



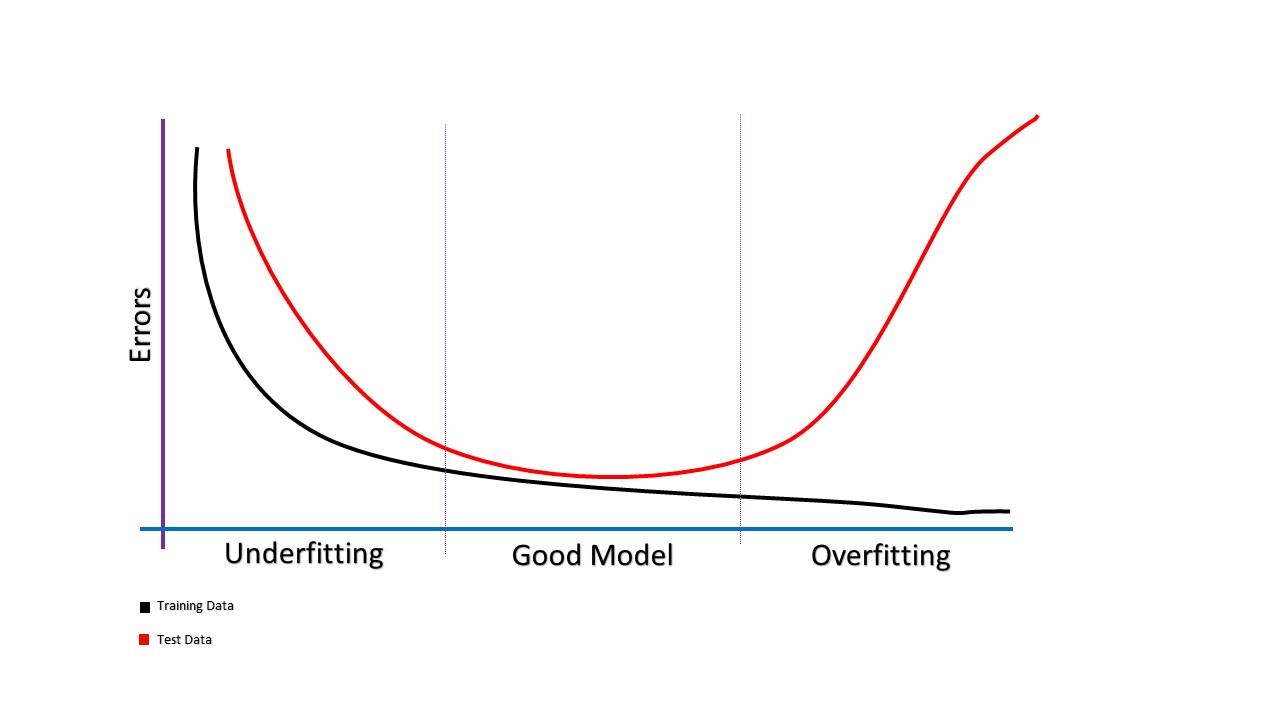
Underfitting is a term used in machine learning and refers to a model that does not fit the training data or has low predictive power. It occurs when a model is too simple to capture the underlying structure of the data. Underfitting is also known as “high bias” and happens when a model has insufficient levels of complexity to capture the relationship between the input and the expected output.
Underfitting can be assessed by measuring the error produced on training data. If the error is too high, it suggests that the model cannot capture the underlying structure of the data. Common symptoms of underfitting include bias (meaning that the predicted values are consistently too high or low), high variance (meaning that the error is large for different examples), and low accuracy.
Underfitting is usually caused by limited training data, too simple of a model, or insufficient features used for building the model. To fix the issue, more data must be collected, different algorithms can be tried, or more features can be used.
Underfitting is the opposite of overfitting, which occurs when a model becomes too complex to capture the underlying structure of the data. It is important to avoid both underfitting and overfitting in order to produce a model with the highest amount of accuracy.
