



Hãy tưởng tượng bạn là một nhà thám hiểm mạo hiểm, lao đầu vào thế giới rộng lớn và bí ẩn của Amazon—không phải rừng nhiệt đới mà là gã khổng lồ bán lẻ trực tuyến. Với mỗi cú nhấp chuột, bạn khám phá những kho báu vô giá, đào sâu hơn vào lãnh thổ dữ liệu chưa được khám phá.
Trong chuyến thám hiểm ly kỳ này, chúng tôi trình bày hướng dẫn từng bước để điều hướng khu rừng kỹ thuật số dày đặc của việc quét web trên Amazon. Hãy sẵn sàng bắt đầu một cuộc hành trình không giống ai, được trang bị các mẹo và thủ thuật của chuyên gia để trích xuất thông tin có giá trị với độ chính xác tuyệt vời.
Mục lục
- Dữ liệu nào cần cạo từ Amazon
- Một số yêu cầu cơ bản
- Thiết lập để cạo
- Quét thông tin sản phẩm của Amazon
- Cách cạo nhiều trang trên Amazon
- Quét Amazon: Câu hỏi thường gặp
- Phần kết luận
Vì vậy, hãy thu hết can đảm, đeo đôi ủng ảo của bạn và cùng nhau bắt đầu cuộc phiêu lưu dựa trên dữ liệu của chúng ta!
Dữ liệu nào cần cạo từ Amazon
Có rất nhiều điểm dữ liệu liên quan đến một sản phẩm của Amazon, nhưng các yếu tố chính cần tập trung vào khi thu thập dữ liệu bao gồm:
- Tiêu đề sản phẩm
- Trị giá
- Tiết kiệm (nếu có)
- Tóm tắt mục
- Danh sách tính năng liên quan (nếu có)
- Điểm đánh giá
- Hình ảnh sản phẩm
Mặc dù đây là những khía cạnh chính cần cân nhắc khi tìm kiếm một mặt hàng trên Amazon, nhưng điều quan trọng cần lưu ý là thông tin bạn trích xuất có thể khác nhau tùy thuộc vào mục tiêu cụ thể của bạn.
Một số yêu cầu cơ bản
Để chuẩn bị một món súp, chúng ta cần có những nguyên liệu phù hợp. Tương tự, trình quét web mới của chúng tôi yêu cầu các thành phần cụ thể.
- Python — Tính thân thiện với người dùng và bộ sưu tập thư viện phong phú khiến Python trở thành lựa chọn hàng đầu để quét web. Nếu nó chưa được cài đặt, hãy tham khảo hướng dẫn này.
- BeautifulSoup — Đây là một trong nhiều thư viện quét web có sẵn cho Python. Tính đơn giản và cách sử dụng rõ ràng của nó làm cho nó trở thành một lựa chọn phổ biến để quét web. Sau khi cài đặt thành công Python, bạn có thể cài đặt Beautiful Soup bằng cách chạy: pip install bs4
- Hiểu biết cơ bản về thẻ HTML — Tham khảo hướng dẫn này để có được kiến thức cần thiết về thẻ HTML.
- Trình duyệt web — Vì chúng tôi cần lọc ra nhiều thông tin không liên quan khỏi một trang web nên cần có id và thẻ cụ thể cho mục đích lọc. Trình duyệt web như Google Chrome hoặc Mozilla Firefox rất hữu ích để xác định các thẻ đó.
Thiết lập để cạo
Để bắt đầu, hãy đảm bảo rằng bạn đã cài đặt Python. Nếu bạn không có Python 3.8 trở lên, hãy truy cập python.org để tải xuống và cài đặt phiên bản mới nhất.
Tiếp theo, tạo một thư mục để lưu trữ các tệp mã quét web của bạn cho Amazon. Nói chung, bạn nên thiết lập một môi trường ảo cho dự án của mình.
Sử dụng các lệnh sau để tạo và kích hoạt môi trường ảo trên macOS và Linux:
$ python3 -m venv .env
$ source .env/bin/activateĐối với người dùng Windows, các lệnh sẽ hơi khác một chút:
d:amazon>python -m venv .env
d:amazon>.envscriptsactivateBây giờ là lúc cài đặt các gói Python cần thiết.
