



자신이 모험심이 강한 탐험가라고 상상해 보세요. 열대 우림이 아닌 거대 온라인 소매업체인 아마존의 광활하고 신비로운 영역으로 먼저 뛰어들어 보세요. 클릭할 때마다 귀중한 보물을 발견하고 미지의 데이터 영역을 더 깊이 탐구할 수 있습니다.
이 스릴 넘치는 탐험에서 우리는 Amazon 웹 스크래핑이라는 밀집된 디지털 정글을 탐색하기 위한 단계별 가이드를 제시합니다. 비교할 수 없는 정확성으로 가치 있는 정보를 추출할 수 있는 전문가의 팁과 요령으로 무장하여 다른 어떤 것과도 비교할 수 없는 여정을 시작할 준비를 하세요.
목차
그러니 용기를 내어 가상 부츠를 신고 데이터 기반 모험을 함께 시작해 보세요!
Amazon에서 스크랩할 데이터
Amazon 제품과 관련된 수많은 데이터 포인트가 있지만 스크래핑할 때 집중해야 할 주요 요소는 다음과 같습니다.
- 제품명
- 비용
- 절감액(해당되는 경우)
- 항목 요약
- 관련 기능 목록(사용 가능한 경우)
- 리뷰 점수
- 제품 비주얼
이것이 Amazon 품목을 폐기할 때 고려해야 할 주요 측면이지만, 추출하는 정보는 특정 목표에 따라 달라질 수 있다는 점에 유의하는 것이 중요합니다.
몇 가지 기본 요구 사항
수프를 준비하려면 올바른 재료가 필요합니다. 마찬가지로 새로운 웹 스크레이퍼에는 특정 구성 요소가 필요합니다.
- 파이썬 — 사용자 친화성과 광범위한 라이브러리 컬렉션으로 인해 Python은 웹 스크래핑을 위한 최고의 선택입니다. 아직 설치되지 않은 경우 이 가이드를 참조하세요.
- BeautifulSoup — 이것은 Python에서 사용할 수 있는 많은 웹 스크래핑 라이브러리 중 하나입니다. 단순성과 깔끔한 사용법으로 인해 웹 스크래핑에 널리 사용됩니다. Python을 성공적으로 설치한 후 다음을 실행하여 Beautiful Soup을 설치할 수 있습니다. pip install bs4
- HTML 태그의 기본 이해 — HTML 태그에 대해 필요한 지식을 얻으려면 이 튜토리얼을 참조하십시오.
- 웹 브라우저 — 웹사이트에서 관련 없는 정보를 많이 필터링해야 하기 때문에 필터링을 위해서는 특정 ID와 태그가 필요합니다. Google Chrome 또는 Mozilla Firefox와 같은 웹 브라우저는 해당 태그를 식별하는 데 유용합니다.
스크래핑 설정
시작하려면 Python이 설치되어 있는지 확인하십시오. Python 3.8 이상이 없으면 python.org를 방문하여 최신 버전을 다운로드하고 설치하세요.
다음으로 Amazon용 웹 스크래핑 코드 파일을 저장할 디렉터리를 만듭니다. 일반적으로 프로젝트에 대한 가상 환경을 설정하는 것이 좋습니다.
macOS 및 Linux에서 가상 환경을 생성하고 활성화하려면 다음 명령을 사용하십시오.
$ python3 -m venv .env
$ source .env/bin/activateWindows 사용자의 경우 명령이 약간 다릅니다.
d:amazon>python -m venv .env
d:amazon>.envscriptsactivate이제 필요한 Python 패키지를 설치할 차례입니다.
두 가지 주요 작업, 즉 HTML을 얻고 이를 구문 분석하여 관련 데이터를 추출하려면 패키지가 필요합니다.
요청 라이브러리는 HTTP 요청을 만들기 위해 널리 사용되는 타사 Python 라이브러리입니다. 웹 서버에 HTTP 요청을 하고 응답을 받기 위한 간단하고 사용자 친화적인 인터페이스를 제공합니다. 아마도 웹 스크래핑을 위한 가장 잘 알려진 라이브러리일 것입니다.
그러나 요청 라이브러리에는 제한 사항이 있습니다. HTML 응답을 문자열로 반환하므로 웹 스크래핑 코드를 작성할 때 가격 목록과 같은 특정 요소를 검색하기 어려울 수 있습니다.
