



Bayangkan diri Anda sebagai seorang penjelajah yang suka berpetualang, terjun langsung ke wilayah Amazon yang luas dan misterius—bukan hutan hujan, namun raksasa ritel online. Dengan setiap klik, Anda menemukan harta karun yang tak ternilai, menggali lebih dalam wilayah data yang belum dipetakan.
Dalam ekspedisi yang mendebarkan ini, kami menyajikan panduan langkah demi langkah untuk menavigasi hutan digital Amazon web scraping yang padat. Bersiaplah untuk memulai perjalanan yang tiada duanya, dipersenjatai dengan tips dan trik ahli untuk mengekstrak informasi berharga dengan presisi yang tak tertandingi.
Daftar isi
- Data Apa yang Harus Dikikis Dari Amazon
- Beberapa Persyaratan Dasar
- Menyiapkan untuk Menggores
- Mengikis Informasi Produk Amazon
- Cara Mengikis Banyak Halaman di Amazon
- Mengikis Amazon: FAQ
- Kesimpulan
Jadi, kumpulkan keberanian Anda, kenakan sepatu bot virtual Anda, dan mari kita mulai petualangan berbasis data bersama-sama!
Data Apa yang Harus Dikikis Dari Amazon
Ada banyak titik data yang terkait dengan produk Amazon, namun elemen kunci yang harus diperhatikan saat melakukan scraping meliputi:
- Judul Produk
- Biaya
- Tabungan (jika ada)
- Ringkasan Barang
- Daftar fitur terkait (jika tersedia)
- Skor ulasan
- Visual produk
Meskipun ini adalah aspek utama yang perlu dipertimbangkan saat mengambil item Amazon, penting untuk dicatat bahwa informasi yang Anda ekstrak mungkin berbeda-beda tergantung pada tujuan spesifik Anda.
Beberapa Persyaratan Dasar
Untuk menyiapkan sup, kita membutuhkan bahan-bahan yang tepat. Demikian pula, web scraper baru kami memerlukan komponen khusus.
- ular piton — Kemudahan penggunaan dan koleksi perpustakaannya yang luas menjadikan Python pilihan utama untuk web scraping. Jika belum terinstal, lihat panduan ini.
- BeautifulSoup — Ini adalah salah satu dari banyak perpustakaan web scraping yang tersedia untuk Python. Kesederhanaan dan penggunaannya yang bersih menjadikannya pilihan populer untuk web scraping. Setelah berhasil menginstal Python, Anda dapat menginstal Beautiful Soup dengan menjalankan: pip install bs4
- Pemahaman Dasar Tag HTML — Konsultasikan tutorial ini untuk memperoleh pengetahuan yang diperlukan tentang tag HTML.
- Peramban Web — Karena kita perlu menyaring banyak informasi yang tidak relevan dari sebuah situs web, diperlukan id dan tag khusus untuk tujuan pemfilteran. Peramban web seperti Google Chrome atau Mozilla Firefox berguna untuk mengidentifikasi tag tersebut.
Menyiapkan untuk Menggores
Untuk memulai, pastikan Anda telah menginstal Python. Jika Anda tidak memiliki Python 3.8 atau lebih baru, kunjungi python.org untuk mengunduh dan menginstal versi terbaru.
Selanjutnya, buat direktori untuk menyimpan file kode scraping web Anda untuk Amazon. Biasanya merupakan ide bagus untuk menyiapkan lingkungan virtual untuk proyek Anda.
Gunakan perintah berikut untuk membuat dan mengaktifkan lingkungan virtual di macOS dan Linux:
$ python3 -m venv .env
$ source .env/bin/activateUntuk pengguna Windows, perintahnya akan sedikit berbeda:
d:amazon>python -m venv .env
d:amazon>.envscriptsactivateSekarang saatnya menginstal paket Python yang diperlukan.
Anda memerlukan paket untuk dua tugas utama: mendapatkan HTML dan menguraikannya untuk mengekstrak data yang relevan.
Pustaka Permintaan adalah pustaka Python pihak ketiga yang banyak digunakan untuk membuat permintaan HTTP. Ia menawarkan antarmuka yang lugas dan ramah pengguna untuk membuat permintaan HTTP ke server web dan menerima tanggapan. Ini mungkin perpustakaan paling terkenal untuk web scraping.