Bạn sẽ cần các gói cho hai nhiệm vụ chính: lấy HTML và phân tích cú pháp để trích xuất dữ liệu liên quan.
Thư viện Yêu cầu là thư viện Python của bên thứ ba được sử dụng rộng rãi để thực hiện các yêu cầu HTTP. Nó cung cấp một giao diện đơn giản và thân thiện với người dùng để thực hiện các yêu cầu HTTP tới máy chủ web và nhận phản hồi. Nó có lẽ là thư viện nổi tiếng nhất về quét web.
Tuy nhiên, thư viện Yêu cầu có một hạn chế: nó trả về phản hồi HTML dưới dạng một chuỗi, có thể khó tìm kiếm các phần tử cụ thể như niêm yết giá khi viết mã quét web.
Đó là lúc Beautiful Soup xuất hiện. Beautiful Soup là một thư viện Python được thiết kế để quét web nhằm trích xuất dữ liệu từ các tệp HTML và XML. Nó cho phép bạn truy xuất thông tin từ một trang web bằng cách tìm kiếm thẻ, thuộc tính hoặc văn bản cụ thể.
Để cài đặt cả hai thư viện, hãy sử dụng lệnh sau:
$ python3 -m pip install requests beautifulsoup4Đối với người dùng Windows, hãy thay thế 'python3' bằng 'python', giữ nguyên phần còn lại của lệnh:
d:amazon>python -m pip install requests beautifulsoup4Lưu ý rằng chúng tôi đang cài đặt phiên bản 4 của thư viện Beautiful Soup.
Bây giờ hãy kiểm tra thư viện thu thập Yêu cầu. Tạo một tệp mới có tên amazon.py và nhập mã sau:
import requests
url = 'https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L'
response = requests.get(url)
print(response.text)Lưu tệp và chạy nó từ thiết bị đầu cuối.
$ python3 amazon.pyTrong hầu hết các trường hợp, bạn sẽ không thể xem được HTML mong muốn. Amazon sẽ chặn yêu cầu và bạn sẽ nhận được phản hồi sau:
To discuss automated access to Amazon data please contact [email protected].Nếu bạn in phản hồi.status_code, bạn sẽ thấy rằng mình nhận được lỗi 503 thay vì mã thành công 200.
Amazon biết yêu cầu này không đến từ trình duyệt và chặn nó. Thực tế này là phổ biến trong nhiều trang web. Amazon có thể chặn yêu cầu của bạn và trả lại mã lỗi bắt đầu bằng 500 hoặc đôi khi thậm chí là 400.
Một giải pháp đơn giản là gửi tiêu đề cùng với yêu cầu của bạn bắt chước tiêu đề do trình duyệt gửi.
Đôi khi, chỉ gửi tác nhân người dùng là đủ. Những lúc khác, bạn có thể cần gửi các tiêu đề bổ sung, chẳng hạn như tiêu đề ngôn ngữ chấp nhận.