이것이 바로 Beautiful Soup이 등장하는 이유입니다. Beautiful Soup은 HTML 및 XML 파일에서 데이터를 추출하는 웹 스크래핑용으로 설계된 Python 라이브러리입니다. 태그, 속성 또는 특정 텍스트를 검색하여 웹 페이지에서 정보를 검색할 수 있습니다.
두 라이브러리를 모두 설치하려면 다음 명령을 사용하십시오.
$ python3 -m pip install requests beautifulsoup4Windows 사용자의 경우 'python3'을 'python'으로 바꾸고 나머지 명령은 동일하게 유지합니다.
d:amazon>python -m pip install requests beautifulsoup4우리는 Beautiful Soup 라이브러리 버전 4를 설치하고 있다는 점에 주목하세요.
이제 요청 스크래핑 라이브러리를 테스트해 보겠습니다. amazon.py라는 새 파일을 생성하고 다음 코드를 입력합니다.
import requests
url = 'https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L'
response = requests.get(url)
print(response.text)파일을 저장하고 터미널에서 실행하세요.
$ python3 amazon.py대부분의 경우 원하는 HTML을 볼 수 없습니다. Amazon은 요청을 차단하며 다음과 같은 응답을 받게 됩니다.
To discuss automated access to Amazon data please contact [email protected].response.status_code를 인쇄하면 200 성공 코드 대신 503 오류가 표시되는 것을 볼 수 있습니다.
Amazon은 이 요청이 브라우저에서 온 것이 아니라는 것을 알고 이를 차단합니다. 이 관행은 많은 웹사이트에서 일반적입니다. Amazon은 귀하의 요청을 차단하고 500 또는 때로는 400으로 시작하는 오류 코드를 반환할 수 있습니다.
간단한 해결책은 브라우저에서 보낸 헤더를 모방하여 요청과 함께 헤더를 보내는 것입니다.
때로는 사용자 에이전트만 보내는 것으로 충분할 때도 있습니다. 다른 경우에는 승인 언어 헤더와 같은 추가 헤더를 보내야 할 수도 있습니다.
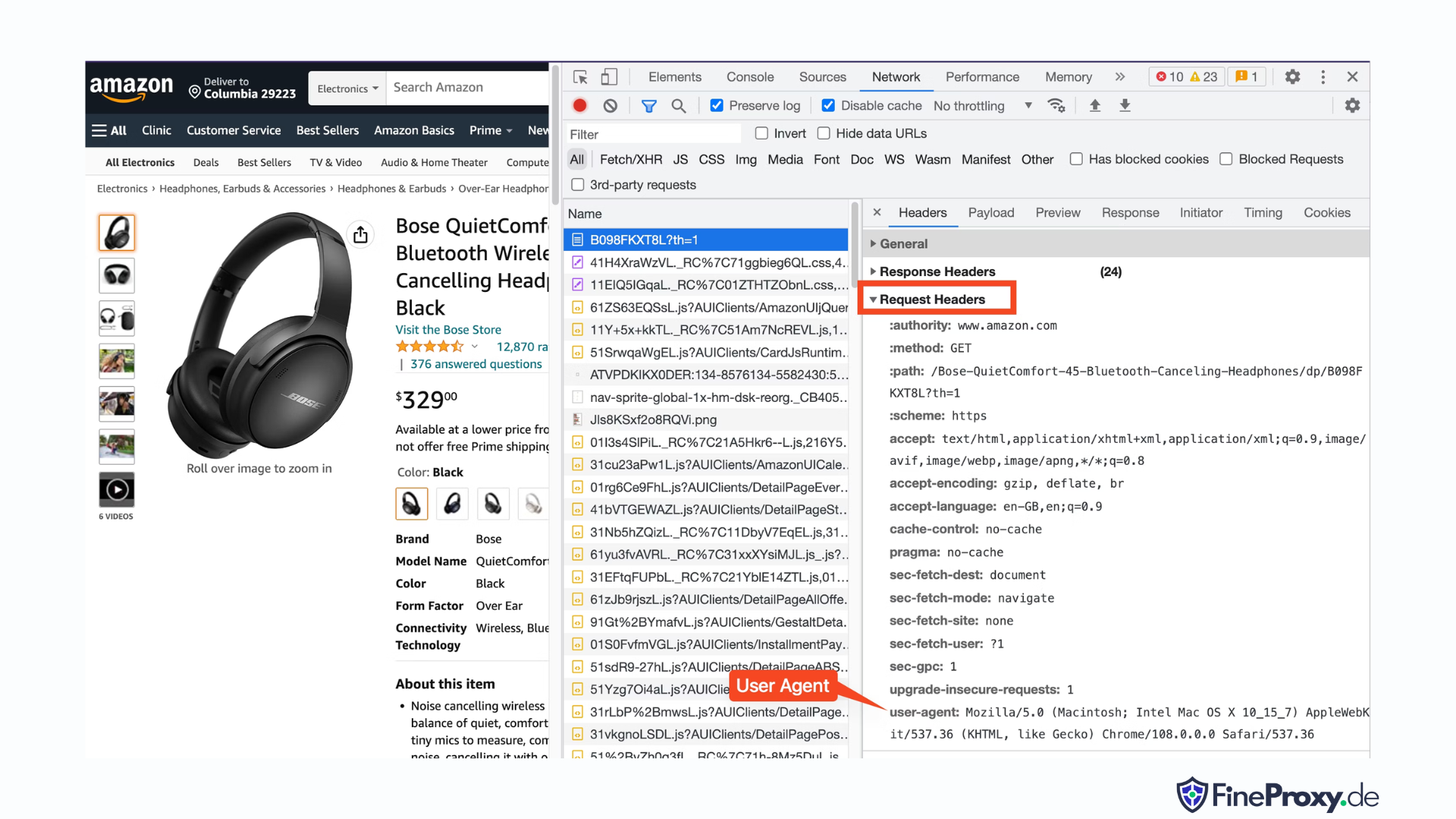
브라우저에서 보낸 사용자 에이전트를 찾으려면 F12를 누르고 네트워크 탭을 열고 페이지를 다시 로드하세요. 첫 번째 요청을 선택하고 요청 헤더를 검사합니다.
이 user-agent를 복사하고 user-agent 및 accept-언어 헤더가 포함된 다음 예와 같이 헤더에 대한 사전을 만듭니다.
custom_headers = { '