Namun, pustaka Permintaan memiliki batasan: ia mengembalikan respons HTML sebagai string, yang mungkin sulit untuk mencari elemen tertentu seperti daftar harga saat menulis kode web scraping.
Di situlah Beautiful Soup berperan. Beautiful Soup adalah pustaka Python yang dirancang untuk web scraping yang mengekstrak data dari file HTML dan XML. Ini memungkinkan Anda mengambil informasi dari halaman web dengan mencari tag, atribut, atau teks tertentu.
Untuk menginstal kedua perpustakaan, gunakan perintah berikut:
$ python3 -m pip install requests beautifulsoup4Untuk pengguna Windows, ganti 'python3' dengan 'python', sisa perintahnya tetap sama:
d:amazon>python -m pip install requests beautifulsoup4Perhatikan bahwa kami sedang menginstal versi 4 dari perpustakaan Beautiful Soup.
Sekarang mari kita uji perpustakaan pengikisan Permintaan. Buat file baru bernama amazon.py dan masukkan kode berikut:
import requests
url = 'https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L'
response = requests.get(url)
print(response.text)Simpan file dan jalankan dari terminal.
$ python3 amazon.pyDalam kebanyakan kasus, Anda tidak akan dapat melihat HTML yang diinginkan. Amazon akan memblokir permintaan tersebut, dan Anda akan menerima respons berikut:
To discuss automated access to Amazon data please contact [email protected].Jika Anda mencetak respon.status_code, Anda akan melihat bahwa Anda menerima kesalahan 503, bukan kode sukses 200.
Amazon mengetahui permintaan ini tidak datang dari browser dan memblokirnya. Praktik ini umum terjadi di banyak situs web. Amazon mungkin memblokir permintaan Anda dan mengembalikan kode kesalahan yang dimulai dengan 500 atau bahkan terkadang 400.
Solusi sederhananya adalah mengirimkan header dengan permintaan Anda yang meniru permintaan yang dikirim oleh browser.
Terkadang, mengirimkan agen pengguna saja sudah cukup. Di lain waktu, Anda mungkin perlu mengirimkan header tambahan, seperti header bahasa terima.
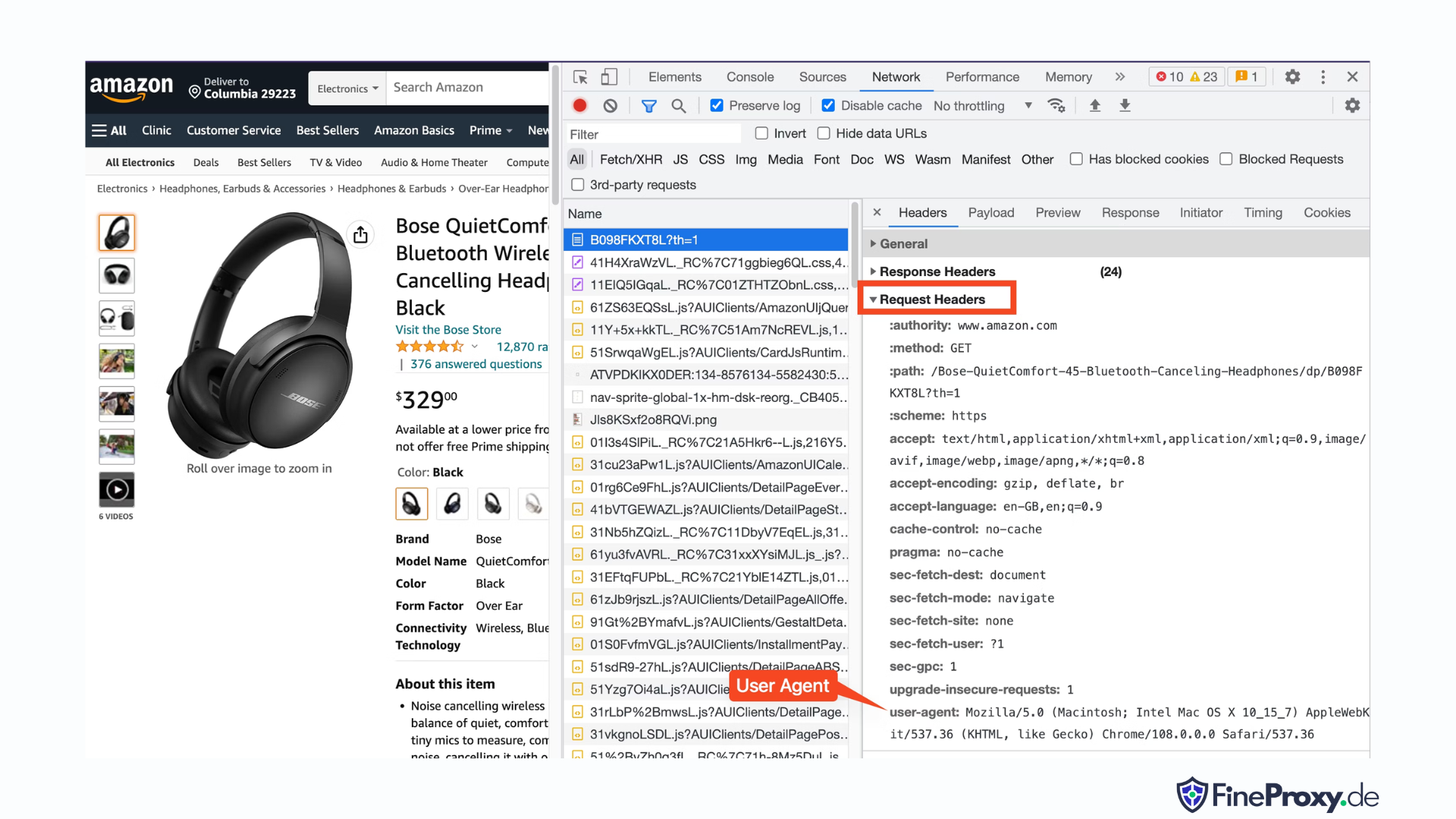
Untuk menemukan agen pengguna yang dikirim oleh browser Anda, tekan F12, buka tab Jaringan, dan muat ulang halaman. Pilih permintaan pertama dan periksa Header Permintaan.
