



Apache Spark 是一个用于集群计算的开源软件框架,它提供了一个接口,用于通过隐式数据并行性和容错能力对整个集群进行编程。它最初是在加州大学伯克利分校的 AMPLab 开发的,作为正在开发的伯克利数据分析堆栈 (BDAS) 的一部分。
Spark 为开发人员提供了应用程序编程接口 (API),以对大型数据集执行复杂的数据分析。其核心功能包括映射缩减、内存计算、循环数据流、事务支持、交互式查询和复杂的缓存。这些功能使其成为当今用于机器学习和数据分析的最流行的大数据处理框架之一。
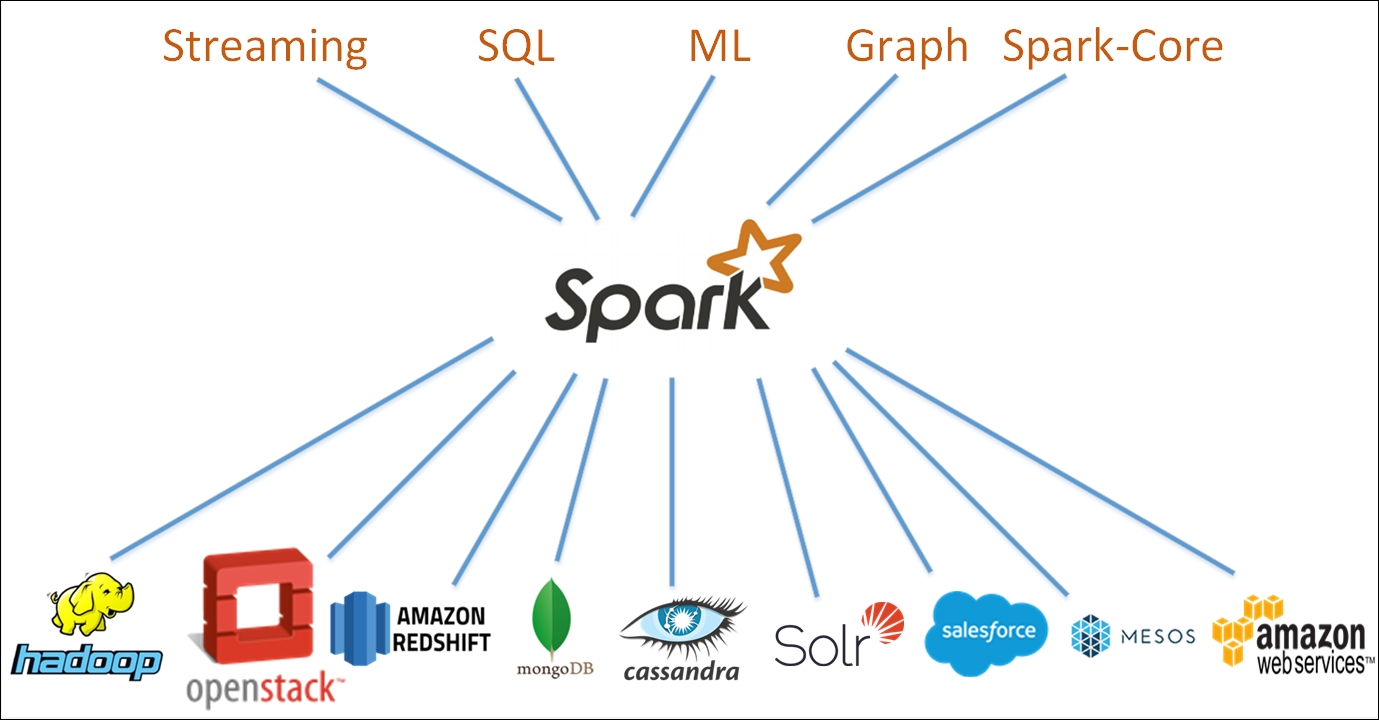
它是用 Scala、Java、Python 和 R 编写的,并提供所有这些语言的库,用于分布式数据集的数据分析。它还支持使用 Spark Streaming 进行流处理。此外,Spark 可以与一系列存储源交互,包括 HDFS、Hive、Cassandra、Kafka 和 Amazon S3。
Apache Spark 允许用户通过将计算分布在多台机器上来以分布式方式运行计算。它具有主从架构,并经过优化以在分布式环境中运行,例如在多台计算机或集群的节点上。
Apache Spark 的主要优势之一是其速度。由于其内存处理模型,与 Hadoop MapReduce 相比,它的数据处理执行时间要快得多。这种内存存储功能允许用户更快、更有效地处理数据。
Apache Spark 是一个强大的分布式计算框架,其特性使其成为最流行的大数据处理框架。它支持多种编程语言,并且可以与一系列存储系统和其他数据源交互,从而能够以更快、更轻松的方式分析大型数据集。