user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'accept-language': 'en-GB,en;q=0.9',
}그런 다음 이 사전을 get 메소드의 선택적 매개변수로 보낼 수 있습니다.
response = requests.get(url, headers=custom_headersAmazon 제품 정보 스크랩
Amazon 제품을 웹 스크래핑하는 과정에서 일반적으로 카테고리 페이지와 제품 세부 정보 페이지라는 두 가지 유형의 페이지를 사용하게 됩니다.
예를 들어 다음을 방문하세요. https://www.amazon.com/b?node=12097479011 또는 Amazon에서 오버이어 헤드폰을 검색해 보세요. 검색 결과를 표시하는 페이지를 카테고리 페이지라고 합니다.
카테고리 페이지에는 제품 제목, 제품 이미지, 제품 등급, 제품 가격, 그리고 가장 중요한 제품 URL 페이지가 표시됩니다. 제품 설명 등 더 많은 정보를 확인하려면 제품 세부 정보 페이지를 방문해야 합니다.
상품 상세 페이지의 구조를 분석해 보겠습니다.
다음과 같은 제품 URL을 엽니다. https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L, Chrome 또는 다른 최신 브라우저를 사용합니다. 제품 제목을 마우스 오른쪽 버튼으로 클릭하고 검사를 선택합니다. 제품 제목의 HTML 마크업이 강조표시됩니다.
id 속성이 "productTitle"로 설정된 스팬 태그라는 것을 알 수 있습니다.

마찬가지로 가격을 마우스 오른쪽 버튼으로 클릭하고 검사를 선택하여 가격의 HTML 마크업을 확인합니다.
가격의 달러 구성 요소는 "a-price-whole" 클래스가 있는 스팬 태그에 있고, 센트 구성 요소는 "a-price-fraction" 클래스가 있는 다른 스팬 태그에 있습니다.

같은 방식으로 평점, 이미지, 설명을 찾을 수도 있습니다.
이 정보를 수집한 후 기존 코드에 다음 줄을 추가합니다.
response = requests.get(url, headers=custom_headers)
soup = BeautifulSoup(response.text, 'lxml')Beautiful Soup은 find 메소드를 사용하여 태그를 선택하는 독특한 방법을 제공합니다. 또한 대안으로 CSS 선택기를 지원합니다. 두 가지 접근 방식 중 하나를 사용하여 동일한 결과를 얻을 수 있습니다. 이 튜토리얼에서는 요소를 선택하는 보편적인 방법인 CSS 선택기를 활용합니다. CSS 선택기는 Amazon 제품 정보를 추출하기 위한 거의 모든 웹 스크래핑 도구와 호환됩니다.
이제 Soup 개체를 사용하여 특정 정보를 쿼리할 준비가 되었습니다.