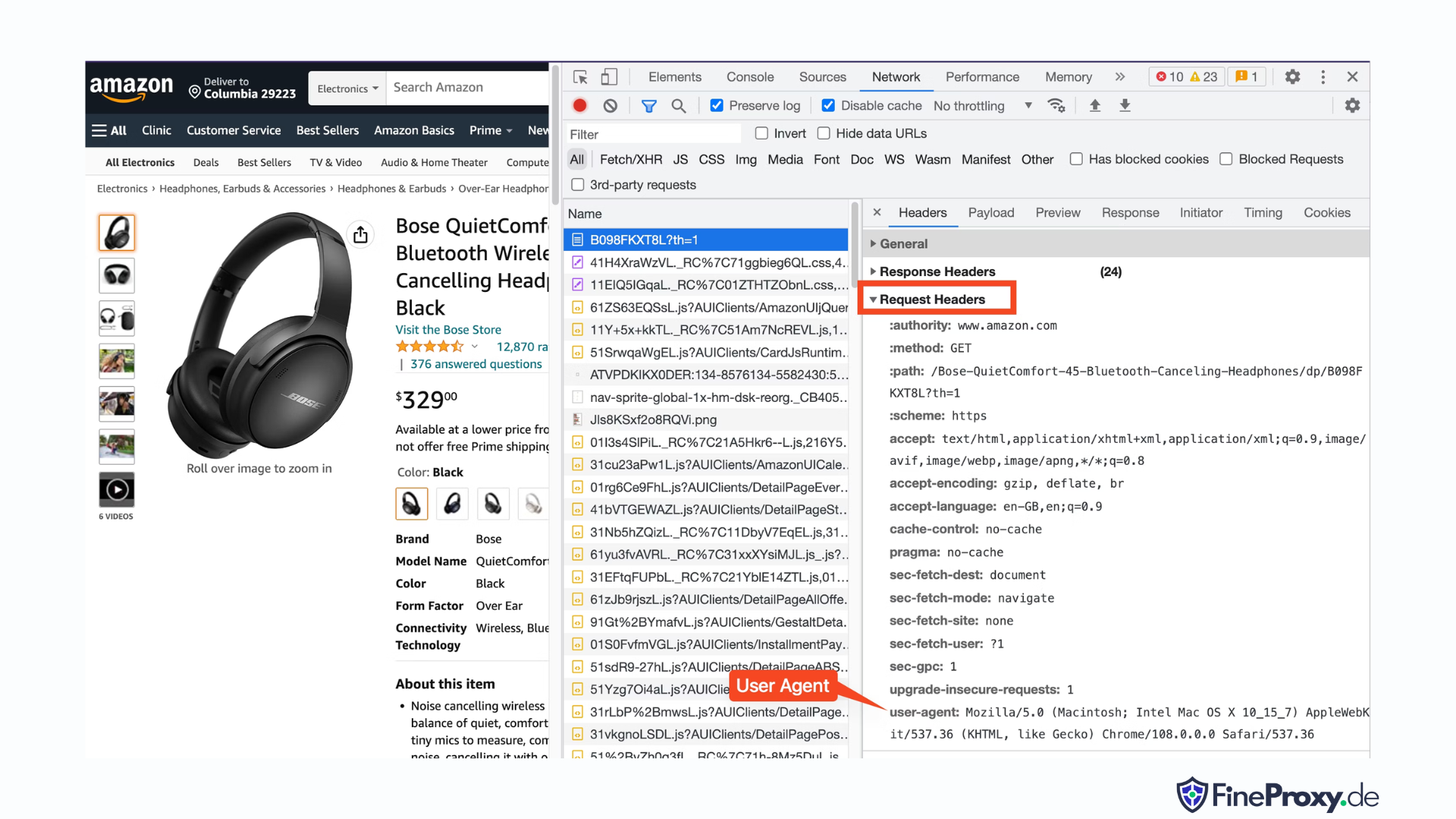
Để tìm tác nhân người dùng do trình duyệt của bạn gửi, hãy nhấn F12, mở tab Mạng và tải lại trang. Chọn yêu cầu đầu tiên và kiểm tra Tiêu đề yêu cầu.
Sao chép tác nhân người dùng này và tạo một từ điển cho các tiêu đề, như ví dụ này với các tiêu đề tác nhân người dùng và ngôn ngữ chấp nhận:
custom_headers = { '
user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'accept-language': 'en-GB,en;q=0.9',
}Sau đó, bạn có thể gửi từ điển này dưới dạng tham số tùy chọn trong phương thức get:
response = requests.get(url, headers=custom_headersQuét thông tin sản phẩm của Amazon
Trong quá trình tìm kiếm trên web các sản phẩm của Amazon, thông thường bạn sẽ tương tác với hai loại trang: trang danh mục và trang chi tiết sản phẩm.
Ví dụ, hãy truy cập https://www.amazon.com/b?node=12097479011 hoặc tìm kiếm Tai nghe Over-Ear trên Amazon. Trang hiển thị kết quả tìm kiếm được gọi là trang danh mục.
Trang danh mục trình bày tiêu đề sản phẩm, hình ảnh sản phẩm, xếp hạng sản phẩm, giá sản phẩm và quan trọng nhất là trang URL sản phẩm. Để truy cập thêm thông tin, chẳng hạn như mô tả sản phẩm, bạn phải truy cập trang chi tiết sản phẩm.
