



熱帯雨林ではなく、オンライン小売業の巨人であるアマゾンの広大で神秘的な世界に飛び込む冒険好きな探検家になった自分を想像してみてください。クリックするたびに、貴重な宝物を発見し、データの未知の領域をさらに深く探究します。
このスリリングな探検では、Amazon Web スクレイピングの密集したデジタル ジャングルをナビゲートするためのステップバイステップのガイドを紹介します。貴重な情報を比類のない精度で抽出するための専門家のヒントとコツを備えて、他に類を見ない旅に乗り出す準備をしましょう。
目次
- Amazonからスクレイピングするデータ
- 基本的な要件
- スクレイピングの設定
- Amazon 製品情報のスクレイピング
- Amazon で複数のページをスクレイピングする方法
- Amazonのスクレイピング: よくある質問
- 結論
さあ、勇気を振り絞って、仮想ブーツを履いて、データ駆動型の冒険を一緒に始めましょう!
Amazonからスクレイピングするデータ
Amazon 製品には多数のデータ ポイントが関連付けられていますが、スクレイピング時に重点を置くべき主な要素は次のとおりです。
- 製品タイトル
- 料金
- 貯蓄(該当する場合)
- 項目概要
- 関連機能リスト(利用可能な場合)
- レビュースコア
- 製品のビジュアル
これらは Amazon の商品をスクレイピングするときに考慮すべき主な側面ですが、抽出する情報は特定の目的に応じて異なる場合があることに注意することが重要です。
基本的な要件
スープを作るには、適切な材料が必要です。同様に、新しい Web スクレーパーにも特定のコンポーネントが必要です。
- パイソン — Python は使いやすさと豊富なライブラリ コレクションにより、Web スクレイピングの第一の選択肢となっています。まだインストールされていない場合は、このガイドを参照してください。
- BeautifulSoup — これは、Pythonで利用できる多くのWebスクレイピングライブラリの1つです。そのシンプルさとクリーンな使用法により、Webスクレイピングの人気のある選択肢となっています。Pythonのインストールに成功したら、次のコマンドを実行してBeautiful Soupをインストールできます:pip install bs4
- HTML タグの基本的な理解 — HTML タグについて必要な知識を得るには、このチュートリアルを参照してください。
- ウェブブラウザ — ウェブサイトから多くの無関係な情報をフィルタリングする必要があるため、フィルタリングには特定の ID とタグが必要です。Google Chrome や Mozilla Firefox などのウェブブラウザは、これらのタグを識別するのに役立ちます。
スクレイピングの設定
まず、Python がインストールされていることを確認してください。 Python 3.8 以降をお持ちでない場合は、python.org にアクセスして最新バージョンをダウンロードしてインストールしてください。
次に、Amazon の Web スクレイピング コード ファイルを保存するディレクトリを作成します。一般に、プロジェクト用に仮想環境をセットアップすることをお勧めします。
次のコマンドを使用して、macOS および Linux 上で仮想環境を作成してアクティブ化します。
$ python3 -m venv .env
$ source .env/bin/activateWindows ユーザーの場合、コマンドは少し異なります。
d:amazon>python -m venv .env
d:amazon>.envscriptsactivate次に、必要な Python パッケージをインストールします。
HTML を取得し、それを解析して関連データを抽出するという 2 つの主なタスク用のパッケージが必要になります。
Requests ライブラリは、HTTP リクエストを行うために広く使用されているサードパーティの Python ライブラリです。Web サーバーに HTTP リクエストを行い、応答を受信するための簡単で使いやすいインターフェイスを提供します。これは、おそらく Web スクレイピング用の最もよく知られているライブラリです。
ただし、Requests ライブラリには制限があります。HTML 応答を文字列として返すため、Web スクレイピング コードを作成するときに、リスト価格などの特定の要素を検索するのが難しい場合があります。
そこで Beautiful Soup の出番です。 Beautiful Soup は、HTML および XML ファイルからデータを抽出する Web スクレイピング用に設計された Python ライブラリです。タグ、属性、または特定のテキストを検索して、Web ページから情報を取得できます。
両方のライブラリをインストールするには、次のコマンドを使用します。
