



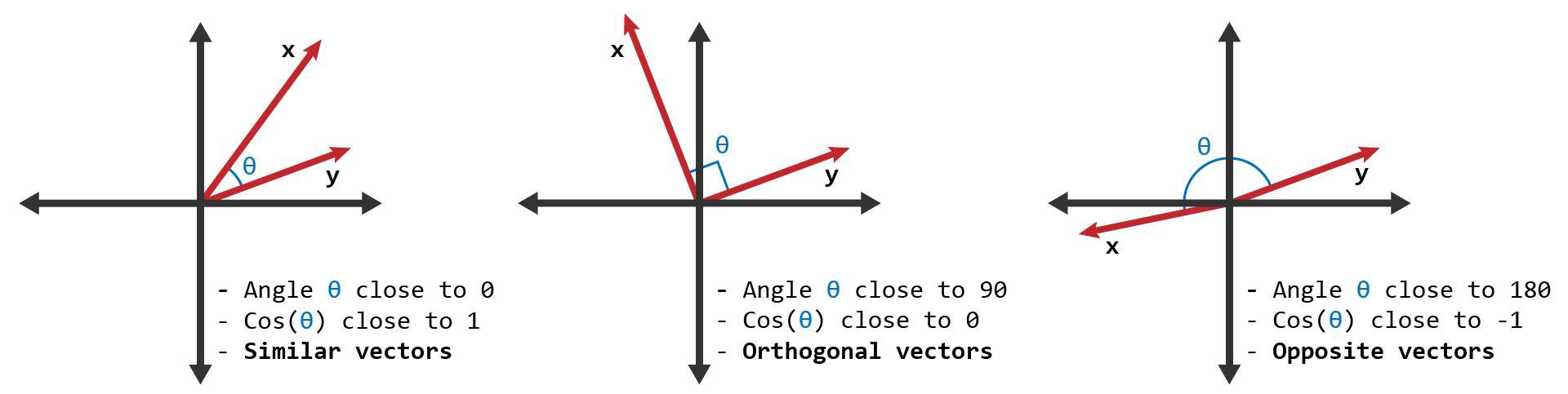
Cosine similarity is a measure of similarity between two non-zero vectors that is based on the cosine of the angle between them. Generally, the higher the angle (and therefore the cosine) between two vectors, the more closely related they are in terms of semantics and meaning. Cosine similarity is commonly used to measure the similarity between two documents or strings of text. It can also be used to measure the similarity between items for recommendation systems.
Cosine similarity is calculated by taking the dot product of two vectors and then dividing by the magnitiude of both vectors. First, the two vectors are normalized so that each has a magnitude of one. Then, the dot product is calculated, which is the sum of the product of the corresponding elements in the vector. This results in a vector of length one which represents the cosine of the angle between the two vectors. This is then used as the measure of similarity between the two vectors.
Cosine similarity can be used in a variety of applications, including natural language processing, semantic analysis, or clustering. It is particularly useful for analyzing large datasets of texts, such as in search engines. By comparing the cosine similarity between a query and a document, it can provide a measure of how closely related those two items are in terms of their meaning. It can also be used in recommendation systems in order to analyze the items that are similar to one another, and thus recommend the relevant items to the user.
In conclusion, cosine similarity is a powerful tool that can be used to measure the similarity between two vectors or items. It has applications in a variety of areas, from natural language processing to recommendation systems, and can be used to find similarities and recommend items to users.
