



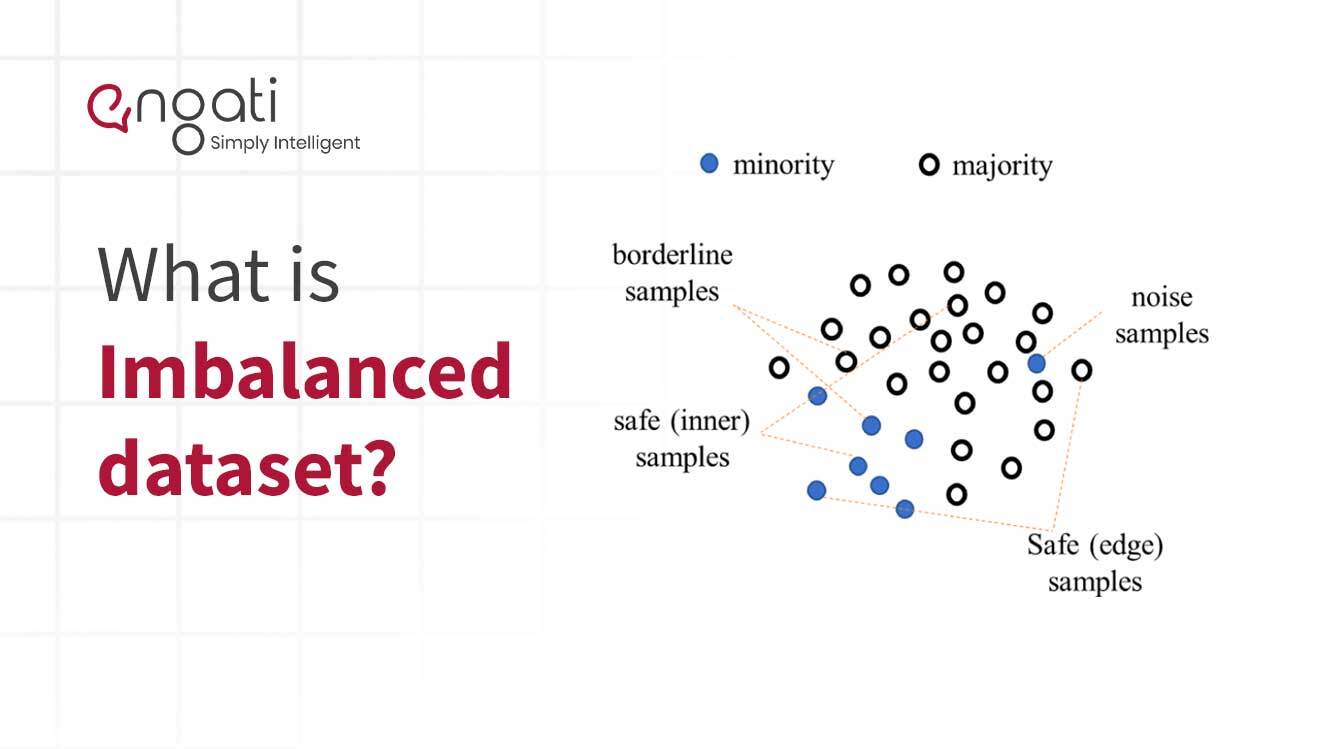
Imbalanced data is a form of data in machine learning and artificial intelligence in which the classification categories within the data observations have different numbers of instances. This form of data causes problems for supervised learning algorithms, as they tend to have difficulty accurately predicting the minority class(es). Imbalanced data is a common phenomenon when collecting data on a particular subject, particularly when the subject of interest is relatively rare.
In the field of Machine Learning, imbalanced data sets are particularly troublesome because most machine-learning algorithms are designed to work best when the categories for classification are approximately equal in number. For example, when a predictive model is trained on data with 10% of its observations belonging to the minority class and 90% belonging to the majority class, the minority cases may become under-represented in the final model. This under-representation leads to a poor performance in terms of accuracy or precision.
The most popular technique to handle imbalanced data is the Synthetic Minority Oversampling Technique (SMOTE). SMOTE works by generating new data points in the minority class (usually near existing data points) and increasing the size of the minority class to match the size of the majority class. This technique is more successful than simply randomly over-sampling the minority class.
In addition to SMOTE, other techniques exist for addressing imbalances. These include: data pre-processing, data augmentation, cost-sensitive learning, meta-learning, and the use of artificial neural networks.
Ultimately, the goal is to achieve a more balanced dataset so that the supervised learning algorithm has enough data to work with from the minority class. This can be done by either undersampling the majority class, or by oversampling the minority class. When used correctly, these techniques can reduce the bias in the data and lead to higher predictive performance.
