



Picture yourself as an adventurous explorer, diving headfirst into the vast and mysterious realm of the Amazon—not the rainforest, but the online retail giant. With every click, you uncover priceless treasures, delving deeper into the uncharted territory of data.
In this thrilling expedition, we present a step-by-step guide to navigate the dense, digital jungle of Amazon web scraping. Prepare to embark on a journey like no other, armed with expert tips and tricks to extract valuable information with unparalleled precision.
Table of contents
- What Data To Scrape From Amazon
- Some Basic Requirements
- Setting Up for Scraping
- Scraping Amazon Product Information
- How to Scrape Multiple Pages on Amazon
- Scraping Amazon: FAQs
- Conclusion
So, gather your courage, strap on your virtual boots, and let’s begin our data-driven adventure together!
What Data To Scrape From Amazon
There are numerous data points associated with an Amazon product, but the key elements to concentrate on when scraping include:
- Product Title
- Cost
- Savings (when applicable)
- Item Summary
- Associated feature list (if available)
- Review score
- Product visuals
Although these are the primary aspects to consider when scraping an Amazon item, it’s important to note that the information you extract may vary depending on your specific objectives.
Some Basic Requirements
To prepare a soup, we need the right ingredients. Similarly, our new web scraper requires specific components.
- Python — Its user-friendliness and extensive library collection make Python the top choice for web scraping. If it’s not already installed, refer to this guide.
- BeautifulSoup — This is one of many web scraping libraries available for Python. Its simplicity and clean usage make it a popular choice for web scraping. After successfully installing Python, you can install Beautiful Soup by running: pip install bs4
- Basic Understanding of HTML Tags — Consult this tutorial to acquire the necessary knowledge about HTML tags.
- Web Browser — Since we need to filter out a lot of irrelevant information from a website, specific ids and tags are required for filtering purposes. A web browser like Google Chrome or Mozilla Firefox is useful for identifying those tags.
Setting Up for Scraping
To begin, ensure that you have Python installed. If you don’t have Python 3.8 or later, visit python.org to download and install the latest version.
Next, create a directory to store your web scraping code files for Amazon. It’s generally a good idea to set up a virtual environment for your project.
Use the following commands to create and activate a virtual environment on macOS and Linux:
$ python3 -m venv .env
$ source .env/bin/activateFor Windows users, the commands will be slightly different:
d:amazon>python -m venv .env
d:amazon>.envscriptsactivateNow it’s time to install the necessary Python packages.
You’ll need packages for two main tasks: obtaining the HTML and parsing it to extract relevant data.
The Requests library is a widely used third-party Python library for making HTTP requests. It offers a straightforward and user-friendly interface for making HTTP requests to web servers and receiving responses. It is perhaps the most well-known library for web scraping.
However, the Requests library has a limitation: it returns the HTML response as a string, which can be difficult to search for specific elements like listing prices when writing web scraping code.
That’s where Beautiful Soup comes in. Beautiful Soup is a Python library designed for web scraping that extracts data from HTML and XML files. It allows you to retrieve information from a web page by searching for tags, attributes, or specific text.
To install both libraries, use the following command:
$ python3 -m pip install requests beautifulsoup4For Windows users, replace ‘python3’ with ‘python’, keeping the rest of the command the same:
d:amazon>python -m pip install requests beautifulsoup4Note that we’re installing version 4 of the Beautiful Soup library.
Now let’s test the Requests scraping library. Create a new file called amazon.py and enter the following code:
import requests
url = 'https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L'
response = requests.get(url)
print(response.text)Save the file and run it from the terminal.
$ python3 amazon.pyIn most cases, you won’t be able to view the desired HTML. Amazon will block the request, and you’ll receive the following response:
To discuss automated access to Amazon data please contact [email protected].If you print the response.status_code, you’ll see that you receive a 503 error instead of a 200 success code.
Amazon knows this request didn’t come from a browser and blocks it. This practice is common among many websites. Amazon may block your requests and return an error code beginning with 500 or sometimes even 400.