제품명 추출
제품 이름 또는 제목은 ID가 'productTitle'인 범위 요소에서 찾을 수 있습니다. 고유 ID를 사용하여 요소를 선택하는 것은 간단합니다.
다음 코드를 예로 들어보세요.
title_element = soup.select_one('#productTitle') CSS 선택기를 요소 인스턴스를 반환하는 select_one 메서드에 전달합니다.
텍스트에서 정보를 추출하려면 text 속성을 사용하세요.
title = title_element.text인쇄하면 몇 개의 공백이 나타날 수 있습니다. 이 문제를 해결하려면 다음과 같이 .strip() 함수 호출을 추가하세요.
title = title_element.text.strip()제품 평가 추출
Amazon 제품 등급을 얻으려면 추가적인 노력이 필요합니다.
먼저 등급에 대한 선택기를 설정합니다.
#acrPopover다음으로, 다음 문을 사용하여 등급이 포함된 요소를 선택합니다.
rating_element = soup.select_one('#acrPopover')실제 등급 값은 제목 속성 내에서 찾을 수 있습니다.
rating_text = rating_element.attrs.get('title')
print(rating_text)
# prints '4.6 out of 5 stars'마지막으로 숫자 등급을 얻기 위해 교체 방법을 사용합니다.
rating = rating_text.replace('out of 5 stars', '')제품 가격 추출
제품 가격은 제품 제목 아래와 지금 구매 상자 두 곳에서 확인할 수 있습니다.
이러한 태그 중 하나를 사용하여 Amazon 제품 가격을 긁어낼 수 있습니다.
가격에 대한 CSS 선택기를 만듭니다.
#price_inside_buybox이 CSS 선택기를 다음과 같이 BeautifulSoup의 select_one 메소드에 전달하세요.
price_element = soup.select_one('#price_inside_buybox')이제 가격을 인쇄할 수 있습니다.
print(price_element.text)이미지 추출 중
기본 이미지를 스크랩하려면 CSS 선택기 #landingImage를 사용하세요. 이 정보를 사용하여 다음 코드 줄을 작성하여 src 속성에서 이미지 URL을 얻을 수 있습니다.
image_element = soup.select_one('#landingImage')
image = image_element.attrs.get('src')제품 설명 추출
Amazon 제품 데이터를 추출하는 다음 단계는 제품 설명을 얻는 것입니다.
프로세스는 일관되게 유지됩니다. CSS 선택기를 만들고 select_one 메서드를 사용하세요.
설명의 CSS 선택기는 다음과 같습니다.
#productDescription이를 통해 다음과 같이 요소를 추출할 수 있습니다.
description_element = soup.select_one('#productDescription')
print(description_element.text)상품 목록 처리
제품 정보 스크랩을 살펴봤지만 제품 데이터에 액세스하려면 제품 목록 또는 카테고리 페이지부터 시작해야 합니다.
예를 들어, https://www.amazon.com/b?node=12097479011 오버이어 헤드폰 카테고리 페이지입니다.
이 페이지를 살펴보면 모든 제품이 고유 속성 [data-asin]이 있는 div 내에 포함되어 있음을 알 수 있습니다. 해당 div 내의 모든 제품 링크는 h2 태그에 있습니다.
이 정보를 사용하여 CSS 선택기는 다음과 같습니다.
[data-asin] h2 a이 선택기의 href 속성을 읽고 루프를 실행할 수 있습니다. 그러나 링크는 상대적이라는 점을 기억하십시오. 이러한 링크를 구문 분석하려면 urljoin 메소드를 사용해야 합니다.
from urllib.parse import urljoin
...
def parse_listing(listing_url):
…
link_elements = soup_search.select("[data-asin] h2 a")
page_data = []
for link in link_elements:
full_url = urljoin(search_url, link.attrs.get("href"))
product_info = get_product_info(full_url)
page_data.append(product_info)페이지 매김 처리
다음 페이지로의 링크는 "Next"라는 텍스트가 포함된 링크에 있습니다. 다음과 같이 CSS의 포함 연산자를 사용하여 이 링크를 검색할 수 있습니다.
next_page_el = soup.select_one('a:contains("Next")')
if next_page_el:
next_page_url = next_page_el.attrs.get('href')
next_page_url = urljoin(listing_url, next_page_url)Amazon 데이터 내보내기
스크랩된 데이터는 의도적으로 사전으로 반환됩니다. 스크랩한 모든 제품을 포함하는 목록을 생성할 수 있습니다.