Hãy phân tích cấu trúc của trang chi tiết sản phẩm.
Mở URL sản phẩm, như https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L, sử dụng Chrome hoặc một trình duyệt hiện đại khác. Nhấp chuột phải vào tiêu đề sản phẩm và chọn Kiểm tra. Đánh dấu HTML của tiêu đề sản phẩm sẽ được đánh dấu.
Bạn sẽ nhận thấy rằng đó là thẻ span có thuộc tính id được đặt thành “productTitle”.

Tương tự, nhấp chuột phải vào giá và chọn Kiểm tra để xem đánh dấu HTML của giá.
Thành phần đô la của giá nằm trong thẻ span với lớp “a-price-whole”, trong khi thành phần xu nằm trong một thẻ span khác với lớp “a-price-section”.

Bạn cũng có thể xác định vị trí xếp hạng, hình ảnh và mô tả theo cách tương tự.
Khi bạn đã thu thập thông tin này, hãy thêm các dòng sau vào mã hiện có:
response = requests.get(url, headers=custom_headers)
soup = BeautifulSoup(response.text, 'lxml')Beautiful Soup cung cấp một phương pháp chọn thẻ riêng biệt bằng phương pháp tìm kiếm. Nó cũng hỗ trợ các bộ chọn CSS thay thế. Bạn có thể sử dụng một trong hai cách tiếp cận để đạt được kết quả tương tự. Trong hướng dẫn này, chúng ta sẽ sử dụng bộ chọn CSS, một phương pháp phổ biến để chọn các phần tử. Bộ chọn CSS tương thích với hầu hết các công cụ quét web để trích xuất thông tin sản phẩm của Amazon.
Bây giờ bạn đã sẵn sàng sử dụng đối tượng Soup để truy vấn thông tin cụ thể.
Trích xuất tên sản phẩm
Tên hoặc tiêu đề sản phẩm được tìm thấy trong phần tử span có id 'productTitle'. Việc chọn các phần tử sử dụng id duy nhất rất đơn giản.
Hãy xem xét đoạn mã sau đây làm ví dụ:
title_element = soup.select_one('#productTitle') Chúng ta chuyển bộ chọn CSS cho phương thức select_one, phương thức này trả về một phiên bản phần tử.
Để trích xuất thông tin từ văn bản, hãy sử dụng thuộc tính văn bản.
title = title_element.textKhi in ra, bạn có thể nhận thấy một vài khoảng trắng. Để giải quyết vấn đề này, hãy thêm lệnh gọi hàm .strip() như sau:
title = title_element.text.strip()Trích xuất xếp hạng sản phẩm
Để có được xếp hạng sản phẩm của Amazon đòi hỏi một số nỗ lực bổ sung.
Đầu tiên, thiết lập bộ chọn để xếp hạng:
#acrPopoverTiếp theo, sử dụng câu lệnh sau để chọn phần tử chứa xếp hạng:
rating_element = soup.select_one('#acrPopover')Lưu ý rằng giá trị xếp hạng thực tế được tìm thấy trong thuộc tính tiêu đề:
rating_text = rating_element.attrs.get('title')
print(rating_text)
# prints '4.6 out of 5 stars'Cuối cùng, sử dụng phương pháp thay thế để có được đánh giá bằng số:
rating = rating_text.replace('out of 5 stars', '')Trích xuất giá sản phẩm
Giá sản phẩm có thể được tìm thấy ở hai vị trí - bên dưới tiêu đề sản phẩm và trong hộp Mua ngay.
Một trong những thẻ này có thể được sử dụng để giảm giá sản phẩm của Amazon.
