



Immaginati come un esploratore avventuroso, che si tuffa a capofitto nel vasto e misterioso regno dell'Amazzonia, non nella foresta pluviale, ma nel gigante della vendita al dettaglio online. Con ogni clic scopri tesori inestimabili, addentrandoti sempre più nel territorio inesplorato dei dati.
In questa emozionante spedizione, presentiamo una guida passo passo per navigare nella fitta giungla digitale del web scraping di Amazon. Preparati a intraprendere un viaggio come nessun altro, armato dei consigli e dei trucchi degli esperti per estrarre informazioni preziose con una precisione senza pari.
Sommario
- Quali dati recuperare da Amazon
- Alcuni requisiti di base
- Impostazione per lo scraping
- Raccolta di informazioni sui prodotti Amazon
- Come raschiare più pagine su Amazon
- Raschiare Amazon: domande frequenti
- Conclusione
Quindi raccogli il tuo coraggio, allaccia i tuoi stivali virtuali e iniziamo insieme la nostra avventura basata sui dati!
Quali dati recuperare da Amazon
Esistono numerosi dati associati a un prodotto Amazon, ma gli elementi chiave su cui concentrarsi durante lo scraping includono:
- Titolo del prodotto
- Costo
- Risparmio (se applicabile)
- Riepilogo articolo
- Elenco delle funzionalità associate (se disponibile)
- Punteggio della revisione
- Immagini del prodotto
Sebbene questi siano gli aspetti principali da considerare quando si recupera un articolo Amazon, è importante notare che le informazioni estratte possono variare a seconda dei tuoi obiettivi specifici.
Alcuni requisiti di base
Per preparare una zuppa abbiamo bisogno degli ingredienti giusti. Allo stesso modo, il nostro nuovo raschietto web richiede componenti specifici.
- Pitone — La sua facilità d'uso e l'ampia raccolta di librerie rendono Python la scelta migliore per il web scraping. Se non è già installato, fare riferimento a questa guida.
- BeautifulSoup — Questa è una delle tante librerie di web scraping disponibili per Python. La sua semplicità e il suo utilizzo pulito lo rendono una scelta popolare per il web scraping. Dopo aver installato con successo Python, puoi installare Beautiful Soup eseguendo: pip install bs4
- Comprensione di base dei tag HTML — Consulta questo tutorial per acquisire le conoscenze necessarie sui tag HTML.
- Programma di navigazione in rete — Poiché dobbiamo filtrare molte informazioni irrilevanti da un sito Web, sono necessari ID e tag specifici a scopo di filtraggio. Un browser web come Google Chrome o Mozilla Firefox è utile per identificare questi tag.
Impostazione per lo scraping
Per iniziare, assicurati di avere Python installato. Se non disponi di Python 3.8 o successivo, visita python.org per scaricare e installare la versione più recente.
Successivamente, crea una directory per archiviare i file del codice di web scraping per Amazon. In genere è una buona idea creare un ambiente virtuale per il tuo progetto.
Utilizza i seguenti comandi per creare e attivare un ambiente virtuale su macOS e Linux:
$ python3 -m venv .env
$ source .env/bin/activatePer gli utenti Windows, i comandi saranno leggermente diversi:
d:amazon>python -m venv .env
d:amazon>.envscriptsactivateOra è il momento di installare i pacchetti Python necessari.
Avrai bisogno di pacchetti per due attività principali: ottenere l'HTML e analizzarlo per estrarre i dati rilevanti.
La libreria Requests è una libreria Python di terze parti ampiamente utilizzata per effettuare richieste HTTP. Offre un'interfaccia semplice e intuitiva per effettuare richieste HTTP ai server Web e ricevere risposte. È forse la libreria più conosciuta per il web scraping.
Tuttavia, la libreria Richieste ha una limitazione: restituisce la risposta HTML come una stringa, che può essere difficile da cercare per elementi specifici come l'elenco dei prezzi durante la scrittura del codice web scraping.
È qui che entra in gioco Beautiful Soup. Beautiful Soup è una libreria Python progettata per il web scraping che estrae dati da file HTML e XML. Ti consente di recuperare informazioni da una pagina web cercando tag, attributi o testo specifico.