$ python3 -m pip install requests beautifulsoup4Windows ユーザーの場合は、「python3」を「python」に置き換え、コマンドの残りの部分はそのままにします。
d:amazon>python -m pip install requests beautifulsoup4Beautiful Soup ライブラリのバージョン 4 をインストールしていることに注意してください。
次に、Requests スクレイピング ライブラリをテストしましょう。 amazon.py という名前の新しいファイルを作成し、次のコードを入力します。
import requests
url = 'https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L'
response = requests.get(url)
print(response.text)ファイルを保存し、ターミナルから実行します。
$ python3 amazon.pyほとんどの場合、目的の HTML を表示することはできません。 Amazon はリクエストをブロックし、次の応答を受け取ります。
To discuss automated access to Amazon data please contact [email protected].response.status_code を出力すると、成功コード 200 ではなく 503 エラーが返されることがわかります。
Amazon は、このリクエストがブラウザからのものではないことを認識し、リクエストをブロックします。この方法は、多くの Web サイトで一般的です。Amazon はリクエストをブロックし、500 または場合によっては 400 で始まるエラー コードを返すことがあります。
簡単な解決策は、ブラウザーによって送信されるヘッダーを模倣したヘッダーをリクエストとともに送信することです。
場合によっては、ユーザーエージェントのみを送信するだけで十分です。また、accept-language ヘッダーなどの追加のヘッダーを送信する必要がある場合もあります。
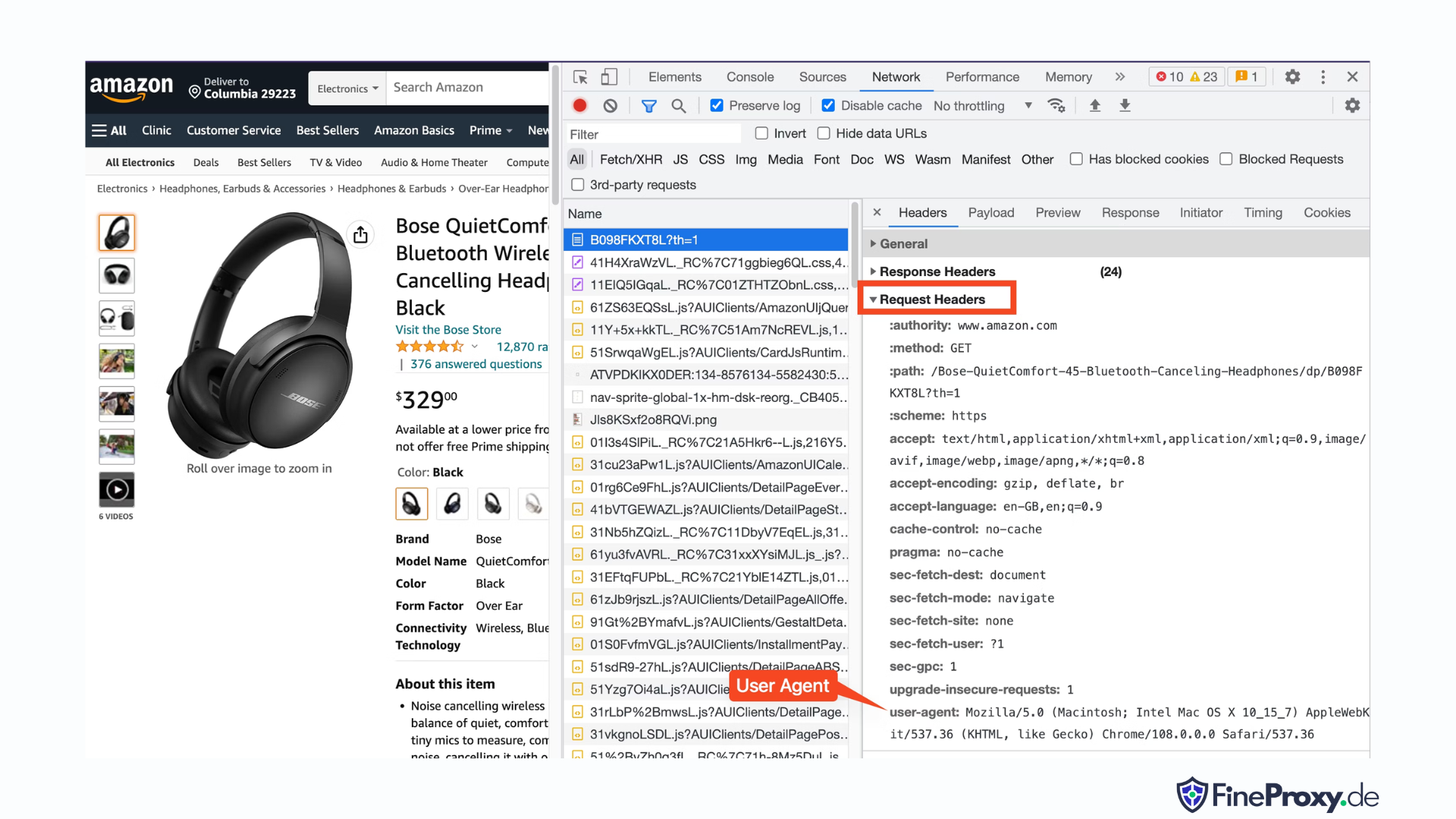
ブラウザから送信されたユーザー エージェントを見つけるには、F12 キーを押して、[ネットワーク] タブを開き、ページをリロードします。最初のリクエストを選択し、リクエスト ヘッダーを調べます。
このユーザー エージェントをコピーし、ユーザー エージェントと受け入れ言語ヘッダーを含む次の例のように、ヘッダーの辞書を作成します。
custom_headers = { '
user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'accept-language': 'en-GB,en;q=0.9',
}その後、この辞書を get メソッドのオプションのパラメーターとして送信できます。
response = requests.get(url, headers=custom_headersAmazon 製品情報のスクレイピング
Amazon 製品を Web スクレイピングするプロセスでは、通常、カテゴリ ページと製品詳細ページの 2 種類のページを使用します。
例えば、 https://www.amazon.com/b?node=12097479011 または、Amazon でオーバーイヤー ヘッドフォンを検索します。検索結果が表示されるページは、カテゴリ ページと呼ばれます。
カテゴリ ページには、製品タイトル、製品画像、製品評価、製品価格、そして最も重要な製品 URL ページが表示されます。製品説明などの詳細情報にアクセスするには、製品詳細ページにアクセスする必要があります。
商品詳細ページの構造を分析してみましょう。
次のような製品URLを開きます https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8LChrome または他の最新のブラウザを使用します。製品タイトルを右クリックし、[検査] を選択します。製品タイトルの HTML マークアップが強調表示されます。
これは span タグであり、その id 属性が「productTitle」に設定されていることがわかります。

同様に、価格を右クリックして「検査」を選択すると、価格の HTML マークアップが表示されます。
価格のドル部分はクラス「a-price-whole」のスパン タグにあり、セント部分はクラス「a-price-fraction」の別のスパン タグにあります。

同様の方法で、評価、画像、説明を見つけることもできます。
この情報を収集したら、既存のコードに次の行を追加します。
response = requests.get(url, headers=custom_headers)
