



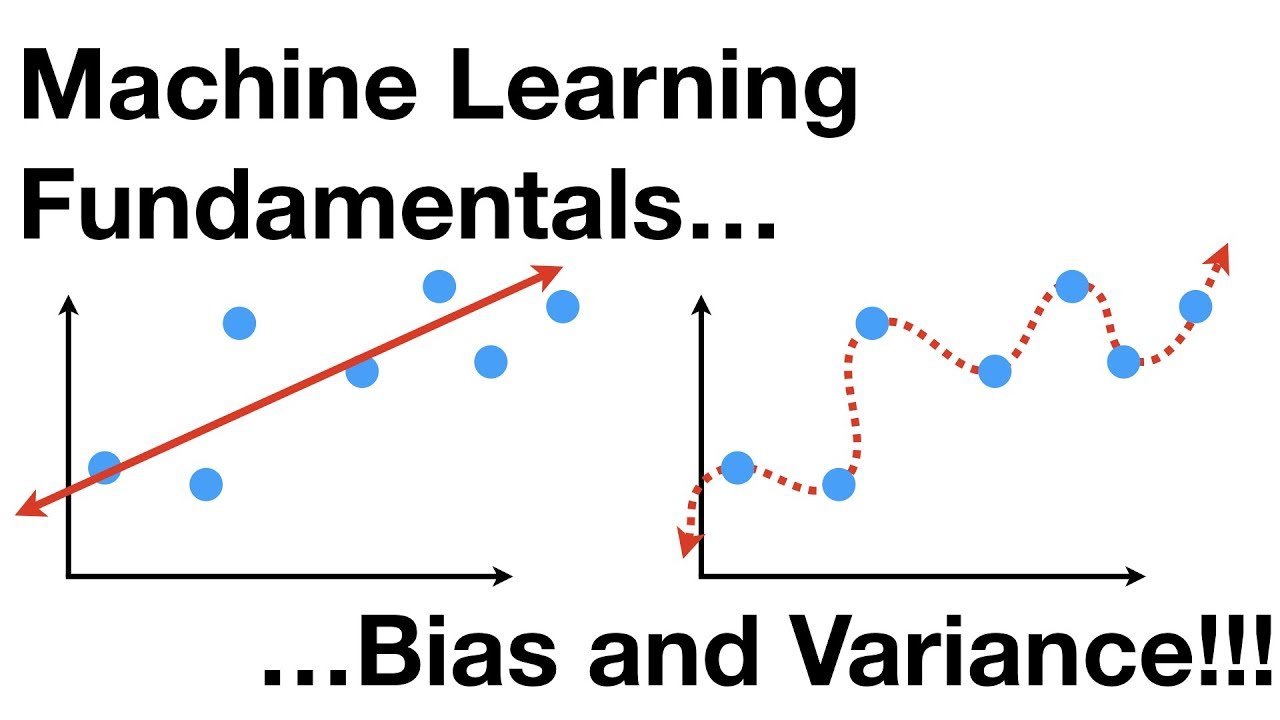
Bias und Varianz sind zwei grundlegende Konzepte des maschinellen Lernens, die eine wichtige Rolle bei der Modellauswahl und Leistungsoptimierung spielen.
Bias ist ein Maß dafür, wie gut ein Modell die zugrunde liegende Beziehung zwischen den Eingabedaten und der erwarteten Ausgabe genau erfasst. Ein Modell mit einer hohen Verzerrung ist möglicherweise zu stark vereinfacht und ignoriert wichtige Muster in den Daten, was bei der Anwendung auf neue Situationen zu einer schlechten Leistung führt. Im Gegenteil: Ein Modell mit geringer Verzerrung kann zu komplex sein, was zu einer Überanpassung und weniger stabilen Vorhersagen führt.
Die Varianz hingegen misst, wie stark die Vorhersagen eines Modells basierend auf den ihm zur Verfügung gestellten Daten variieren. Ein Modell mit hoher Varianz neigt dazu, übermäßig empfindlich auf kleine Änderungen in den Trainingsdaten zu reagieren, was es schwierig macht, über den gegebenen Datensatz hinaus zu verallgemeinern. Umgekehrt bietet ein Modell mit geringer Varianz robustere Vorhersagen, ist jedoch möglicherweise nicht so genau bei der Erfassung des gesamten Datenspektrums.
Das optimale Modell sollte ein Gleichgewicht zwischen Bias und Varianz herstellen; Zu viel davon kann zu einer Leistungsschwäche führen. Dies wird oft als Bias-Variance-Tradeoff bezeichnet, der eine wichtige Richtlinie für die Optimierung jedes Modells für maschinelles Lernen darstellt.