Per installare entrambe le librerie, utilizzare il seguente comando:
$ python3 -m pip install requests beautifulsoup4Per gli utenti Windows, sostituire 'python3' con 'python', mantenendo lo stesso il resto del comando:
d:amazon>python -m pip install requests beautifulsoup4Tieni presente che stiamo installando la versione 4 della libreria Beautiful Soup.
Ora testiamo la libreria di scraping Richieste. Crea un nuovo file chiamato amazon.py e inserisci il seguente codice:
import requests
url = 'https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L'
response = requests.get(url)
print(response.text)Salvare il file ed eseguirlo dal terminale.
$ python3 amazon.pyNella maggior parte dei casi, non sarai in grado di visualizzare l'HTML desiderato. Amazon bloccherà la richiesta e riceverai la seguente risposta:
To discuss automated access to Amazon data please contact [email protected].Se stampi il file Response.status_code, vedrai che riceverai un errore 503 invece di un codice di successo 200.
Amazon sa che questa richiesta non proviene da un browser e la blocca. Questa pratica è comune tra molti siti web. Amazon potrebbe bloccare le tue richieste e restituire un codice di errore che inizia con 500 o talvolta anche 400.
Una soluzione semplice è inviare intestazioni con la richiesta che imitano quelle inviate da un browser.
A volte è sufficiente inviare solo lo user-agent. Altre volte, potrebbe essere necessario inviare intestazioni aggiuntive, come l'intestazione accetta-lingua.
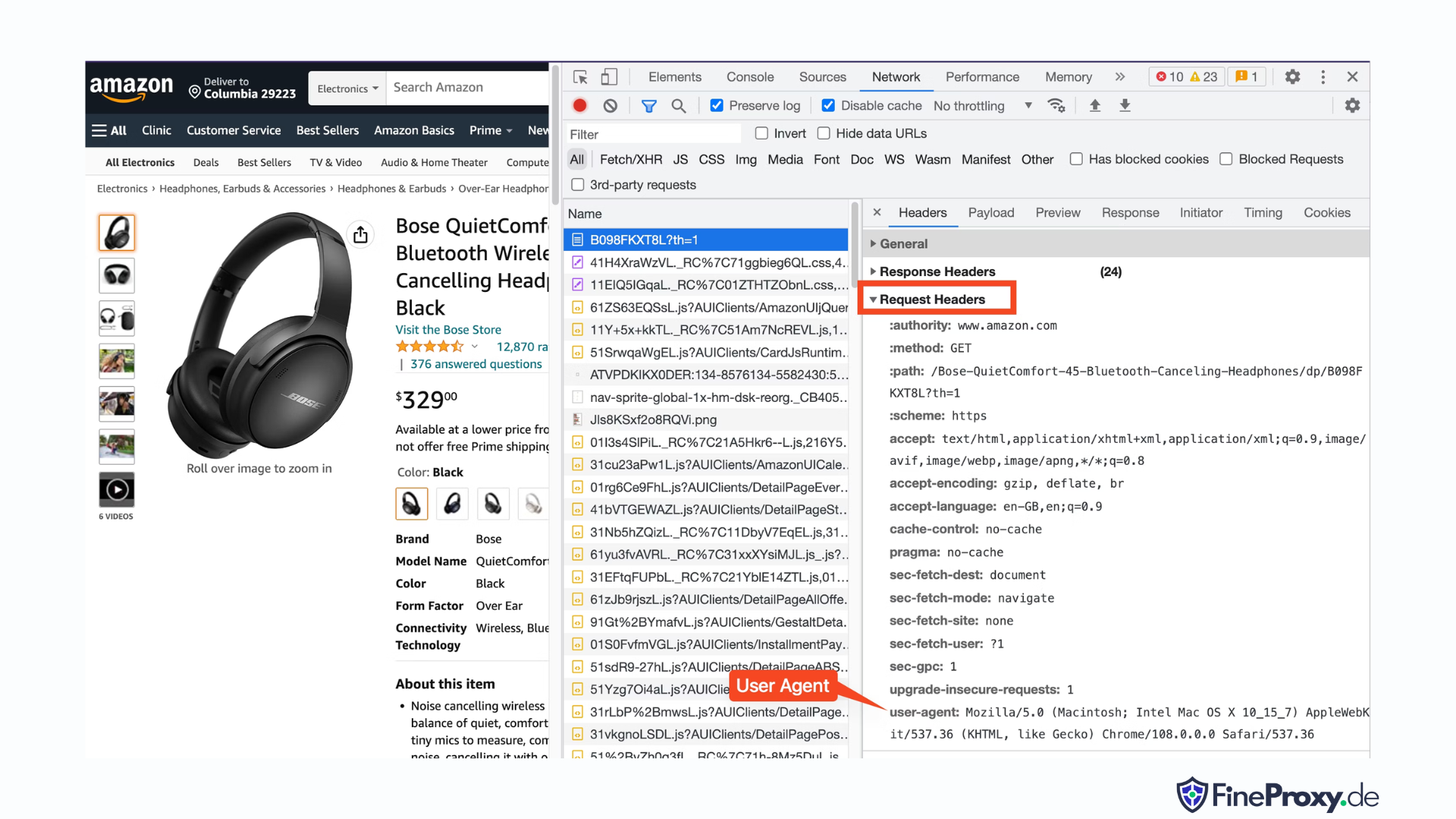
Per trovare lo user-agent inviato dal tuo browser, premi F12, apri la scheda Rete e ricarica la pagina. Seleziona la prima richiesta ed esamina le intestazioni della richiesta.
Copia questo user-agent e crea un dizionario per le intestazioni, come in questo esempio con le intestazioni user-agent e accetta-lingua:
custom_headers = { '
user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'accept-language': 'en-GB,en;q=0.9',
}Puoi quindi inviare questo dizionario come parametro opzionale nel metodo get:
response = requests.get(url, headers=custom_headersRaccolta di informazioni sui prodotti Amazon