soup = BeautifulSoup(response.text, 'lxml')Beautiful Soup は、find メソッドを使用してタグを選択する独特の方法を提供します。代替手段として CSS セレクターもサポートしています。どちらのアプローチを使用しても、同じ結果を達成できます。このチュートリアルでは、要素を選択するための普遍的な方法である CSS セレクターを利用します。 CSS セレクターは、Amazon 製品情報を抽出するためのほぼすべての Web スクレイピング ツールと互換性があります。
これで、Soup オブジェクトを使用して特定の情報を照会する準備が整いました。
製品名の抽出
製品名またはタイトルは、ID が「productTitle」の span 要素にあります。一意の ID を使用して要素を選択するのは簡単です。
例として次のコードを考えてみましょう。
title_element = soup.select_one('#productTitle') CSS セレクターを select_one メソッドに渡すと、要素インスタンスが返されます。
テキストから情報を抽出するには、テキスト属性を使用します。
title = title_element.text印刷すると、いくつかの空白が現れる場合があります。これを解決するには、次のように .strip() 関数呼び出しを追加します。
title = title_element.text.strip()製品評価の抽出
Amazon 製品の評価を取得するには、追加の労力が必要です。
まず、評価のセレクターを確立します。
#acrPopover次に、次のステートメントを使用して、評価を含む要素を選択します。
rating_element = soup.select_one('#acrPopover')実際の評価値は title 属性内に記載されていることに注意してください。
rating_text = rating_element.attrs.get('title')
print(rating_text)
# prints '4.6 out of 5 stars'最後に、replace メソッドを使用して数値評価を取得します。
rating = rating_text.replace('out of 5 stars', '')製品価格の抽出
製品価格は、製品タイトルの下と [今すぐ購入] ボックス内の 2 か所で確認できます。
これらのタグはどちらも、Amazon 製品の価格をスクレイピングするために利用できます。
価格の CSS セレクターを作成します。
#price_inside_buyboxこの CSS セレクターを BeautifulSoup の select_one メソッドに次のように渡します。
price_element = soup.select_one('#price_inside_buybox')これで、価格を印刷できます。
print(price_element.text)画像の抽出
デフォルトの画像をスクレイピングするには、CSS セレクター #landingImage を使用します。この情報を使用して、次のコード行を記述して、src 属性から画像 URL を取得できます。
image_element = soup.select_one('#landingImage')
image = image_element.attrs.get('src')製品説明の抽出
Amazon 商品データを抽出する次のステップは、商品説明を取得することです。
プロセスは一貫しており、CSS セレクターを作成し、select_one メソッドを使用します。
説明の CSS セレクターは次のとおりです。
#productDescriptionこれにより、次のように要素を抽出できるようになります。
description_element = soup.select_one('#productDescription')
print(description_element.text)取り扱い商品一覧
製品情報のスクレイピングについて説明しましたが、製品データにアクセスするには、製品リストまたはカテゴリ ページから開始する必要があります。
例えば、 https://www.amazon.com/b?node=12097479011 オーバーイヤーヘッドホンのカテゴリーページです。
このページを調べると、すべての製品が一意の属性 [data-asin] を持つ div 内に含まれていることがわかります。その div 内では、すべての製品リンクが h2 タグ内にあります。
この情報により、CSS セレクターは次のようになります。
[data-asin] h2 aこのセレクターの href 属性を読み取り、ループを実行できます。ただし、リンクは相対的なものであることに注意してください。これらのリンクを解析するには、urljoin メソッドを使用する必要があります。
from urllib.parse import urljoin
...