Salin agen pengguna ini dan buat kamus untuk header, seperti contoh ini dengan header agen pengguna dan bahasa terima:
custom_headers = { '
user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'accept-language': 'en-GB,en;q=0.9',
}Anda kemudian dapat mengirimkan kamus ini sebagai parameter opsional dalam metode get:
response = requests.get(url, headers=custom_headersMengikis Informasi Produk Amazon
Dalam proses web scraping produk Amazon, Anda biasanya akan terlibat dengan dua jenis halaman: halaman kategori dan halaman detail produk.
Misalnya, kunjungi https://www.amazon.com/b?node=12097479011 atau cari Headphone Over-Ear di Amazon. Halaman yang menampilkan hasil pencarian disebut halaman kategori.
Halaman kategori menyajikan judul produk, gambar produk, rating produk, harga produk, dan yang terpenting, halaman URL produk. Untuk mengakses informasi lebih lanjut, seperti deskripsi produk, Anda harus mengunjungi halaman detail produk.
Mari kita menganalisis struktur halaman detail produk.
Buka URL produk, seperti https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L, menggunakan Chrome atau browser modern lainnya. Klik kanan judul produk dan pilih Periksa. Markup HTML dari judul produk akan disorot.
Anda akan melihat bahwa itu adalah tag span dengan atribut id yang disetel ke “productTitle”.

Demikian pula, klik kanan harga dan pilih Periksa untuk melihat markup HTML harga.
Komponen dolar dari harga berada dalam tag span dengan kelas “a-price-whole”, sedangkan komponen sen berada dalam tag span lain dengan kelas “a-price-fraksi”.

Anda juga dapat menemukan peringkat, gambar, dan deskripsi dengan cara yang sama.
Setelah Anda mengumpulkan informasi ini, tambahkan baris berikut ke kode yang ada:
response = requests.get(url, headers=custom_headers)
soup = BeautifulSoup(response.text, 'lxml')Beautiful Soup menawarkan metode berbeda dalam memilih tag menggunakan metode find. Ini juga mendukung pemilih CSS sebagai alternatif. Anda dapat menggunakan pendekatan mana pun untuk mencapai hasil yang sama. Dalam tutorial ini, kita akan menggunakan pemilih CSS, sebuah metode universal untuk memilih elemen. Pemilih CSS kompatibel dengan hampir semua alat pengikis web untuk mengekstrak informasi produk Amazon.