Nel processo di web scraping dei prodotti Amazon, in genere interagirai con due tipi di pagine: la pagina delle categorie e la pagina dei dettagli del prodotto.
Ad esempio, visita https://www.amazon.com/b?node=12097479011 oppure cerca le cuffie over-ear su Amazon. La pagina che visualizza i risultati della ricerca è nota come pagina delle categorie.
La pagina della categoria presenta il titolo del prodotto, l'immagine del prodotto, la valutazione del prodotto, il prezzo del prodotto e, soprattutto, la pagina degli URL del prodotto. Per accedere a ulteriori informazioni, come le descrizioni dei prodotti, è necessario visitare la pagina dei dettagli del prodotto.
Analizziamo la struttura della pagina dei dettagli del prodotto.
Apri l'URL di un prodotto, ad esempio https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L, utilizzando Chrome o un altro browser moderno. Fai clic con il pulsante destro del mouse sul titolo del prodotto e scegli Ispeziona. Il markup HTML del titolo del prodotto verrà evidenziato.
Noterai che è un tag span con il suo attributo id impostato su "productTitle".

Allo stesso modo, fai clic con il pulsante destro del mouse sul prezzo e seleziona Controlla per visualizzare il markup HTML del prezzo.
La componente in dollari del prezzo si trova in un tag span con la classe “a-price-whole”, mentre la componente in centesimi si trova in un altro tag span con la classe “a-price-fraction”.

Puoi anche individuare la valutazione, l'immagine e la descrizione nello stesso modo.
Una volta raccolte queste informazioni, aggiungi le seguenti righe al codice esistente:
response = requests.get(url, headers=custom_headers)
soup = BeautifulSoup(response.text, 'lxml')Beautiful Soup offre un metodo distinto per selezionare i tag utilizzando i metodi di ricerca. In alternativa supporta anche i selettori CSS. È possibile utilizzare entrambi gli approcci per ottenere lo stesso risultato. In questo tutorial utilizzeremo i selettori CSS, un metodo universale per selezionare gli elementi. I selettori CSS sono compatibili con quasi tutti gli strumenti di web scraping per estrarre informazioni sui prodotti Amazon.