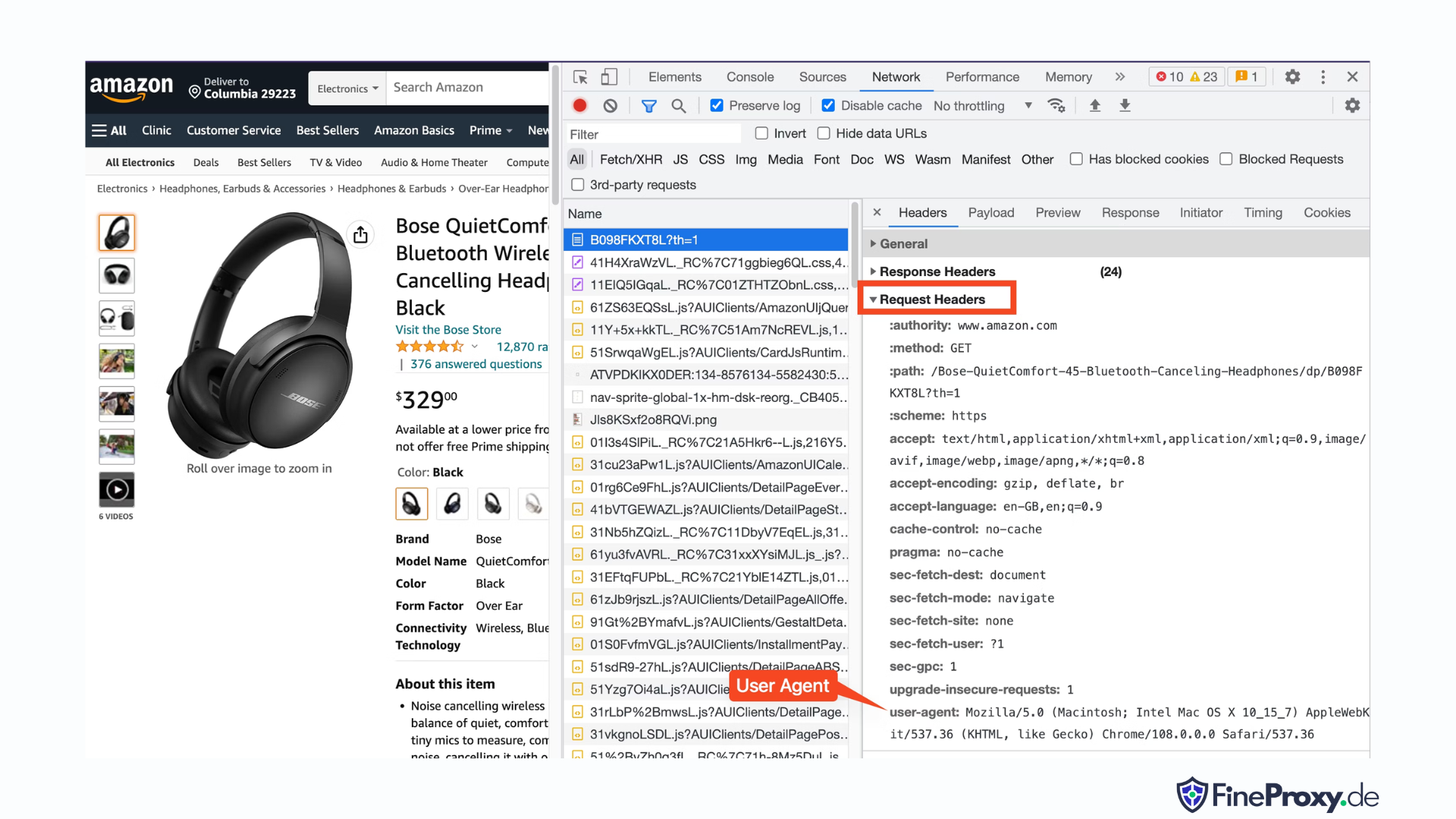
A simple solution is to send headers with your request that mimic those sent by a browser.
Sometimes, sending only the user-agent is sufficient. Other times, you may need to send additional headers, such as the accept-language header.
To find the user-agent sent by your browser, press F12, open the Network tab, and reload the page. Select the first request and examine the Request Headers.
Copy this user-agent and create a dictionary for the headers, like this example with user-agent and accept-language headers:
custom_headers = { '
user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'accept-language': 'en-GB,en;q=0.9',
}You can then send this dictionary as an optional parameter in the get method:
response = requests.get(url, headers=custom_headersScraping Amazon Product Information
In the process of web scraping Amazon products, you’ll typically engage with two types of pages: the category page and the product details page.
For instance, visit https://www.amazon.com/b?node=12097479011 or search for Over-Ear Headphones on Amazon. The page displaying the search results is known as the category page.
The category page presents the product title, product image, product rating, product price, and, most crucially, the product URLs page. To access more information, such as product descriptions, you must visit the product details page.
Let’s analyze the structure of the product details page.
Open a product URL, like https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L, using Chrome or another modern browser. Right-click the product title and choose Inspect. The HTML markup of the product title will be highlighted.
You’ll notice that it’s a span tag with its id attribute set to “productTitle”.

Similarly, right-click the price and select Inspect to view the HTML markup of the price.
