



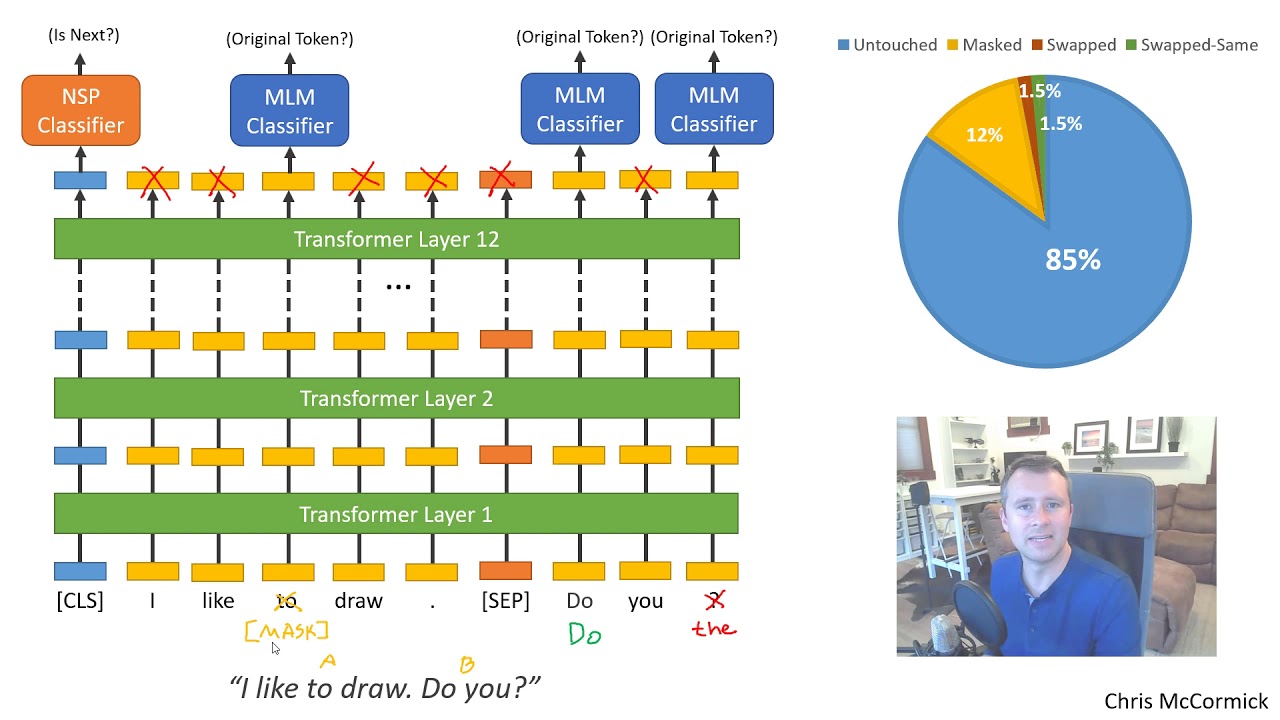
Model bahasa bertopeng adalah jenis algoritma pemrosesan bahasa alami (NLP) yang digunakan untuk menyelesaikan beberapa tugas yang lebih sulit dalam pemahaman bahasa alami (NLU). Dalam model bahasa bertopeng pada umumnya, kata-kata dalam bahasa tertentu “disamarkan” atau “disembunyikan”, dan model harus “mengisi bagian yang kosong” untuk menebak kata aslinya. Hal ini memperkuat kemampuan model untuk memahami makna di balik kata-kata dan dapat digunakan untuk menghasilkan prediksi pada data baru atau untuk tugas inferensi.
Penggunaan model bahasa bertopeng dimulai pada pertengahan tahun 2000an dan semakin populer dengan aplikasi seperti menjawab pertanyaan, meringkas, dan analisis sentimen. Model bahasa bertopeng yang paling populer adalah BERT (BiDirectional Encoder Representations from Transformers), yang dirilis oleh Google pada tahun 2018. BERT adalah metode berbasis deep learning yang mampu mempelajari representasi bahasa dari teks tak berlabel dengan menggunakan sejumlah “blok transformator” dua arah. ” Hal ini menghasilkan optimalisasi bobot dalam model bahasa tertentu dan menghasilkan performa yang lebih baik dalam tugas pemahaman bahasa alami.
Model bahasa bertopeng juga telah digunakan dalam proyek tingkat industri yang memerlukan pemahaman dan pembuatan teks yang kompleks. Misalnya, teknologi ini telah diterapkan pada chatbot layanan pelanggan yang lebih akurat serta rekomendasi yang dipersonalisasi.
Teknologi ini masih dalam tahap awal, namun berkembang pesat. Dengan semakin banyaknya data yang tersedia dan keakuratan model ini terus meningkat, model bahasa bertopeng diperkirakan akan memiliki dampak besar di masa depan pemrosesan bahasa alami.
