダーフィッティングは通常、トレーニング データが限られている、モデルが単純すぎる、またはモデルの構築に使用される機能が不十分であることが原因で発生します。この問題を解決するには、より多くのデータを収集するか、さまざまなアルゴリズムを試すか、より多くの機能を使用する必要があります。
アンダーフィッティングはオーバーフィッティングの逆であり、モデルが複雑になりすぎてデータの基礎となる構造を捕捉できない場合に発生します。最高の精度でモデルを作成するには、アンダーフィッティングとオーバーフィッティングの両方を回避することが重要です。