def parse_listing(listing_url):
…
link_elements = soup_search.select("[data-asin] h2 a")
page_data = []
for link in link_elements:
full_url = urljoin(search_url, link.attrs.get("href"))
product_info = get_product_info(full_url)
page_data.append(product_info)ページネーションの処理
次のページへのリンクは「次へ」という文字を含むリンク内にあります。次のように CSS の contains 演算子を使用してこのリンクを検索できます。
next_page_el = soup.select_one('a:contains("Next")')
if next_page_el:
next_page_url = next_page_el.attrs.get('href')
next_page_url = urljoin(listing_url, next_page_url)Amazon データのエクスポート
スクレイピングしたデータを意図的に辞書として返します。スクレイピングされたすべての製品を含むリストを作成できます。
def parse_listing(listing_url):
...
page_data = [] for link in link_elements:
...
product_info = get_product_info(full_url)
page_data.append(product_info)次に、この page_data を使用して Pandas DataFrame オブジェクトを作成できます。
df = pd.DataFrame(page_data)
df.to_csv('headphones.csv', index = False)Amazon で複数のページをスクレイピングする方法
Amazon の複数のページをスクレイピングすると、分析するデータセットが広くなり、Web スクレイピング プロジェクトの有効性を高めることができます。複数のページをターゲットにする場合は、コンテンツを複数のページに分割するプロセスであるページネーションを考慮する必要があります。
ここにあります 留意すべき6つの重要なポイント Amazon で複数のページをスクレイピングする場合:
- ページネーションパターンを識別します。 まず、カテゴリまたは検索結果ページの URL 構造を分析して、Amazon がコンテンツのページネーションを行う方法を理解します。これは、クエリ パラメータ (例: 「?page=2」) または URL 内に埋め込まれた一意の識別子である可能性があります。
- 「次へ」ページのリンクを抽出します。 次のページへのリンクを含む要素 (通常はアンカー タグ) を見つけます。適切な CSS セレクターまたは Beautiful Soup メソッドを使用して、この要素の href 属性 (次のページの URL) を抽出します。
- 相対 URL を絶対 URL に変換します。 抽出された URL は相対的なものである可能性があるため、
urljoin機能からurllib.parseライブラリを使用して絶対 URL に変換します。 - ループを作成します。 ページを反復処理し、各ページから必要なデータを取得するループを実装します。ループは、現在のページに「次のページ」リンクが存在するかどうかを確認することで、ページがなくなるまで続行する必要があります。
- リクエスト間の遅延を追加します。 Amazon のサーバーに負荷がかかりすぎたり、ボット対策が発動されたりするのを避けるために、
time.sleep()機能からtime図書館。人間のブラウジング動作をエミュレートするために遅延時間を調整します。 - CAPTCHA とブロックの処理: 複数のページをスクレイピングしているときに CAPTCHA や IP ブロックが発生した場合は、プロキシを使用して IP アドレスをローテーションするか、これらの課題を自動的に処理できる専用のスクレイピング ツールやサービスを使用することを検討してください。
以下に、Amazon の Web サイトの複数のページからデータを抽出するプロセスをガイドする包括的な YouTube ビデオ チュートリアルを示します。このチュートリアルでは、Web スクレイピングの世界を深く掘り下げ、多数の Amazon ページから貴重な情報を効率的かつ効果的に収集できるテクニックに焦点を当てています。
チュートリアル全体を通じて、プレゼンターは、Python、BeautifulSoup、リクエストなどの重要なツールとライブラリの使用法をデモンストレーションしながら、Amazon のアンチボット メカニズムによるブロックや検出を回避するためのベスト プラクティスを強調します。このビデオでは、ページネーションの処理、レート制限の管理、人間のようなブラウジング動作の模倣などの重要なトピックを取り上げています。
ビデオで提供される段階的な手順に加えて、チュートリアルでは、Web スクレイピング エクスペリエンスを最適化するための役立つヒントやコツも共有します。これには、プロキシを使用して IP 制限をバイパスすること、ユーザー エージェントとリクエスト ヘッダーをランダム化すること、スムーズで中断のないスクレイピング プロセスを確保するための適切なエラー処理の実装が含まれます。
Amazonのスクレイピング: よくある質問
人気の電子商取引プラットフォームである Amazon からデータを抽出する場合、注意すべき点がいくつかあります。Amazon データのスクレイピングに関するよくある質問を詳しく見ていきましょう。
