



Imagínese como un explorador aventurero, sumergiéndose de cabeza en el vasto y misterioso reino del Amazonas, no en la selva tropical, sino en el gigante minorista en línea. Con cada clic, descubres tesoros de valor incalculable y profundizas en el territorio inexplorado de los datos.
En esta emocionante expedición, presentamos una guía paso a paso para navegar por la densa jungla digital del web scraping de Amazon. Prepárese para embarcarse en un viaje como ningún otro, armado con consejos y trucos de expertos para extraer información valiosa con una precisión incomparable.
Tabla de contenido
- Qué datos extraer de Amazon
- Algunos requisitos básicos
- Configuración para raspar
- Raspado de información del producto de Amazon
- Cómo raspar varias páginas en Amazon
- Raspado de Amazon: preguntas frecuentes
- Conclusión
Entonces, ¡reúna valor, póngase sus botas virtuales y comencemos juntos nuestra aventura basada en datos!
Qué datos extraer de Amazon
Existen numerosos puntos de datos asociados con un producto de Amazon, pero los elementos clave en los que debe concentrarse al realizar el scraping incluyen:
- Titulo del producto
- Costo
- Ahorros (cuando corresponda)
- Resumen del artículo
- Lista de funciones asociadas (si está disponible)
- Puntuación de revisión
- Imágenes del producto
Aunque estos son los aspectos principales a considerar al extraer un artículo de Amazon, es importante tener en cuenta que la información que extraiga puede variar según sus objetivos específicos.
Algunos requisitos básicos
Para preparar una sopa necesitamos los ingredientes adecuados. De manera similar, nuestro nuevo web scraper requiere componentes específicos.
- Pitón — Su facilidad de uso y su extensa colección de bibliotecas hacen de Python la mejor opción para el web scraping. Si aún no está instalado, consulte esta guía.
- BeautifulSoup — Esta es una de las muchas bibliotecas de web scraping disponibles para Python. Su simplicidad y uso limpio lo convierten en una opción popular para el web scraping. Después de instalar Python con éxito, puede instalar Beautiful Soup ejecutando: pip install bs4
- Comprensión básica de las etiquetas HTML — Consulta este tutorial para adquirir los conocimientos necesarios sobre etiquetas HTML.
- Navegador web — Dado que necesitamos filtrar mucha información irrelevante de un sitio web, se requieren identificaciones y etiquetas específicas para fines de filtrado. Un navegador web como Google Chrome o Mozilla Firefox resulta útil para identificar esas etiquetas.
Configuración para raspar
Para comenzar, asegúrese de tener Python instalado. Si no tiene Python 3.8 o posterior, visite python.org para descargar e instalar la última versión.
A continuación, cree un directorio para almacenar sus archivos de código de raspado web para Amazon. Generalmente es una buena idea configurar un entorno virtual para su proyecto.
Utilice los siguientes comandos para crear y activar un entorno virtual en macOS y Linux:
$ python3 -m venv .env
$ source .env/bin/activatePara los usuarios de Windows, los comandos serán ligeramente diferentes:
d:amazon>python -m venv .env
d:amazon>.envscriptsactivateAhora es el momento de instalar los paquetes de Python necesarios.
Necesitará paquetes para dos tareas principales: obtener el HTML y analizarlo para extraer datos relevantes.
La biblioteca de solicitudes es una biblioteca de Python de terceros ampliamente utilizada para realizar solicitudes HTTP. Ofrece una interfaz sencilla y fácil de usar para realizar solicitudes HTTP a servidores web y recibir respuestas. Quizás sea la biblioteca más conocida para web scraping.
Sin embargo, la biblioteca de Solicitudes tiene una limitación: devuelve la respuesta HTML como una cadena, lo que puede resultar difícil de buscar elementos específicos como precios de lista al escribir código de web scraping.
Ahí es donde entra en juego Beautiful Soup. Beautiful Soup es una biblioteca de Python diseñada para web scraping que extrae datos de archivos HTML y XML. Le permite recuperar información de una página web buscando etiquetas, atributos o texto específico.
Para instalar ambas bibliotecas, use el siguiente comando:
$ python3 -m pip install requests beautifulsoup4Para usuarios de Windows, reemplace 'python3' con 'python', manteniendo el resto del comando igual:
d:amazon>python -m pip install requests beautifulsoup4Tenga en cuenta que estamos instalando la versión 4 de la biblioteca Beautiful Soup.
Ahora probemos la biblioteca de raspado de solicitudes. Cree un nuevo archivo llamado amazon.py e ingrese el siguiente código:
import requests
url = 'https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L'
response = requests.get(url)
print(response.text)Guarde el archivo y ejecútelo desde la terminal.
$ python3 amazon.pyEn la mayoría de los casos, no podrá ver el HTML deseado. Amazon bloqueará la solicitud y recibirás la siguiente respuesta:
To discuss automated access to Amazon data please contact [email protected].Si imprime el código de estado de respuesta, verá que recibe un error 503 en lugar de un código de éxito 200.
Amazon sabe que esta solicitud no proviene de un navegador y la bloquea. Esta práctica es común entre muchos sitios web. Amazon puede bloquear sus solicitudes y devolver un código de error que comienza con 500 o, a veces, incluso con 400.