Ora sei pronto per utilizzare l'oggetto Soup per eseguire query su informazioni specifiche.
Estrazione del nome del prodotto
Il nome o il titolo del prodotto si trova in un elemento span con l'ID "productTitle". Selezionare gli elementi utilizzando ID univoci è semplice.
Considera il seguente codice come esempio:
title_element = soup.select_one('#productTitle') Passiamo il selettore CSS al metodo select_one, che restituisce un'istanza dell'elemento.
Per estrarre informazioni dal testo, utilizzare l'attributo text.
title = title_element.textUna volta stampato, potresti notare alcuni spazi bianchi. Per risolvere questo problema, aggiungi una chiamata alla funzione .strip() come segue:
title = title_element.text.strip()Estrazione delle valutazioni dei prodotti
Ottenere le valutazioni dei prodotti Amazon richiede uno sforzo aggiuntivo.
Innanzitutto, stabilisci un selettore per la valutazione:
#acrPopoverSuccessivamente, utilizza la seguente istruzione per selezionare l'elemento contenente la valutazione:
rating_element = soup.select_one('#acrPopover')Tieni presente che il valore effettivo della valutazione si trova all'interno dell'attributo titolo:
rating_text = rating_element.attrs.get('title')
print(rating_text)
# prints '4.6 out of 5 stars'Infine, utilizza il metodo di sostituzione per ottenere la valutazione numerica:
rating = rating_text.replace('out of 5 stars', '')Estrazione del prezzo del prodotto
Il prezzo del prodotto può essere trovato in due posizioni: sotto il titolo del prodotto e all'interno della casella Acquista ora.
Entrambi questi tag possono essere utilizzati per racimolare i prezzi dei prodotti Amazon.
Crea un selettore CSS per il prezzo:
#price_inside_buyboxPassa questo selettore CSS al metodo select_one di BeautifulSoup in questo modo:
price_element = soup.select_one('#price_inside_buybox')Ora puoi stampare il prezzo:
print(price_element.text)Estrazione dell'immagine
Per raschiare l'immagine predefinita, utilizzare il selettore CSS #landingImage. Con queste informazioni, puoi scrivere le seguenti righe di codice per ottenere l'URL dell'immagine dall'attributo src:
image_element = soup.select_one('#landingImage')
image = image_element.attrs.get('src')Estrazione della descrizione del prodotto
Il passaggio successivo nell'estrazione dei dati del prodotto Amazon è ottenere la descrizione del prodotto.
Il processo rimane coerente: crea un selettore CSS e utilizza il metodo select_one.
Il selettore CSS per la descrizione è:
#productDescriptionQuesto ci permette di estrarre l'elemento come segue:
description_element = soup.select_one('#productDescription')
print(description_element.text)Gestione dell'elenco dei prodotti
Abbiamo esplorato la possibilità di recuperare informazioni sul prodotto, ma dovrai iniziare con l'elenco dei prodotti o le pagine delle categorie per accedere ai dati del prodotto.
Per esempio, https://www.amazon.com/b?node=12097479011 è la pagina della categoria delle cuffie over-ear.
Se esamini questa pagina, vedrai che tutti i prodotti sono contenuti all'interno di un div che ha un attributo univoco [data-asin]. All'interno di quel div, tutti i collegamenti ai prodotti si trovano in un tag h2.
Con queste informazioni, il selettore CSS è:
[data-asin] h2 aPuoi leggere l'attributo href di questo selettore ed eseguire un ciclo. Tuttavia, ricorda che i collegamenti saranno relativi. Dovrai utilizzare il metodo urljoin per analizzare questi collegamenti.
from urllib.parse import urljoin
...