Tạo bộ chọn CSS cho giá:
#price_inside_buyboxChuyển bộ chọn CSS này cho phương thức select_one của BeautifulSoup như thế này:
price_element = soup.select_one('#price_inside_buybox')Bây giờ, bạn có thể in giá:
print(price_element.text)Trích xuất hình ảnh
Để cạo hình ảnh mặc định, hãy sử dụng bộ chọn CSS #landingImage. Với thông tin này, bạn có thể viết các dòng mã sau để lấy URL hình ảnh từ thuộc tính src:
image_element = soup.select_one('#landingImage')
image = image_element.attrs.get('src')Trích xuất mô tả sản phẩm
Bước tiếp theo trong việc trích xuất dữ liệu sản phẩm của Amazon là lấy mô tả sản phẩm.
Quá trình này vẫn nhất quán — tạo bộ chọn CSS và sử dụng phương thức select_one.
Bộ chọn CSS cho mô tả là:
#productDescriptionĐiều này cho phép chúng ta trích xuất phần tử như sau:
description_element = soup.select_one('#productDescription')
print(description_element.text)Xử lý danh sách sản phẩm
Chúng tôi đã khám phá việc thu thập thông tin sản phẩm, nhưng bạn sẽ cần bắt đầu với các trang danh sách sản phẩm hoặc danh mục để truy cập dữ liệu sản phẩm.
Ví dụ, https://www.amazon.com/b?node=12097479011 là trang danh mục dành cho tai nghe over-ear.
Nếu bạn kiểm tra trang này, bạn sẽ thấy rằng tất cả các sản phẩm đều được chứa trong một div có thuộc tính duy nhất [data-asin]. Trong div đó, tất cả các liên kết sản phẩm đều nằm trong thẻ h2.
Với thông tin này, Bộ chọn CSS là:
[data-asin] h2 aBạn có thể đọc thuộc tính href của bộ chọn này và chạy vòng lặp. Tuy nhiên, hãy nhớ rằng các liên kết sẽ mang tính chất tương đối. Bạn sẽ cần sử dụng phương thức urljoin để phân tích các liên kết này.
from urllib.parse import urljoin
...
def parse_listing(listing_url):
…
link_elements = soup_search.select("[data-asin] h2 a")
page_data = []
for link in link_elements:
full_url = urljoin(search_url, link.attrs.get("href"))
product_info = get_product_info(full_url)
page_data.append(product_info)Xử lý phân trang
Liên kết tới trang tiếp theo nằm trong liên kết có chứa văn bản “Tiếp theo”. Bạn có thể tìm kiếm liên kết này bằng toán tử chứa CSS như sau:
next_page_el = soup.select_one('a:contains("Next")')
if next_page_el:
next_page_url = next_page_el.attrs.get('href')
next_page_url = urljoin(listing_url, next_page_url)Xuất dữ liệu Amazon
Dữ liệu bị loại bỏ được trả về dưới dạng từ điển một cách có chủ ý. Bạn có thể tạo một danh sách chứa tất cả các sản phẩm bị loại bỏ.
def parse_listing(listing_url):
...
page_data = [] for link in link_elements:
...
product_info = get_product_info(full_url)
page_data.append(product_info)Sau đó, bạn có thể sử dụng page_data này để tạo đối tượng Pandas DataFrame:
df = pd.DataFrame(page_data)
df.to_csv('headphones.csv', index = False)Cách cạo nhiều trang trên Amazon
Quét nhiều trang trên Amazon có thể nâng cao hiệu quả của dự án quét web của bạn bằng cách cung cấp tập dữ liệu rộng hơn để phân tích. Khi nhắm mục tiêu nhiều trang, bạn cần xem xét phân trang, đó là quá trình phân chia nội dung trên nhiều trang.
Đây là 6 điểm quan trọng cần ghi nhớ khi cạo nhiều trang trên Amazon:
- Xác định kiểu phân trang: Đầu tiên, hãy phân tích cấu trúc URL của danh mục hoặc trang kết quả tìm kiếm để hiểu cách Amazon phân trang nội dung của nó. Đây có thể là tham số truy vấn (ví dụ: “?page=2”) hoặc mã định danh duy nhất được nhúng trong URL.
- Trích xuất liên kết trang “Tiếp theo”: Xác định vị trí phần tử (thường là thẻ neo) chứa liên kết đến trang tiếp theo. Sử dụng bộ chọn CSS thích hợp hoặc phương pháp Beautiful Soup để trích xuất thuộc tính href của phần tử này, đây là URL cho trang tiếp theo.