Sekarang Anda siap menggunakan objek Soup untuk menanyakan informasi spesifik.
Mengekstrak Nama Produk
Nama atau judul produk ditemukan dalam elemen span dengan id 'productTitle'. Memilih elemen menggunakan id unik itu sederhana.
Perhatikan kode berikut sebagai contoh:
title_element = soup.select_one('#productTitle') Kami meneruskan pemilih CSS ke metode select_one, yang mengembalikan instance elemen.
Untuk mengekstrak informasi dari teks, gunakan atribut teks.
title = title_element.textSaat mencetak, Anda mungkin melihat beberapa spasi putih. Untuk mengatasinya, tambahkan pemanggilan fungsi .strip() sebagai berikut:
title = title_element.text.strip()Mengekstraksi Peringkat Produk
Mendapatkan peringkat produk Amazon memerlukan upaya tambahan.
Pertama, tetapkan pemilih untuk peringkat:
#acrPopoverSelanjutnya, gunakan pernyataan berikut untuk memilih elemen yang berisi rating:
rating_element = soup.select_one('#acrPopover')Perhatikan bahwa nilai peringkat sebenarnya ditemukan dalam atribut title :
rating_text = rating_element.attrs.get('title')
print(rating_text)
# prints '4.6 out of 5 stars'Terakhir, gunakan metode ganti untuk mendapatkan peringkat numerik:
rating = rating_text.replace('out of 5 stars', '')Mengekstraksi Harga Produk
Harga produk dapat ditemukan di dua lokasi — di bawah judul produk dan di dalam kotak Beli Sekarang.
Salah satu dari tag ini dapat digunakan untuk mengurangi harga produk Amazon.
Buat pemilih CSS untuk harga:
#price_inside_buyboxTeruskan pemilih CSS ini ke metode select_one pada BeautifulSoup seperti ini:
price_element = soup.select_one('#price_inside_buybox')Sekarang, Anda dapat mencetak harganya:
print(price_element.text)Mengekstrak Gambar
Untuk mengikis gambar default, gunakan pemilih CSS #landingImage. Dengan informasi ini, Anda dapat menulis baris kode berikut untuk mendapatkan URL gambar dari atribut src:
image_element = soup.select_one('#landingImage')
image = image_element.attrs.get('src')Mengekstrak Deskripsi Produk
Langkah selanjutnya dalam mengekstrak data produk Amazon adalah mendapatkan deskripsi produk.
Prosesnya tetap konsisten — buat pemilih CSS dan gunakan metode select_one.
Pemilih CSS untuk deskripsinya adalah:
#productDescriptionHal ini memungkinkan kita untuk mengekstrak elemen sebagai berikut:
description_element = soup.select_one('#productDescription')
print(description_element.text)Menangani Daftar Produk
Kami telah menjelajahi informasi produk, tetapi Anda harus memulai dengan halaman daftar produk atau kategori untuk mengakses data produk.
Misalnya, https://www.amazon.com/b?node=12097479011 adalah halaman kategori untuk headphone over-ear.
Jika Anda memeriksa halaman ini, Anda akan melihat bahwa semua produk terdapat dalam div yang memiliki atribut unik [data-asin]. Di dalam div itu, semua link produk berada dalam tag h2.
Dengan informasi ini, Pemilih CSS adalah:
[data-asin] h2 aAnda dapat membaca atribut href dari pemilih ini dan menjalankan loop. Namun, ingatlah bahwa tautannya bersifat relatif. Anda harus menggunakan metode urljoin untuk mengurai tautan ini.
from urllib.parse import urljoin
...
def parse_listing(listing_url):
…
link_elements = soup_search.select("[data-asin] h2 a")
page_data = []
for link in link_elements:
full_url = urljoin(search_url, link.attrs.get("href"))
product_info = get_product_info(full_url)
page_data.append(product_info)Menangani Paginasi
Tautan ke halaman selanjutnya ada pada tautan yang berisi teks “Selanjutnya”. Anda dapat mencari tautan ini menggunakan operator berisi CSS sebagai berikut:
next_page_el = soup.select_one('a:contains("Next")')
if next_page_el:
next_page_url = next_page_el.attrs.get('href')
next_page_url = urljoin(listing_url, next_page_url)Mengekspor Data Amazon
Data yang tergores dikembalikan sebagai kamus dengan sengaja. Anda dapat membuat daftar yang berisi semua produk yang tergores.