def parse_listing(listing_url):
…
link_elements = soup_search.select("[data-asin] h2 a")
page_data = []
for link in link_elements:
full_url = urljoin(search_url, link.attrs.get("href"))
product_info = get_product_info(full_url)
page_data.append(product_info)Gestione dell'impaginazione
Il collegamento alla pagina successiva si trova in un collegamento contenente il testo "Avanti". Puoi cercare questo collegamento utilizzando l'operatore contiene del CSS come segue:
next_page_el = soup.select_one('a:contains("Next")')
if next_page_el:
next_page_url = next_page_el.attrs.get('href')
next_page_url = urljoin(listing_url, next_page_url)Esportazione dei dati di Amazon
I dati raschiati vengono restituiti intenzionalmente come dizionario. Puoi creare una lista contenente tutti i prodotti raschiati.
def parse_listing(listing_url):
...
page_data = [] for link in link_elements:
...
product_info = get_product_info(full_url)
page_data.append(product_info)È quindi possibile utilizzare questo page_data per creare un oggetto Pandas DataFrame:
df = pd.DataFrame(page_data)
df.to_csv('headphones.csv', index = False)Come raschiare più pagine su Amazon
Lo scraping di più pagine su Amazon può migliorare l'efficacia del tuo progetto di web scraping fornendo un set di dati più ampio da analizzare. Quando scegli come target più pagine, dovrai considerare l'impaginazione, che è il processo di divisione del contenuto su più pagine.
Ecco 6 punti chiave da tenere a mente quando si raschiano più pagine su Amazon:
- Identificare il modello di impaginazione: Innanzitutto, analizza la struttura dell'URL della categoria o delle pagine dei risultati di ricerca per capire come Amazon impagina i suoi contenuti. Potrebbe trattarsi di un parametro di query (ad esempio, "?pagina=2") o di un identificatore univoco incorporato nell'URL.
- Estrai il collegamento alla pagina “Avanti”: Individua l'elemento (solitamente un tag di ancoraggio) contenente il collegamento alla pagina successiva. Utilizza il selettore CSS appropriato o il metodo Beautiful Soup per estrarre l'attributo href di questo elemento, che è l'URL per la pagina successiva.
- Converti URL relativi in URL assoluti: Poiché gli URL estratti potrebbero essere relativi, utilizzare il file
urljoinfunzione daurllib.parselibreria per convertirli in URL assoluti. - Crea un ciclo: Implementa un ciclo che scorre le pagine, estraendo i dati desiderati da ciascuna di esse. Il ciclo dovrebbe continuare finché non rimangono più pagine, cosa che può essere determinata controllando se il collegamento alla pagina "Avanti" esiste nella pagina corrente.
- Aggiungi ritardi tra le richieste: Per evitare di sovraccaricare il server di Amazon o di attivare misure anti-bot, introdurre ritardi tra le richieste utilizzando il file
time.sleep()funzione datimebiblioteca. Regola la durata del ritardo per emulare il comportamento di navigazione umana. - Gestire CAPTCHA e blocchi: Se riscontri CAPTCHA o blocchi IP durante lo scraping di più pagine, prendi in considerazione l'utilizzo di proxy per ruotare gli indirizzi IP o strumenti e servizi di scraping dedicati in grado di gestire queste sfide automaticamente.
Di seguito troverai un tutorial video completo di YouTube che ti guida attraverso il processo di estrazione dei dati da più pagine sul sito Web di Amazon. Il tutorial approfondisce il mondo del web scraping, concentrandosi sulle tecniche che ti consentiranno di raccogliere in modo efficiente ed efficace informazioni preziose da numerose pagine di Amazon.
Nel corso del tutorial, il relatore dimostra l'uso di strumenti e librerie essenziali, come Python, BeautifulSoup e richieste, evidenziando al contempo le migliori pratiche per evitare di essere bloccati o rilevati dai meccanismi anti-bot di Amazon. Il video tratta argomenti essenziali come la gestione dell'impaginazione, la gestione dei limiti di velocità e l'imitazione del comportamento di navigazione umano.
Oltre alle istruzioni dettagliate fornite nel video, il tutorial condivide anche suggerimenti e trucchi utili per ottimizzare la tua esperienza di web scraping. Questi includono l'utilizzo di proxy per aggirare le restrizioni IP, la randomizzazione di User-Agent e intestazioni delle richieste e l'implementazione di una corretta gestione degli errori per garantire un processo di scraping fluido e ininterrotto.