- Chuyển đổi URL tương đối thành URL tuyệt đối: Vì các URL được trích xuất có thể là tương đối nên hãy sử dụng
urljoinchức năng từurllib.parsethư viện để chuyển đổi chúng thành URL tuyệt đối. - Tạo một vòng lặp: Triển khai một vòng lặp lặp qua các trang, lấy dữ liệu mong muốn từ mỗi trang. Vòng lặp sẽ tiếp tục cho đến khi không còn trang nào nữa, điều này có thể được xác định bằng cách kiểm tra xem liên kết trang “Tiếp theo” có tồn tại trên trang hiện tại hay không.
- Thêm độ trễ giữa các yêu cầu: Để tránh làm quá tải máy chủ của Amazon hoặc kích hoạt các biện pháp chống bot, hãy tạo độ trễ giữa các yêu cầu bằng cách sử dụng
time.sleep()chức năng từtimethư viện. Điều chỉnh thời lượng trễ để mô phỏng hành vi duyệt web của con người. - Xử lý CAPTCHA và khối: Nếu bạn gặp phải CAPTCHA hoặc khối IP trong khi tìm kiếm nhiều trang, hãy cân nhắc sử dụng proxy để xoay địa chỉ IP hoặc các công cụ và dịch vụ tìm kiếm chuyên dụng có thể tự động xử lý những thách thức này.
Bên dưới, bạn sẽ tìm thấy video hướng dẫn toàn diện trên YouTube hướng dẫn bạn quy trình trích xuất dữ liệu từ nhiều trang trên trang web của Amazon. Hướng dẫn đi sâu vào thế giới quét web, tập trung vào các kỹ thuật cho phép bạn thu thập thông tin có giá trị từ nhiều trang Amazon một cách hiệu quả và hiệu quả.
Trong suốt hướng dẫn, người trình bày trình bày cách sử dụng các công cụ và thư viện thiết yếu, chẳng hạn như Python, BeautifulSoup và các yêu cầu, đồng thời nêu bật các phương pháp hay nhất để tránh bị cơ chế chống bot của Amazon chặn hoặc phát hiện. Video bao gồm các chủ đề thiết yếu như xử lý phân trang, quản lý giới hạn tốc độ và bắt chước hành vi duyệt web giống con người.
Ngoài hướng dẫn từng bước được cung cấp trong video, hướng dẫn này còn chia sẻ các mẹo và thủ thuật hữu ích để tối ưu hóa trải nghiệm quét web của bạn. Chúng bao gồm việc sử dụng proxy để vượt qua các hạn chế IP, ngẫu nhiên hóa Tác nhân người dùng và tiêu đề yêu cầu, đồng thời triển khai xử lý lỗi thích hợp để đảm bảo quá trình quét trơn tru và không bị gián đoạn.
Quét Amazon: Câu hỏi thường gặp
Khi nói đến việc trích xuất dữ liệu từ Amazon, một nền tảng thương mại điện tử phổ biến, có một số điều nhất định mà người ta cần lưu ý. Hãy cùng đi sâu vào các câu hỏi thường gặp liên quan đến việc thu thập dữ liệu của Amazon.
1. Việc cạo Amazon có hợp pháp không?
Việc thu thập dữ liệu có sẵn công khai từ internet là hợp pháp và điều này bao gồm cả việc thu thập dữ liệu của Amazon. Bạn có thể thu thập thông tin một cách hợp pháp như chi tiết sản phẩm, mô tả, xếp hạng và giá cả. Tuy nhiên, khi thu thập đánh giá sản phẩm, bạn nên thận trọng với dữ liệu cá nhân và bảo vệ bản quyền. Ví dụ: tên và hình đại diện của người đánh giá có thể cấu thành dữ liệu cá nhân, trong khi văn bản đánh giá có thể được bảo vệ bản quyền. Luôn thận trọng và tìm kiếm lời khuyên pháp lý khi thu thập dữ liệu đó.
