



การสกัดกั้นในการประมวลผลภาษาธรรมชาติ (NLP) เป็นกระบวนการลดคำให้อยู่ในรูปแบบต้นกำเนิดหรือรากศัพท์ ซึ่งทำเพื่อสร้างฐานข้อมูลคำที่เป็นมาตรฐานเพื่อปรับปรุงความเร็วและความแม่นยำของการค้นหาที่เกี่ยวข้องกับการประมวลผลภาษา
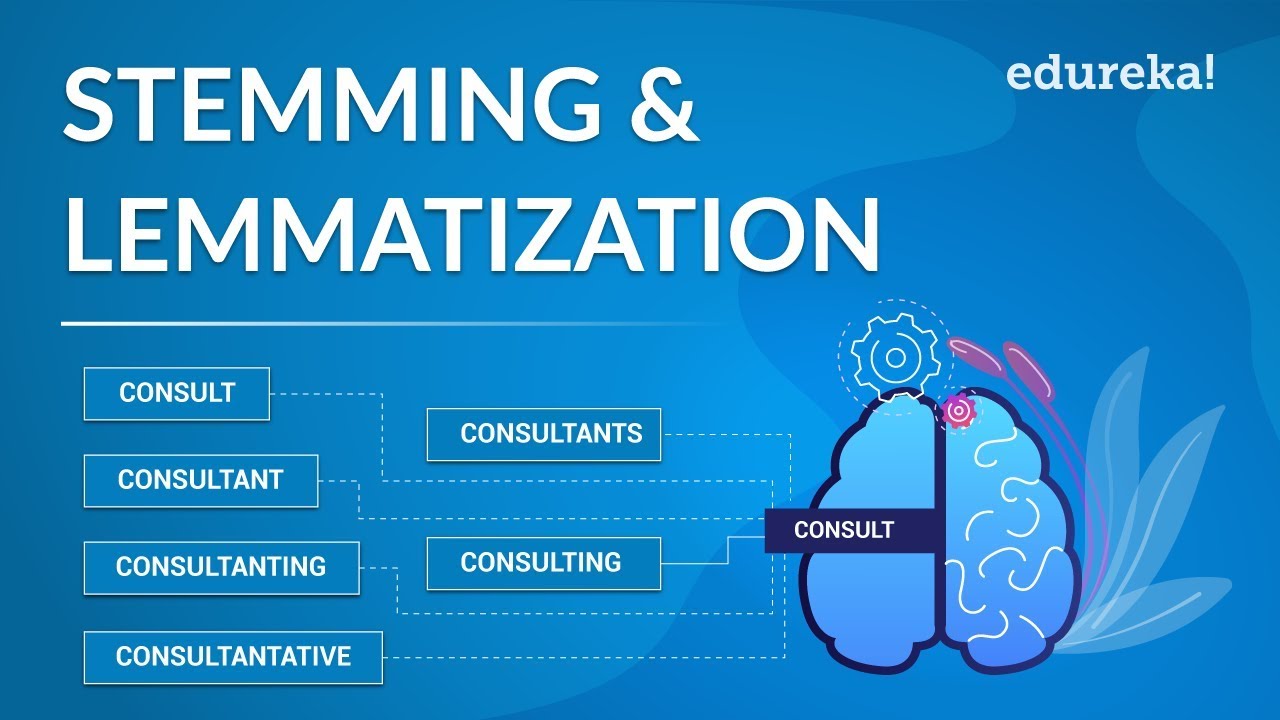
การแยกคำโดยปกติจะทำโดยใช้อัลกอริธึมที่มีชุดคำสั่งสำหรับการเปลี่ยนคำให้อยู่ในรูปแบบต้นกำเนิด การทำงานของก้านตัดจะขึ้นอยู่กับบริบทของคำและภาษาของข้อความที่กำลังประมวลผล เป้าหมายของตัวตัดคำคือการลดคำให้อยู่ในรูปแบบพื้นฐานเพื่อหลีกเลี่ยงความจำเป็นในการค้นหาคำหลายรูปแบบ
กระบวนการแยกคำโดยทั่วไปเกี่ยวข้องกับการลบคำนำหน้าและคำต่อท้ายออกพร้อมกับการเปลี่ยนแปลงที่ตึงเครียด เช่น -ed ที่ส่วนท้ายของคำ อัลกอริธึมการแยกคำอาจดำเนินการประเภทอื่นๆ เช่น การตรวจสอบการผันคำ ตัวอย่างเช่น "run" และ "running" จะลดลงเป็น "run" หากกฎของอัลกอริทึมอนุญาตให้ปล่อย "ing" ออกจากส่วนท้ายของคำ
การแยกคำถูกนำมาใช้กันอย่างแพร่หลายในแอปพลิเคชันการประมวลผลภาษาธรรมชาติหลายอย่าง เช่น การเรียกค้นข้อความและการเรียกข้อมูล การจัดหมวดหมู่ข้อความ การดึงข้อมูล ฯลฯ อัลกอริธึมการแยกคำมีความสำคัญในการอนุญาตให้แอปพลิเคชันเหล่านี้ทำการค้นหาได้แม่นยำยิ่งขึ้น ซึ่งปรับให้เข้ากับภาษาในชีวิตประจำวันที่ผู้คนใช้ได้ดียิ่งขึ้น
นอกจากนี้ Stemming ยังใช้ในการทำความเข้าใจภาษาธรรมชาติซึ่งเป็นกระบวนการทำความเข้าใจภาษาเขียนหรือภาษาพูด แอปพลิเคชันประเภทนี้ช่วยให้ระบบคอมพิวเตอร์เข้าใจสิ่งที่ผู้คนกำลังพูดโดยการลดคำให้อยู่ในรูปรากเพื่อให้คอมพิวเตอร์สามารถเข้าใจได้ง่ายขึ้น การแยกรากมักใช้ร่วมกับเทคนิคอื่นๆ เช่น การแบ่งคำ
โดยรวมแล้ว การขัดขวางการประมวลผลภาษาธรรมชาติเป็นขั้นตอนสำคัญในแอปพลิเคชันการประมวลผลภาษาที่ใช้เพื่อสร้างฐานข้อมูลการค้นหาที่แม่นยำยิ่งขึ้น ในขณะเดียวกันก็ปรับปรุงความเร็วและความแม่นยำไปด้วย เป็นองค์ประกอบสำคัญของการทำความเข้าใจภาษาธรรมชาติและแอปพลิเคชันการเรียนรู้ของเครื่อง