def parse_listing(listing_url):
...
page_data = [] for link in link_elements:
...
product_info = get_product_info(full_url)
page_data.append(product_info)Anda kemudian dapat menggunakan page_data ini untuk membuat objek Pandas DataFrame:
df = pd.DataFrame(page_data)
df.to_csv('headphones.csv', index = False)Cara Mengikis Banyak Halaman di Amazon
Mengikis beberapa halaman di Amazon dapat meningkatkan efektivitas proyek pengikisan web Anda dengan menyediakan kumpulan data yang lebih luas untuk dianalisis. Saat menargetkan beberapa halaman, Anda harus mempertimbangkan penomoran halaman, yang merupakan proses membagi konten menjadi beberapa halaman.
Di sini adalah 6 poin penting yang perlu diingat saat menggores beberapa halaman di Amazon:
- Identifikasi pola penomoran halaman: Pertama, analisis struktur URL kategori atau halaman hasil pencarian untuk memahami bagaimana Amazon membuat halaman kontennya. Ini bisa berupa parameter kueri (misalnya, “?page=2”) atau pengidentifikasi unik yang tertanam dalam URL.
- Ekstrak tautan halaman "Berikutnya": Temukan elemen (biasanya tag jangkar) yang berisi link ke halaman berikutnya. Gunakan pemilih CSS atau metode Sup Cantik yang sesuai untuk mengekstrak atribut href elemen ini, yang merupakan URL untuk halaman berikutnya.
- Ubah URL relatif menjadi URL absolut: Karena URL yang diekstrak mungkin bersifat relatif, gunakan
urljoinfungsi dariurllib.parseperpustakaan untuk mengubahnya menjadi URL absolut. - Buat lingkaran: Terapkan perulangan yang mengulangi halaman-halaman, mengambil data yang diinginkan dari masing-masing halaman. Perulangan harus berlanjut hingga tidak ada lagi halaman yang tersisa, yang dapat ditentukan dengan memeriksa apakah tautan halaman “Berikutnya” ada di halaman saat ini.
- Tambahkan penundaan antar permintaan: Untuk menghindari membebani server Amazon atau memicu tindakan anti-bot, lakukan penundaan antar permintaan menggunakan
time.sleep()fungsi daritimeperpustakaan. Sesuaikan durasi penundaan untuk meniru perilaku penelusuran manusia. - Menangani CAPTCHA dan blok: Jika Anda menemukan CAPTCHA atau blok IP saat menyalin beberapa halaman, pertimbangkan untuk menggunakan proxy untuk merotasi alamat IP atau alat dan layanan pengikisan khusus yang dapat menangani tantangan ini secara otomatis.
Di bawah ini, Anda akan menemukan tutorial video YouTube komprehensif yang memandu Anda melalui proses mengekstraksi data dari beberapa halaman di situs web Amazon. Tutorial ini menggali jauh ke dalam dunia web scraping, dengan fokus pada teknik yang memungkinkan Anda mengumpulkan informasi berharga secara efisien dan efektif dari berbagai halaman Amazon.
Sepanjang tutorial, presenter mendemonstrasikan penggunaan alat dan pustaka penting, seperti Python, BeautifulSoup, dan permintaan, sambil menyoroti praktik terbaik untuk menghindari pemblokiran atau terdeteksi oleh mekanisme anti-bot Amazon. Video ini mencakup topik-topik penting seperti menangani penomoran halaman, mengelola batas kecepatan, dan meniru perilaku penjelajahan seperti manusia.
Selain petunjuk langkah demi langkah yang diberikan dalam video, tutorial ini juga membagikan tips dan trik berguna untuk mengoptimalkan pengalaman web scraping Anda. Hal ini termasuk menggunakan proxy untuk melewati batasan IP, mengacak Agen-Pengguna dan header permintaan, serta menerapkan penanganan kesalahan yang tepat untuk memastikan proses pengikisan berjalan lancar dan tanpa gangguan.