The dollar component of the price is in a span tag with the class “a-price-whole”, while the cents component is in another span tag with the class “a-price-fraction”.

You can also locate the rating, image, and description in the same manner.
Once you’ve gathered this information, add the following lines to the existing code:
response = requests.get(url, headers=custom_headers)
soup = BeautifulSoup(response.text, 'lxml')Beautiful Soup offers a distinct method of selecting tags using the find methods. It also supports CSS selectors as an alternative. You can use either approach to achieve the same outcome. In this tutorial, we’ll utilize CSS selectors, a universal method for selecting elements. CSS selectors are compatible with nearly all web scraping tools for extracting Amazon product information.
Now you’re prepared to use the Soup object to query specific information.
Extracting Product Name
The product name or title is found in a span element with the id ‘productTitle’. Selecting elements using unique ids is simple.
Consider the following code as an example:
title_element = soup.select_one('#productTitle') We pass the CSS selector to the select_one method, which returns an element instance.
To extract information from the text, use the text attribute.
title = title_element.textWhen printed, you may notice a few white spaces. To resolve this, add a .strip() function call as follows:
title = title_element.text.strip()Extracting Product Ratings
Obtaining Amazon product ratings requires some additional effort.
First, establish a selector for the rating:
#acrPopoverNext, use the following statement to select the element containing the rating:
rating_element = soup.select_one('#acrPopover')Note that the actual rating value is found within the title attribute:
rating_text = rating_element.attrs.get('title')
print(rating_text)
# prints '4.6 out of 5 stars'Finally, employ the replace method to obtain the numerical rating:
rating = rating_text.replace('out of 5 stars', '')Extracting Product Price
The product price can be found in two locations — below the product title and within the Buy Now box.
Either of these tags can be utilized to scrape Amazon product prices.
Create a CSS selector for the price:
#price_inside_buyboxPass this CSS selector to the select_one method of BeautifulSoup like this:
price_element = soup.select_one('#price_inside_buybox')Now, you can print the price:
print(price_element.text)Extracting Image
To scrape the default image, use the CSS selector #landingImage. With this information, you can write the following code lines to obtain the image URL from the src attribute:
image_element = soup.select_one('#landingImage')
image = image_element.attrs.get('src')Extracting Product Description
The next step in extracting Amazon product data is obtaining the product description.
The process remains consistent — create a CSS selector and use the select_one method.
The CSS selector for the description is:
#productDescriptionThis allows us to extract the element as follows:
description_element = soup.select_one('#productDescription')
print(description_element.text)Handling Product Listing
We’ve explored scraping product information, but you’ll need to start with product listing or category pages to access the product data.
For example, https://www.amazon.com/b?node=12097479011 is the category page for over-ear headphones.
If you examine this page, you’ll see that all products are contained within a div that has a unique attribute [data-asin]. Within that div, all product links are in an h2 tag.
With this information, the CSS Selector is:
[data-asin] h2 aYou can read the href attribute of this selector and run a loop. However, remember that the links will be relative. You’ll need to use the urljoin method to parse these links.
from urllib.parse import urljoin
...
def parse_listing(listing_url):
…
link_elements = soup_search.select("[data-asin] h2 a")
page_data = []
for link in link_elements:
full_url = urljoin(search_url, link.attrs.get("href"))
product_info = get_product_info(full_url)
page_data.append(product_info)Handling Pagination
The link to the next page is in a link containing the text “Next”. You can search for this link using the contains operator of CSS as follows:
next_page_el = soup.select_one('a:contains("Next")')
if next_page_el:
next_page_url = next_page_el.attrs.get('href')
next_page_url = urljoin(listing_url, next_page_url)Exporting Amazon Data
The scraped data is returned as a dictionary intentionally. You can create a list containing all the scraped products.
def parse_listing(listing_url):
...
page_data = [] for link in link_elements:
...
product_info = get_product_info(full_url)
page_data.append(product_info)You can then use this page_data to create a Pandas DataFrame object:
df = pd.DataFrame(page_data)
df.to_csv('headphones.csv', index = False)How to Scrape Multiple Pages on Amazon
Scraping multiple pages on Amazon can enhance the effectiveness of your web scraping project by providing a broader dataset to analyze. When targeting multiple pages, you’ll need to consider pagination, which is the process of dividing content across several pages.
Here are 6 key points to keep in mind when scraping multiple pages on Amazon:
- Identify the pagination pattern: First, analyze the URL structure of the category or search results pages to understand how Amazon paginates its content. This could be a query parameter (e.g., “?page=2”) or a unique identifier embedded within the URL.
