



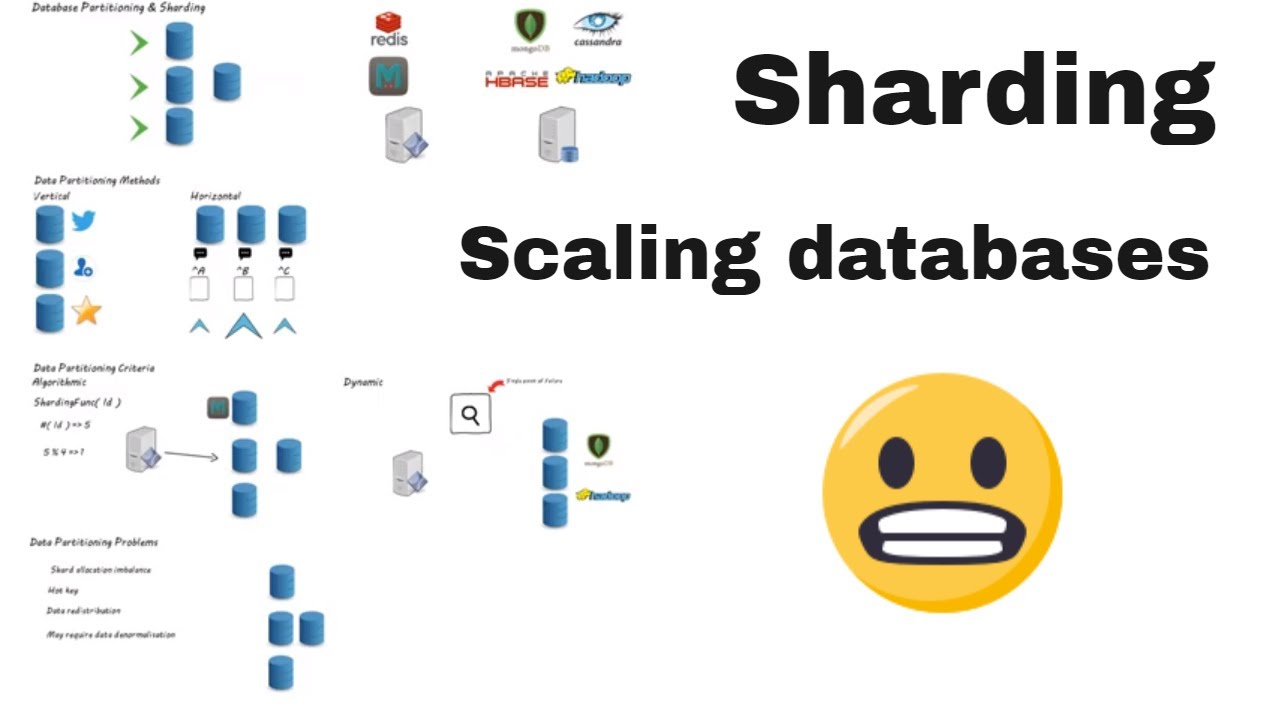
Database Sharding is a method used to manage large databases by splitting the data into smaller, more manageable parts, or “shards”. It is a form of horizontal partitioning, meaning that each shard is a separate part of the database which contains a subset of the total data. This approach is often used to speed up database performance and to reduce resource utilization by reducing the amount of data stored and retrieved in one query.
Sharding is used to split data across multiple machines to increase scalability of databases as the data set grows. By dividing a single large database into multiple smaller databases, Sharding ensures a greater degree of resiliency and reliability for mission critical applications.
Sharding is especially useful in cloud computing scenarios, where databases are often distributed across a number of cloud servers. Sharding helps to optimize distributed database queries, handling large workloads while keeping latency and response times low.
Although it is a useful technique for optimizing database performance and scalability, sharding has some disadvantages. Sharding may lead to increased complexity in the management of the database, as each shard must be separately managed and maintained. Additionally, sharding can increase processing time when data must be retained across multiple servers, as pieces of the original information must be gathered from around the cluster.
Despite some of these drawbacks, Database Sharding remains one of the most popular techniques for managing large and complex databases, allowing enterprises to effectively handle large workloads with ease.