Raschiare Amazon: domande frequenti
Quando si tratta di estrarre dati da Amazon, una popolare piattaforma di e-commerce, ci sono alcune cose di cui bisogna tenere conto. Immergiamoci nelle domande più frequenti relative allo scraping dei dati di Amazon.
1. È legale raschiare Amazon?
Lo scraping dei dati disponibili al pubblico da Internet è legale e ciò include lo scraping di Amazon. Puoi raccogliere legalmente informazioni come dettagli del prodotto, descrizioni, valutazioni e prezzi. Tuttavia, quando elimini le recensioni dei prodotti, dovresti essere cauto con la protezione dei dati personali e del copyright. Ad esempio, il nome e l'avatar del recensore potrebbero costituire dati personali, mentre il testo della recensione potrebbe essere protetto da copyright. Prestare sempre attenzione e chiedere consulenza legale quando si estraggono tali dati.
2. Amazon consente lo scraping?
Sebbene lo scraping dei dati disponibili al pubblico sia legale, Amazon a volte adotta misure per prevenirlo. Queste misure includono richieste di limitazione della velocità, divieto di indirizzi IP e utilizzo del rilevamento delle impronte digitali del browser per rilevare i bot di scraping. Amazon solitamente blocca il web scraping con un codice di risposta dello stato di successo 200 OK e richiede di passare un CAPTCHA o mostra un messaggio di errore HTTP 503 Servizio non disponibile per contattare le vendite per un'API a pagamento.
Esistono modi per aggirare queste misure, ma il web scraping etico può aiutare a evitare di innescarle. Lo scraping etico del web implica la limitazione della frequenza delle richieste, l'utilizzo di user agent appropriati ed evitare uno scraping eccessivo che potrebbe influire sulle prestazioni del sito web. Effettuando lo scraping in modo etico, puoi ridurre il rischio di essere bandito o di dover affrontare conseguenze legali pur estraendo dati utili da Amazon.
3. È etico raschiare i dati di Amazon?
Lo scraping etico implica il rispetto del sito web di destinazione. Anche se è improbabile che sovraccaricherai il sito web di Amazon con troppe richieste, dovresti comunque seguire le linee guida etiche sullo scraping. Il raschiamento etico può ridurre al minimo il rischio di affrontare questioni legali o di dover affrontare misure anti-raschiamento.
4. Come posso evitare di essere bannato durante lo scraping di Amazon?
Per evitare di essere bannato durante lo scraping di Amazon, dovresti limitare i tassi di richiesta, evitare lo scraping durante le ore di punta, utilizzare la rotazione proxy intelligente e utilizzare user agent e intestazioni appropriati per evitare il rilevamento. Inoltre, estrai solo i dati necessari e utilizza strumenti di scraping di terze parti o librerie di scraping.
5. Quali sono i rischi di eliminare Amazon?
L'eliminazione dei dati di Amazon comporta rischi potenziali, come azioni legali e sospensione dell'account. Amazon utilizza misure anti-bot per rilevare e prevenire lo scraping, inclusi divieti di indirizzi IP, limitazioni di velocità e impronte digitali del browser. Tuttavia, raschiando eticamente è possibile mitigare questi rischi.
Conclusione
Mentre emergiamo dall'avvincente labirinto del web scraping di Amazon, è tempo di prendersi un momento per apprezzare le preziose conoscenze e abilità che abbiamo raccolto in questo esaltante viaggio. Con ProxyCompass come guida fidata, hai attraversato con successo i colpi di scena dell'estrazione di dati inestimabili dal colosso della vendita al dettaglio. Mentre ti avventuri, esercitando la tua nuova esperienza con finezza, ricorda che la giungla digitale non smette mai di evolversi.
Rimani curioso, continua ad affilare il tuo machete per il web scraping e continua a conquistare il panorama in continua evoluzione dell'estrazione dei dati. Fino alla prossima audace spedizione, intrepido esploratore, possano le tue ricerche basate sui dati essere fruttuose e gratificanti!