Mengikis Amazon: FAQ
Saat mengekstrak data dari Amazon, platform e-niaga populer, ada beberapa hal yang perlu diperhatikan. Mari selami pertanyaan umum terkait pengikisan data Amazon.
1. Apakah Sah untuk Mengikis Amazon?
Menghapus data yang tersedia untuk umum dari internet adalah sah, dan ini termasuk menghapus Amazon. Anda dapat secara legal mengikis informasi seperti detail produk, deskripsi, peringkat, dan harga. Namun, saat mengambil ulasan produk, Anda harus berhati-hati dengan data pribadi dan perlindungan hak cipta. Misalnya, nama dan avatar pengulas mungkin merupakan data pribadi, sedangkan teks ulasan mungkin dilindungi hak cipta. Selalu berhati-hati dan mintalah nasihat hukum saat mengambil data tersebut.
2. Apakah Amazon Mengizinkan Pengikisan?
Meskipun menghapus data yang tersedia untuk umum adalah sah, Amazon terkadang mengambil tindakan untuk mencegah pengambilan data. Langkah-langkah ini termasuk pembatasan kecepatan permintaan, pelarangan alamat IP, dan penggunaan sidik jari browser untuk mendeteksi bot pengikis. Amazon biasanya memblokir web scraping dengan kode respons status keberhasilan 200 OK dan mengharuskan Anda meneruskan CAPTCHA atau menampilkan pesan HTTP Error 503 Service Unavailable untuk menghubungi bagian penjualan untuk API berbayar.
Ada beberapa cara untuk menghindari tindakan ini, tetapi web scraping yang etis dapat membantu menghindari pemicunya. Pengikisan web yang etis melibatkan pembatasan frekuensi permintaan, penggunaan agen pengguna yang sesuai, dan menghindari pengikisan berlebihan yang dapat memengaruhi kinerja situs web. Dengan melakukan scraping secara etis, Anda dapat mengurangi risiko pemblokiran atau menghadapi konsekuensi hukum sambil tetap mengekstrak data yang berguna dari Amazon.
3. Apakah Etis Mengikis Data Amazon?
Mengikis secara etis melibatkan penghormatan terhadap situs web target. Meskipun kecil kemungkinan Anda akan membebani situs web Amazon dengan terlalu banyak permintaan, Anda tetap harus mengikuti pedoman etika scraping. Pengikisan etis dapat meminimalkan risiko menghadapi masalah hukum atau menghadapi tindakan anti-pengikisan.
4. Bagaimana Saya Dapat Menghindari Banned Saat Mengikis Amazon?
Untuk menghindari pemblokiran saat melakukan scraping Amazon, Anda harus membatasi tingkat permintaan Anda, menghindari scraping selama jam sibuk, menggunakan rotasi proksi cerdas, dan menggunakan agen pengguna dan header yang sesuai untuk menghindari deteksi. Selain itu, hanya ekstrak data yang Anda perlukan dan gunakan alat pengikis atau pustaka pengikis pihak ketiga.
5. Apa Risiko Mengikis Amazon?
Menghapus data Amazon membawa potensi risiko, seperti tindakan hukum dan penangguhan akun. Amazon menggunakan tindakan anti-bot untuk mendeteksi dan mencegah pengikisan, termasuk larangan alamat IP, pembatasan kecepatan, dan sidik jari browser. Namun, dengan melakukan scraping secara etis, Anda dapat mengurangi risiko ini.
Kesimpulan
Saat kita keluar dari labirin web scraping Amazon yang memikat, inilah saatnya meluangkan waktu sejenak untuk mengapresiasi pengetahuan dan keterampilan tak ternilai yang telah kita kumpulkan dalam perjalanan yang menggembirakan ini. Dengan ProxyCompass sebagai panduan tepercaya, Anda telah berhasil menavigasi liku-liku dalam mengekstraksi data yang tak ternilai harganya dari raksasa ritel tersebut. Saat Anda menjelajah, menggunakan keahlian baru Anda dengan kemahiran, ingatlah bahwa hutan digital tidak pernah berhenti berkembang.
Tetaplah penasaran, terus pertajam parang pengikis web Anda, dan terus taklukkan lanskap ekstraksi data yang selalu berubah. Sampai ekspedisi berani kami berikutnya, penjelajah pemberani, semoga pencarian berbasis data Anda membuahkan hasil dan bermanfaat!