1. Amazonをスクレイピングすることは合法ですか?
インターネットから公開されているデータをスクレイピングすることは合法であり、Amazon のスクレイピングもこれに含まれます。製品の詳細、説明、評価、価格などの情報は合法的にスクレイピングできます。ただし、製品レビューをスクレイピングする場合は、個人データと著作権保護に注意する必要があります。たとえば、レビュー担当者の名前とアバターは個人データを構成する可能性があり、レビューのテキストは著作権で保護されている可能性があります。このようなデータをスクレイピングするときは常に注意を払い、法的助言を求めてください。
2. Amazon はスクレイピングを許可していますか?
公開されているデータのスクレイピングは合法ですが、Amazon はスクレイピングを防止するための対策を講じることがあります。これらの対策には、リクエストのレート制限、IP アドレスの禁止、ブラウザ フィンガープリンティングを使用したスクレイピング ボットの検出などがあります。Amazon は通常、200 OK 成功ステータス応答コードで Web スクレイピングをブロックし、CAPTCHA を渡すように要求するか、有料 API について営業に連絡するために HTTP エラー 503 サービス利用不可メッセージを表示します。
これらの措置を回避する方法はありますが、倫理的な Web スクレイピングは、そもそものトリガーを回避するのに役立ちます。倫理的な Web スクレイピングには、リクエストの頻度を制限し、適切なユーザー エージェントを使用し、Web サイトのパフォーマンスに影響を与える可能性のある過剰なスクレイピングを回避することが含まれます。倫理的にスクレイピングを行うことで、Amazon から有用なデータを抽出しながら、禁止されたり法的結果に直面したりするリスクを軽減できます。
3. Amazon データをスクレイピングするのは倫理的ですか?
倫理的なスクレイピングには、対象となる Web サイトを尊重することが含まれます。あまりにも多くのリクエストで Amazon Web サイトに過負荷がかかる可能性は低いですが、それでも倫理的なスクレイピング ガイドラインに従う必要があります。倫理的なスクレイピングにより、法的問題に直面したり、スクレイピング対策に対処したりするリスクを最小限に抑えることができます。
4. Amazon スクレイピング中に禁止されないようにするにはどうすればよいですか?
Amazon をスクレイピングするときに禁止されないようにするには、リクエスト レートを制限し、ピーク時のスクレイピングを避け、スマート プロキシ ローテーションを使用し、適切なユーザー エージェントとヘッダーを使用して検出を回避する必要があります。さらに、必要なデータのみを抽出し、サードパーティのスクレイピング ツールまたはスクレイピング ライブラリを使用します。
5. Amazon スクレイピングのリスクは何ですか?
Amazon データのスクレイピングには、法的措置やアカウント停止などの潜在的なリスクが伴います。 Amazon は、IP アドレスの禁止、レート制限、ブラウザーのフィンガープリンティングなどのボット対策措置を使用してスクレイピングを検出および防止します。ただし、倫理的にスクレイピングを行うことで、これらのリスクを軽減できます。
結論
Amazon Web スクレイピングの魅惑的な迷宮から抜け出した今、この刺激的な旅で得た貴重な知識とスキルを少し振り返ってみましょう。ProxyCompass を信頼できるガイドとして、小売業界の巨大企業から貴重なデータを抽出するという紆余曲折を乗り越えてきました。新たな専門知識を巧みに駆使して冒険を進める際には、デジタル ジャングルが進化し続けることを忘れないでください。
好奇心を持ち続け、Web スクレイピング ナタを磨き続け、刻々と変化するデータ抽出の状況を征服し続けてください。勇敢な探検家よ、次の大胆な遠征が始まるまで、あなたのデータ主導型の探求が実りある、やりがいのあるものとなりますように!