def parse_listing(listing_url):
...
page_data = [] for link in link_elements:
...
product_info = get_product_info(full_url)
page_data.append(product_info)그런 다음 이 page_data를 사용하여 Pandas DataFrame 개체를 만들 수 있습니다.
df = pd.DataFrame(page_data)
df.to_csv('headphones.csv', index = False)Amazon에서 여러 페이지를 긁는 방법
Amazon에서 여러 페이지를 스크래핑하면 분석할 더 넓은 데이터 세트를 제공하여 웹 스크래핑 프로젝트의 효율성을 높일 수 있습니다. 여러 페이지를 타겟팅하는 경우 콘텐츠를 여러 페이지에 걸쳐 나누는 프로세스인 페이지 매김을 고려해야 합니다.
여기 있습니다 명심해야 할 6가지 핵심 사항 Amazon에서 여러 페이지를 스크랩할 때:
- 페이지 매김 패턴을 식별합니다. 먼저, 카테고리 또는 검색 결과 페이지의 URL 구조를 분석하여 Amazon이 해당 콘텐츠의 페이지를 매기는 방법을 이해합니다. 이는 쿼리 매개변수(예: '?page=2')이거나 URL에 포함된 고유 식별자일 수 있습니다.
- "다음" 페이지 링크를 추출합니다. 다음 페이지에 대한 링크가 포함된 요소(일반적으로 앵커 태그)를 찾습니다. 적절한 CSS 선택기나 Beautiful Soup 메소드를 사용하여 다음 페이지의 URL인 이 요소의 href 속성을 추출합니다.
- 상대 URL을 절대 URL로 변환: 추출된 URL은 상대적일 수 있으므로
urljoin에서 기능urllib.parse절대 URL로 변환하는 라이브러리입니다. - 루프를 생성합니다: 페이지를 반복하면서 각 페이지에서 원하는 데이터를 긁어내는 루프를 구현하세요. 루프는 더 이상 페이지가 남지 않을 때까지 계속되어야 하며, 이는 현재 페이지에 "다음" 페이지 링크가 있는지 확인하여 확인할 수 있습니다.
- 요청 사이에 지연을 추가합니다. Amazon 서버에 과부하가 걸리거나 봇 방지 조치가 실행되는 것을 방지하려면 다음을 사용하여 요청 사이에 지연을 도입하세요.
time.sleep()에서 기능time도서관. 인간의 브라우징 동작을 에뮬레이트하기 위해 지연 기간을 조정합니다. - CAPTCHA 및 블록 처리: 여러 페이지를 스크래핑하는 동안 CAPTCHA 또는 IP 블록이 발생하는 경우 프록시를 사용하여 IP 주소를 교체하거나 이러한 문제를 자동으로 처리할 수 있는 전용 스크래핑 도구 및 서비스를 사용해 보세요.
아래에는 Amazon 웹사이트의 여러 페이지에서 데이터를 추출하는 과정을 안내하는 포괄적인 YouTube 비디오 튜토리얼이 있습니다. 이 튜토리얼에서는 수많은 Amazon 페이지에서 귀중한 정보를 효율적이고 효과적으로 수집할 수 있는 기술에 중점을 두고 웹 스크래핑의 세계를 깊이 탐구합니다.
튜토리얼 전반에 걸쳐 발표자는 Python, BeautifulSoup 및 요청과 같은 필수 도구 및 라이브러리의 사용 방법을 설명하는 동시에 Amazon의 안티 봇 메커니즘에 의해 차단되거나 감지되지 않는 모범 사례를 강조합니다. 이 비디오에서는 페이지 매김 처리, 속도 제한 관리, 인간과 유사한 탐색 동작 모방과 같은 필수 주제를 다룹니다.
비디오에서 제공되는 단계별 지침 외에도 튜토리얼에서는 웹 스크래핑 경험을 최적화하는 데 유용한 팁과 요령도 공유합니다. 여기에는 프록시를 사용하여 IP 제한을 우회하고, User-Agent 및 요청 헤더를 무작위로 지정하고, 원활하고 중단 없는 스크래핑 프로세스를 보장하기 위한 적절한 오류 처리 구현이 포함됩니다.
Amazon 스크래핑: FAQ
인기 있는 전자상거래 플랫폼인 Amazon에서 데이터를 추출할 때 염두에 두어야 할 몇 가지 사항이 있습니다. Amazon 데이터 스크랩과 관련된 자주 묻는 질문(FAQ)을 살펴보겠습니다.
