



Knowledge Distillation is a method of teaching a machine learning model to learn from another more complex model. It enables the production of a smaller, more efficient, faster and generally better-performing model by distilling the knowledge of a bigger beautiful model, hence named knowledge distillation. It is a rapidly growing technique in the field of deep learning, as it allows existing models which have been trained on large quantities of data to be distilled into small standalone models which can be deployed more efficiently on embedded systems.
The machine learning technique known as knowledge distillation is generally used when a technique is available which has already been trained on a large data sets, and a smaller, quicker model is required to run the same task. In essence, knowledge distillation works by extracting the main concepts of a large AI model and teaching a smaller model to do the same task. The technique works by teaching the smaller model to mimic the behaviour of the larger model and by doing so, allow it to generalise more efficiently.
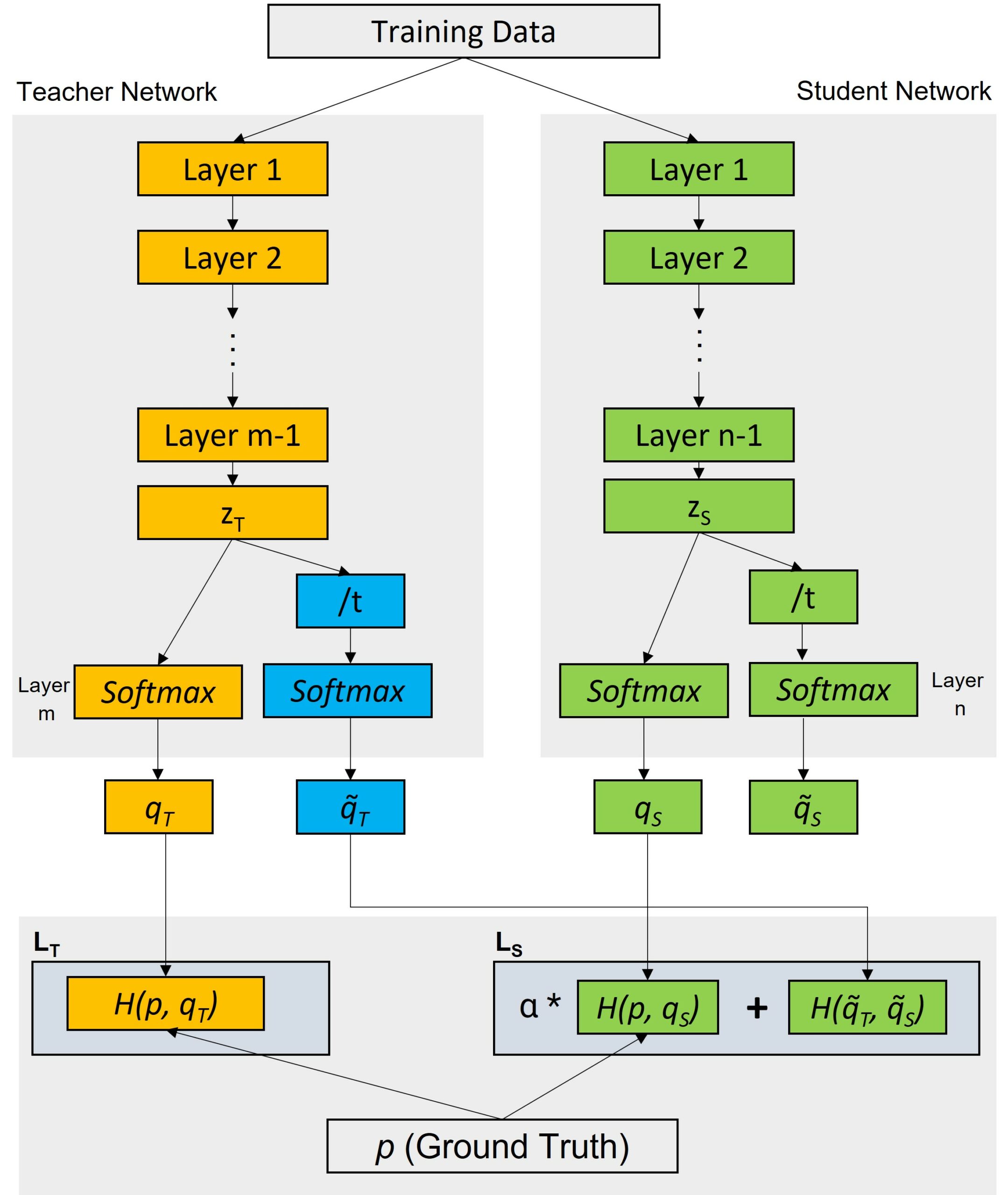
The process of knowledge distillation involves transferring the knowledge from a larger model to a smaller model that can run on mobile or embedded hardware. This is done by introducing a penalty in the training process, which encourages the smaller model to stick closer to the behaviour of the larger model.
At its core, knowledge distillation works by having a large model (the teacher) that has been trained on a large data set, and a smaller model (the student). The teacher’s output is then used to define a new loss function which is used to train the student. The objective of this new loss function is to have the student produced outputs that are as close as possible to the teacher’s outputs while using the smallest amount of computation resources.
The value of knowledge distillation lies in its ability to create smaller models that are able to replicate the performance of larger models without sacrificing accuracy. This can result in huge benefits for organizations in terms of computation and storage costs, allowing them to deploy more accurate models on a budget. Furthermore, distillation allows companies to easily utilize the knowledge already learned by large models to extend and refine their present models in a cost effective way.
