



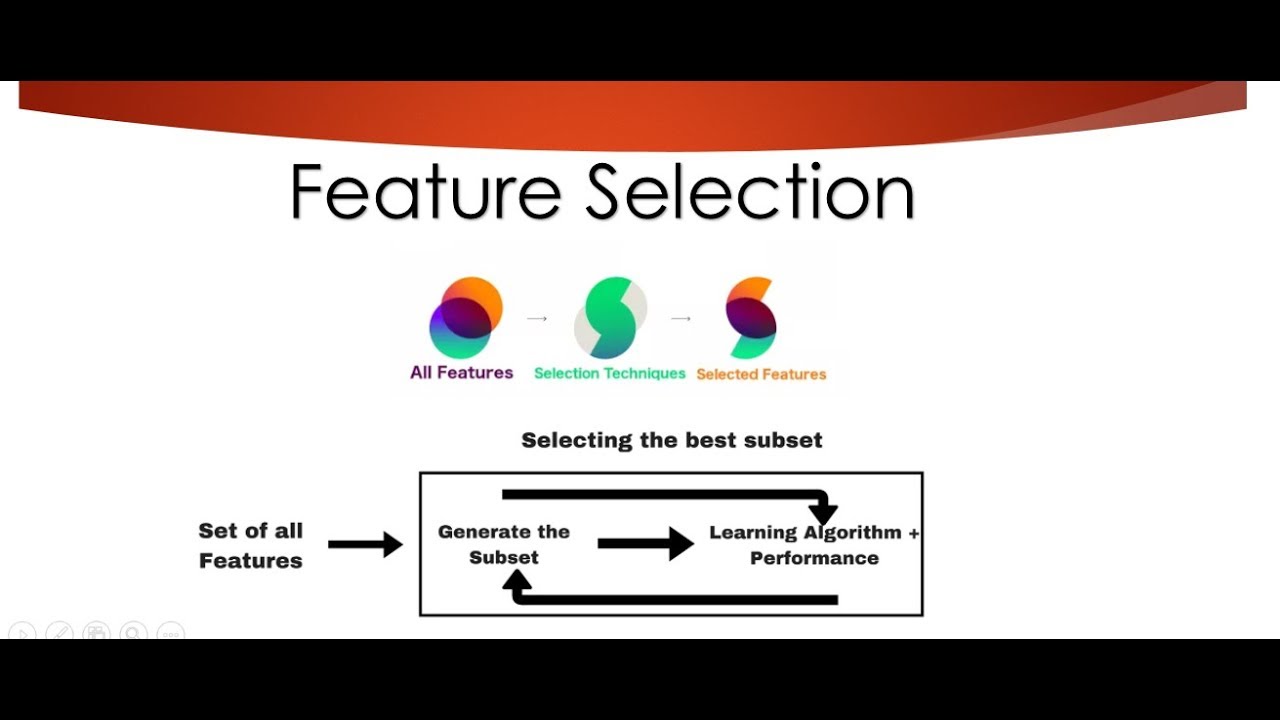
Feature selection (also known as feature subset selection) is a process in computer science and data science of selecting a subset of relevant features (variables, predictors) for use in model construction. A feature selection algorithm looks for and selects the most relevant features in a dataset in order to create a model that accurately predicts the outcome. Feature selection is used to reduce the dimensionality of a dataset, to remove irrelevant data or noise, and to improve the accuracy and computational efficiency of a model.
Feature selection algorithms are commonly used in a variety of data-intensive applications, such as machine learning, data mining, image processing, and pattern recognition. The algorithms can be divided into two main categories: filter methods and wrapper methods. Filter methods select features based on their individual statistical scores, such as Chi-square, information gain, or correlation coefficient. Wrapper methods evaluate the features as a combination and compare models with different combinations of features to optimize an evaluation criterion from a pre-defined set of features.
The types of feature selection algorithm chosen depends upon the problem at hand. For instance, correlation-based methods are often used for continuous, numeric datasets; whereas information-theoretic methods may be used for discrete data.
Overall, feature selection techniques can be used to select the best features from a set of continuously varying variables or features in a dataset and use them in the construction of a machine learning model. This helps to improve the performance of the model by reducing the dimensionality of the dataset, and by removing irrelevant data or noise.
