



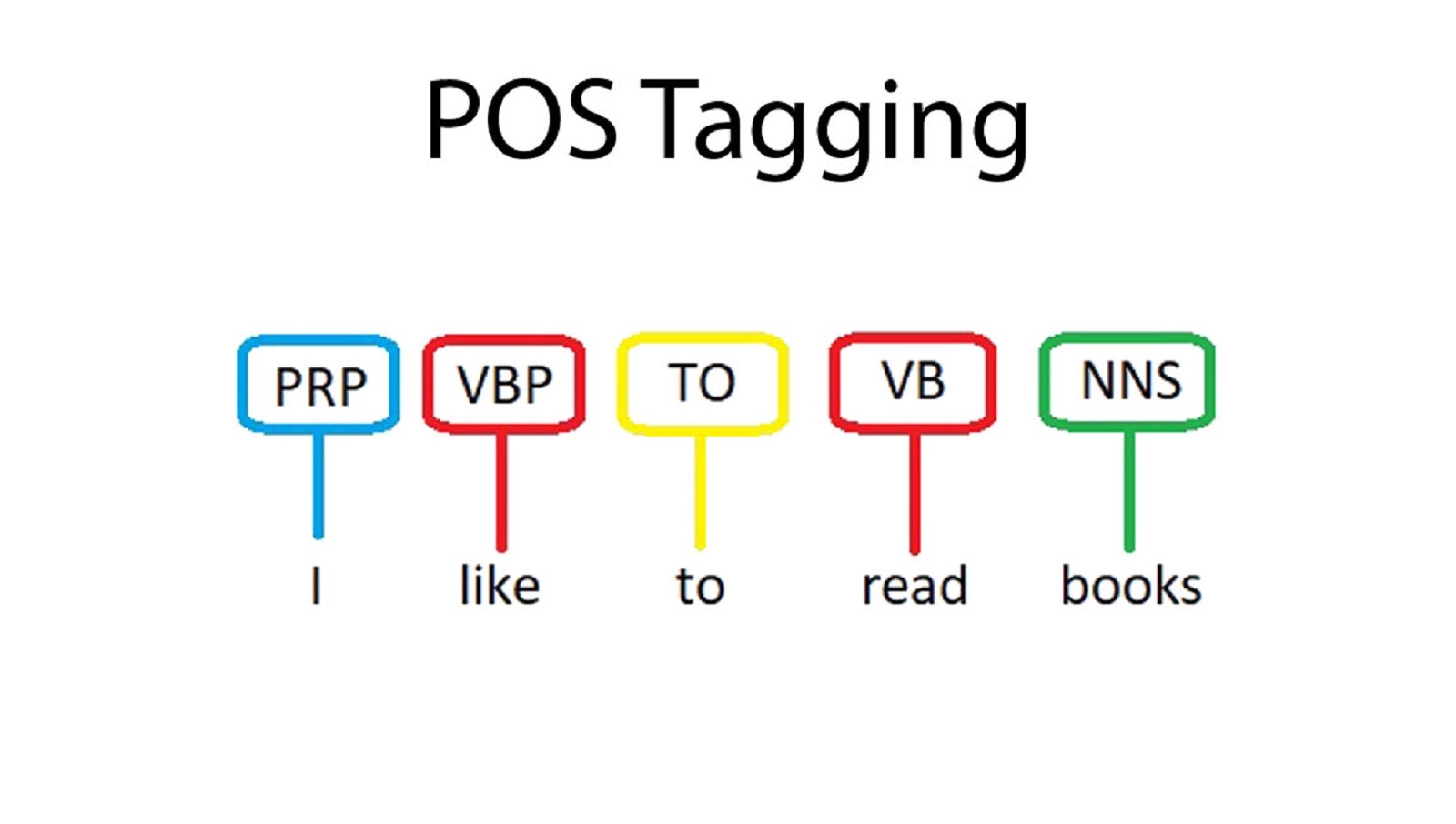
Part-of-Speech (POS) Tagging is a process used by computer programs to automatically identify the parts of speech in a given text. POS tagging is one of the fundamental steps to many natural language processing (NLP) applications such as automatic summarization, machine translation, and opinion mining.
POS tagging is a supervised learning task where a model must be pre-trained with a corpus of labeled sentences. The model must then identify the part of speech for each word in a given sentence. This is commonly done using Hidden Markov Models (HMMs) which incorporate contextual information to perform the labeling more accurately.
POS tagging can also be accomplished using a range of other approaches such as rules-based systems and stochastic methods. A rule-based approach uses a set of predetermined rules and statistic to assign labels for each word. Stochastic methods use algorithms such as Maximum Entropy and Conditional Random Fields to identify the words by making probabilistic calculations.
POS tagging is a key component in text processing technique which is used in many real-world applications such as information extraction, sentiment analysis, and speech recognition. This technology is highly beneficial for tasks that involve understanding and analyzing the text.
Overall, POS tagging is a powerful technique used for natural language processing applications. By assigning parts of speech to each word in a given sentence, the model can effectively understand the context and determine the most suitable results based on the semantic analysis.