2. Amazon có cho phép Scraping không?
Mặc dù việc thu thập dữ liệu có sẵn công khai là hợp pháp nhưng Amazon đôi khi thực hiện các biện pháp để ngăn chặn việc thu thập dữ liệu. Các biện pháp này bao gồm các yêu cầu giới hạn tốc độ, cấm địa chỉ IP và sử dụng dấu vân tay của trình duyệt để phát hiện các bot quét. Amazon thường chặn việc quét web bằng mã phản hồi trạng thái thành công 200 OK và yêu cầu bạn chuyển CAPTCHA hoặc hiển thị thông báo Lỗi HTTP 503 Dịch vụ không khả dụng để liên hệ với bộ phận bán hàng đối với API trả phí.
Có nhiều cách để phá vỡ các biện pháp này, nhưng việc quét web có đạo đức có thể giúp tránh kích hoạt chúng ngay từ đầu. Quét web có đạo đức liên quan đến việc hạn chế tần suất yêu cầu, sử dụng tác nhân người dùng phù hợp và tránh việc quét quá mức có thể ảnh hưởng đến hiệu suất trang web. Bằng cách thu thập dữ liệu một cách có đạo đức, bạn có thể giảm nguy cơ bị cấm hoặc phải đối mặt với hậu quả pháp lý trong khi vẫn trích xuất được dữ liệu hữu ích từ Amazon.
3. Việc thu thập dữ liệu của Amazon có hợp đạo đức không?
Quét có đạo đức liên quan đến việc tôn trọng trang web mục tiêu. Mặc dù bạn khó có thể khiến trang web Amazon bị quá tải với quá nhiều yêu cầu, nhưng bạn vẫn nên tuân theo các nguyên tắc thu thập dữ liệu có đạo đức. Cạo có đạo đức có thể giảm thiểu rủi ro gặp phải các vấn đề pháp lý hoặc xử lý các biện pháp chống cào.
4. Làm cách nào tôi có thể tránh bị cấm khi tìm kiếm trên Amazon?
Để tránh bị cấm khi thu thập dữ liệu trên Amazon, bạn nên giới hạn tỷ lệ yêu cầu của mình, tránh thu thập dữ liệu trong giờ cao điểm, sử dụng xoay vòng proxy thông minh và sử dụng các tiêu đề và tác nhân người dùng thích hợp để tránh bị phát hiện. Ngoài ra, chỉ trích xuất dữ liệu bạn cần và sử dụng các công cụ thu thập dữ liệu hoặc thư viện thu thập dữ liệu của bên thứ ba.
5. Rủi ro của việc thu thập Amazon là gì?
Việc thu thập dữ liệu của Amazon tiềm ẩn những rủi ro, chẳng hạn như hành động pháp lý và đình chỉ tài khoản. Amazon sử dụng các biện pháp chống bot để phát hiện và ngăn chặn việc thu thập dữ liệu, bao gồm cấm địa chỉ IP, giới hạn tốc độ và lấy dấu vân tay của trình duyệt. Tuy nhiên, bằng cách loại bỏ một cách có đạo đức, bạn có thể giảm thiểu những rủi ro này.
Phần kết luận
Khi chúng ta bước ra từ mê cung đầy mê hoặc của công việc tìm kiếm web trên Amazon, đã đến lúc dành một chút thời gian để đánh giá cao kiến thức và kỹ năng vô giá mà chúng ta đã thu thập được trên hành trình đầy phấn khích này. Với ProxyCompass là người hướng dẫn đáng tin cậy, bạn đã điều hướng thành công các bước ngoặt trong việc trích xuất dữ liệu vô giá từ gã khổng lồ bán lẻ. Khi bạn mạo hiểm, sử dụng kiến thức chuyên môn mới tìm được của mình một cách khéo léo, hãy nhớ rằng khu rừng kỹ thuật số không bao giờ ngừng phát triển.
Hãy luôn tò mò, tiếp tục mài giũa con dao cạo web của bạn và tiếp tục chinh phục bối cảnh trích xuất dữ liệu luôn thay đổi. Cho đến chuyến thám hiểm táo bạo tiếp theo của chúng tôi, nhà thám hiểm dũng cảm, cầu mong các nhiệm vụ dựa trên dữ liệu của bạn sẽ thành công và bổ ích!

