



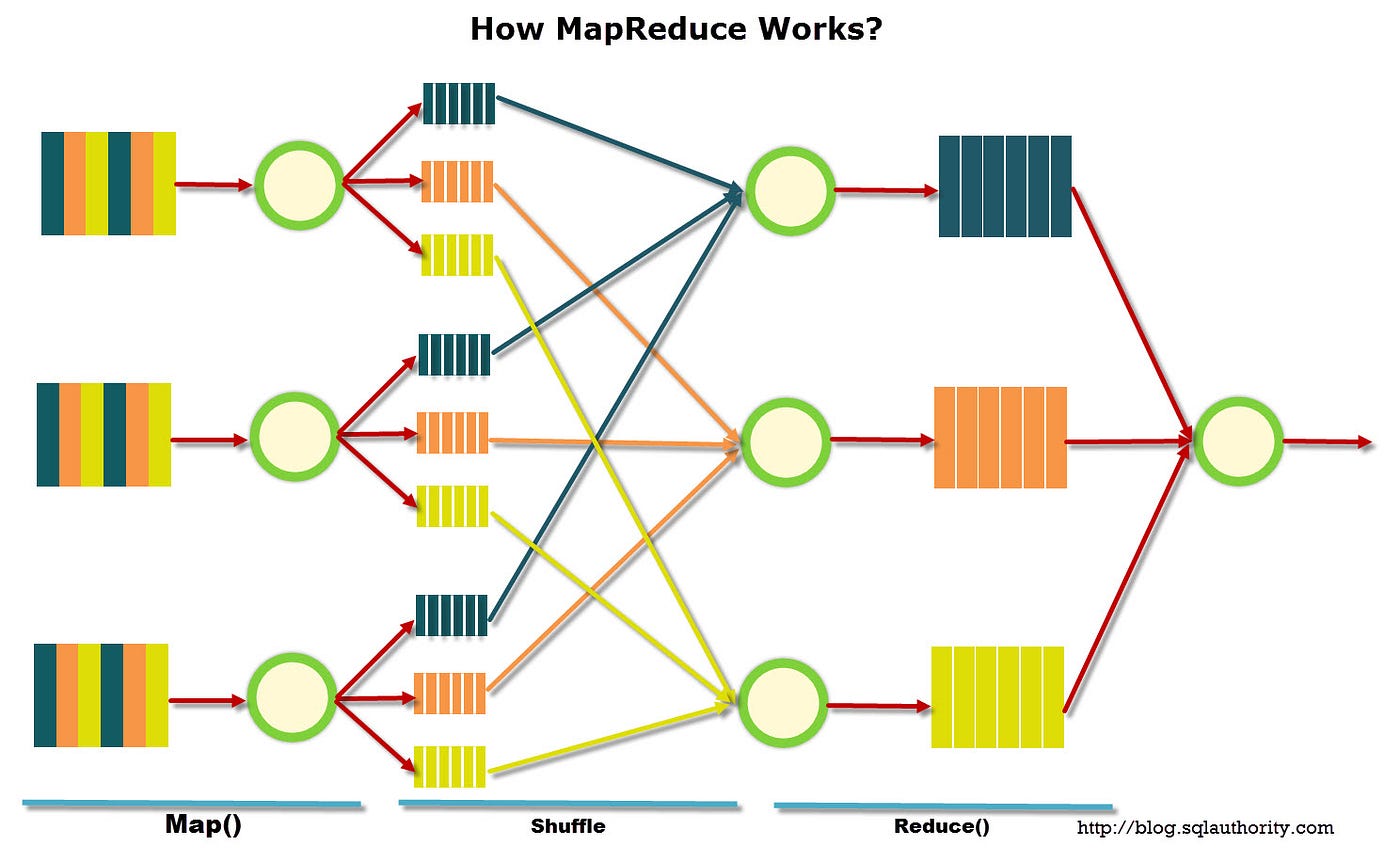
MapReduce is a programming model and an associated implementation for processing and generating large data sets with a parallel, distributed algorithm on a cluster. MapReduce was developed by Google in 2004 and was inspired by the map and reduce functions commonly used in functional programming. MapReduce splits the task at hand into many small fragments of work (the Map step), then combines the results of each step into one single output (the Reduce step).
At its core, MapReduce works by taking a large problem, or dataset, and breaking it up into chunks of work that can be completed independently. The intermediate results from this distributed task are then merged together to form one single output. All of this is done in a distributed fashion, usually across multiple computers.
MapReduce provides the benefits of scalability and fault tolerance without having to invest in additional hardware or setup. Since MapReduce is implemented, it can be used to handle the processing of all kinds of data, from plain text files to binary data. MapReduce can also be used to build reliable real-time analytics pipelines, as it already exists as part of the Google Cloud Platform.
MapReduce is used in many areas, including big data analytics, machine learning, natural language processing, and online gaming. The model is therefore extensively used by many organizations and companies, such as Facebook, Yahoo!, and Twitter as well as being available as an open-source Hadoop platform.