- Extract the “Next” page link: Locate the element (usually an anchor tag) containing the link to the next page. Use the appropriate CSS selector or Beautiful Soup method to extract the href attribute of this element, which is the URL for the next page.
- Convert relative URLs to absolute URLs: Since the extracted URLs might be relative, use the
urljoinfunction from theurllib.parselibrary to convert them into absolute URLs. - Create a loop: Implement a loop that iterates through the pages, scraping the desired data from each one. The loop should continue until there are no more pages left, which can be determined by checking if the “Next” page link exists on the current page.
- Add delays between requests: To avoid overwhelming Amazon’s server or triggering anti-bot measures, introduce delays between requests using the
time.sleep()function from thetimelibrary. Adjust the duration of the delay to emulate human browsing behavior. - Handling CAPTCHAs and blocks: If you encounter CAPTCHAs or IP blocks while scraping multiple pages, consider using proxies to rotate IP addresses or dedicated scraping tools and services that can handle these challenges automatically.
Below, you’ll find a comprehensive YouTube video tutorial that guides you through the process of extracting data from multiple pages on Amazon’s website. The tutorial delves deep into the world of web scraping, focusing on techniques that will enable you to efficiently and effectively gather valuable information from numerous Amazon pages.
Throughout the tutorial, the presenter demonstrates the use of essential tools and libraries, such as Python, BeautifulSoup, and requests, while highlighting best practices to avoid getting blocked or detected by Amazon’s anti-bot mechanisms. The video covers essential topics like handling pagination, managing rate limits, and mimicking human-like browsing behavior.
In addition to the step-by-step instructions provided in the video, the tutorial also shares useful tips and tricks to optimize your web scraping experience. These include using proxies to bypass IP restrictions, randomizing User-Agent and request headers, and implementing proper error handling to ensure a smooth and uninterrupted scraping process.
Scraping Amazon: FAQs
When it comes to extracting data from Amazon, a popular e-commerce platform, there are certain things that one needs to be mindful of. Let’s dive into the frequently asked questions related to scraping Amazon data.
1. Is it Legal to Scrape Amazon?
Scraping publicly available data from the internet is legal, and this includes scraping Amazon. You can legally scrape information such as product details, descriptions, ratings, and prices. However, when scraping product reviews, you should be cautious with personal data and copyright protection. For example, the name and avatar of the reviewer may constitute personal data, while the review text may be copyright-protected. Always exercise caution and seek legal advice when scraping such data.
2. Does Amazon Allow Scraping?
Although scraping publicly available data is legal, Amazon sometimes takes measures to prevent scraping. These measures include rate-limiting requests, banning IP addresses, and using browser fingerprinting to detect scraping bots. Amazon usually blocks web scraping with a 200 OK success status response code and requires you to pass a CAPTCHA or shows an HTTP Error 503 Service Unavailable message to contact sales for a paid API.
There are ways to circumvent these measures, but ethical web scraping can help avoid triggering them in the first place. Ethical web scraping involves limiting the frequency of requests, using appropriate user agents, and avoiding excessive scraping that could impact website performance. By scraping ethically, you can reduce the risk of being banned or facing legal consequences while still extracting useful data from Amazon.
3. Is it Ethical to Scrape Amazon Data?
Scraping ethically involves respecting the target website. While it’s unlikely that you will overload the Amazon website with too many requests, you should still follow ethical scraping guidelines. Ethical scraping can minimize the risk of facing legal issues or dealing with anti-scraping measures.
4. How Can I Avoid Getting Banned While Scraping Amazon?
To avoid getting banned when scraping Amazon, you should limit your request rates, avoid scraping during peak hours, use smart proxy rotation, and use appropriate user agents and headers to avoid detection. Additionally, only extract the data you need and use third-party scraping tools or scraping libraries.
5. What Are the Risks of Scraping Amazon?
Scraping Amazon data carries potential risks, such as legal action and account suspension. Amazon uses anti-bot measures to detect and prevent scraping, including IP address bans, rate limiting, and browser fingerprinting. However, by scraping ethically, you can mitigate these risks.
Conclusion
As we emerge from the enthralling labyrinth of Amazon web scraping, it’s time to take a moment to appreciate the invaluable knowledge and skills we’ve gathered on this exhilarating journey. With ProxyCompass as your trusted guide, you’ve successfully navigated the twists and turns of extracting priceless data from the retail behemoth. As you venture forth, wielding your newfound expertise with finesse, remember that the digital jungle never ceases to evolve.
Stay curious, keep sharpening your web scraping machete, and continue to conquer the ever-changing landscape of data extraction. Until our next daring expedition, intrepid explorer, may your data-driven quests be fruitful and rewarding!