1. Amazon을 긁는 것이 합법적입니까?
인터넷에서 공개적으로 사용 가능한 데이터를 스크랩하는 것은 합법적이며 여기에는 Amazon 스크랩도 포함됩니다. 제품 세부정보, 설명, 평점, 가격 등의 정보를 합법적으로 스크랩할 수 있습니다. 다만, 상품평을 스크랩하실 때에는 개인정보 및 저작권 보호에 유의하셔야 합니다. 예를 들어, 리뷰어의 이름과 아바타는 개인 데이터로 간주될 수 있지만 리뷰 텍스트는 저작권으로 보호될 수 있습니다. 그러한 데이터를 스크랩할 때는 항상 주의를 기울이고 법적 조언을 구하십시오.
2. 아마존은 스크래핑을 허용합니까?
공개적으로 사용 가능한 데이터를 스크랩하는 것은 합법적이지만 Amazon은 때때로 스크랩을 방지하기 위한 조치를 취합니다. 이러한 조치에는 요청 속도 제한, IP 주소 금지, 브라우저 핑거프린팅을 사용하여 스크래핑 봇 탐지 등이 포함됩니다. Amazon은 일반적으로 200 OK 성공 상태 응답 코드로 웹 스크래핑을 차단하고 CAPTCHA를 전달하도록 요구하거나 유료 API에 대해 영업팀에 문의하려면 HTTP 오류 503 서비스를 사용할 수 없음 메시지를 표시합니다.
이러한 조치를 우회할 수 있는 방법이 있지만 윤리적인 웹 스크래핑은 애초에 이러한 조치를 방지하는 데 도움이 될 수 있습니다. 윤리적인 웹 스크래핑에는 요청 빈도 제한, 적절한 사용자 에이전트 사용, 웹 사이트 성능에 영향을 미칠 수 있는 과도한 스크래핑 방지가 포함됩니다. 윤리적으로 스크랩하면 금지되거나 법적 결과에 직면할 위험을 줄이면서도 Amazon에서 유용한 데이터를 추출할 수 있습니다.
3. Amazon 데이터를 긁어내는 것이 윤리적인가요?
윤리적으로 스크레이핑하려면 대상 웹사이트를 존중해야 합니다. 너무 많은 요청으로 인해 Amazon 웹사이트에 과부하가 걸릴 가능성은 없지만 여전히 윤리적인 스크래핑 지침을 따라야 합니다. 윤리적인 스크래핑은 법적 문제에 직면하거나 스크래핑 방지 조치를 취할 위험을 최소화할 수 있습니다.
4. Amazon을 스크랩하는 동안 금지되는 것을 어떻게 피할 수 있습니까?
Amazon을 스크래핑할 때 금지되는 것을 방지하려면 요청 속도를 제한하고, 사용량이 많은 시간대에 스크래핑을 피하고, 스마트 프록시 교체를 사용하고, 적절한 사용자 에이전트와 헤더를 사용하여 탐지를 피해야 합니다. 또한 필요한 데이터만 추출하고 타사 스크래핑 도구나 스크래핑 라이브러리를 사용하세요.
5. Amazon 스크래핑의 위험은 무엇입니까?
Amazon 데이터를 스크랩하면 법적 조치 및 계정 정지와 같은 잠재적인 위험이 따릅니다. Amazon은 IP 주소 금지, 속도 제한, 브라우저 지문 인식 등 안티 봇 조치를 사용하여 스크래핑을 탐지하고 방지합니다. 그러나 윤리적으로 스크랩하면 이러한 위험을 완화할 수 있습니다.
결론
Amazon 웹 스크래핑이라는 매혹적인 미로에서 벗어나 이 신나는 여정에서 우리가 수집한 귀중한 지식과 기술을 감상하는 시간을 가질 시간입니다. ProxyCompass를 신뢰할 수 있는 가이드로 사용하여 거대 소매업체로부터 귀중한 데이터를 추출하는 우여곡절을 성공적으로 탐색했습니다. 새로 발견한 전문 기술을 기교적으로 활용하여 모험을 계속할 때 디지털 정글은 결코 진화를 멈추지 않는다는 점을 기억하십시오.
호기심을 갖고 웹 스크래핑 마체테를 계속 연마하며 끊임없이 변화하는 데이터 추출 환경을 계속해서 정복하세요. 다음 번 대담한 탐험이 시작될 때까지, 용감한 탐험가님, 데이터 기반 퀘스트가 유익하고 보람 있기를 바랍니다!

