



Interpretability in machine learning is the concept of making machine learning models more transparent and understandable to multiple audiences, specifically non-experts. It has become increasingly important in recent years as machine learning models have become more complex.
The goal of interpretability is to increase the usefulness of models by understanding why they make certain predictions, more accurately assessing the potential risks of deploying untested models, and clearly communicating why a system is making decisions. It is also important for ethical reasons, as ensuring models do not contain discriminatory or unfair biases is vital.
One way to increase the interpretability of a model is through visualizations. Visualizations such as decision trees, feature importance charts, and partial dependence plots are used to create visual representations of models that make it easier to interpret a system’s behavior.
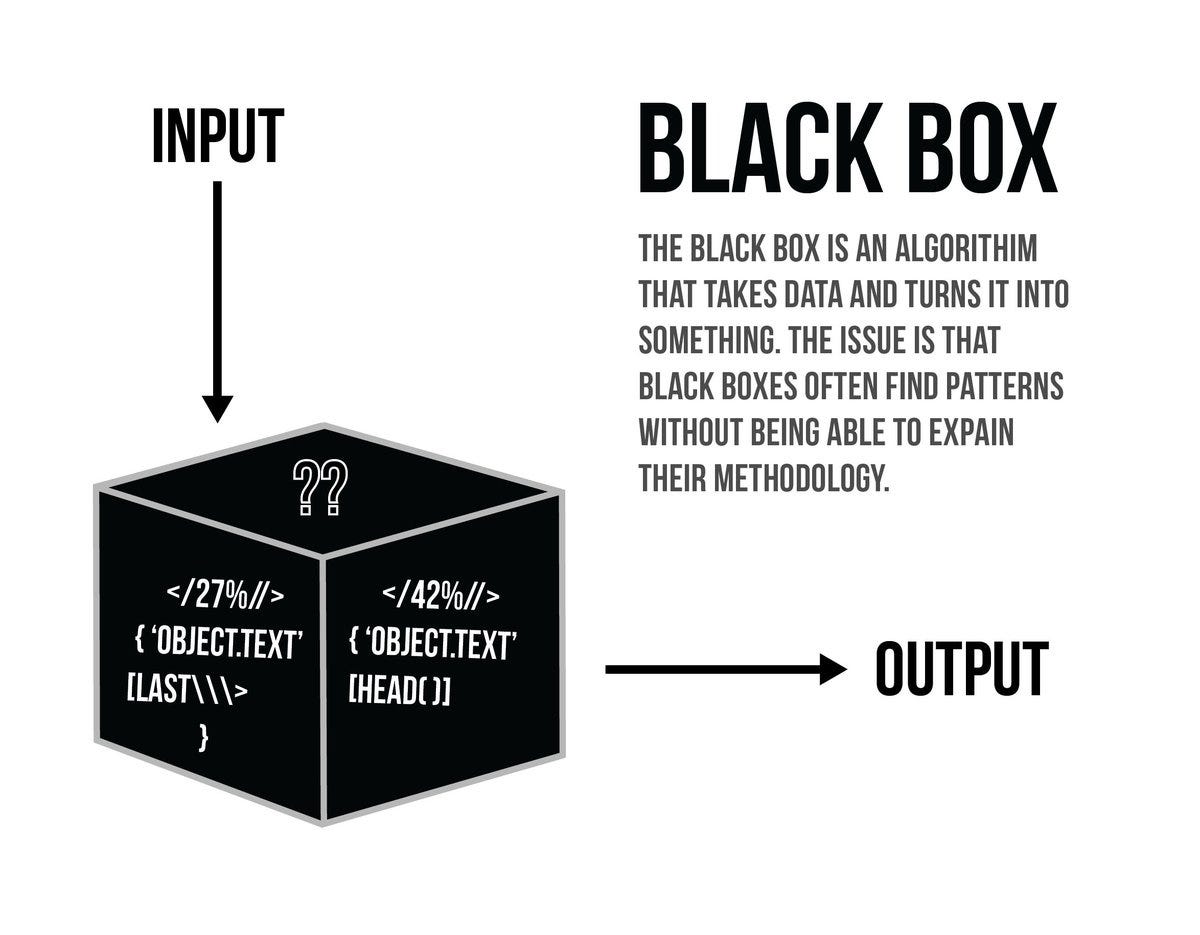
Another way to increase interpretability is by using intelligible features. By replacing numerical features with human-readable ones, models become easier to comprehend and trust. This also helps alleviate a phenomenon known as “black box,” where users have no insight into the decisions a model is making.
Additionally, techniques such as instance-level explanations, which explain single model predictions, are increasingly being applied within the field of machine learning to increase trust in models.
Finally, techniques such as adversarial examples can be used to measure the robustness of a model. These examples provide some interpretability into what makes a model vulnerable to mistakes, such as overfitting or data leakage.
Overall, interpretability has become an increasingly important part of the machine learning landscape. By increasing understandability of models, potential pitfalls can be identified before deployment, and the effective and humane use of machine learning can be more easily achieved.