Una solución sencilla es enviar encabezados con su solicitud que imiten los enviados por un navegador.
A veces, enviar sólo el agente de usuario es suficiente. En otras ocasiones, es posible que necesites enviar encabezados adicionales, como el encabezado del idioma de aceptación.
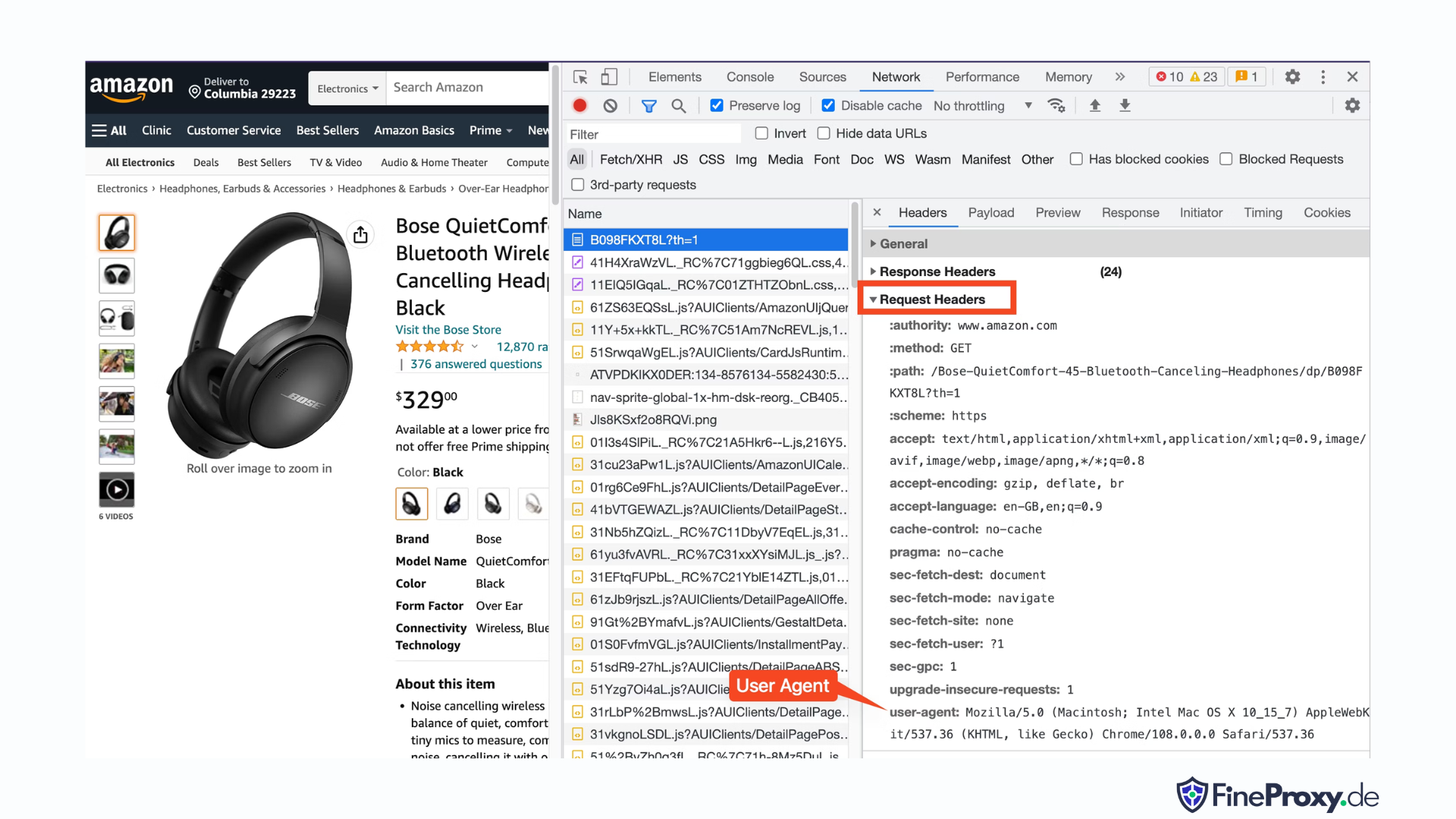
Para encontrar el agente de usuario enviado por su navegador, presione F12, abra la pestaña Red y vuelva a cargar la página. Seleccione la primera solicitud y examine los encabezados de solicitud.
Copie este agente de usuario y cree un diccionario para los encabezados, como este ejemplo con encabezados de agente de usuario y de idioma de aceptación:
custom_headers = { '
user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'accept-language': 'en-GB,en;q=0.9',
}Luego puedes enviar este diccionario como un parámetro opcional en el método get:
response = requests.get(url, headers=custom_headersRaspado de información del producto de Amazon
En el proceso de extracción web de productos de Amazon, normalmente interactuará con dos tipos de páginas: la página de categorías y la página de detalles del producto.
Por ejemplo, visite https://www.amazon.com/b?node=12097479011 o busque auriculares supraaurales en Amazon. La página que muestra los resultados de la búsqueda se conoce como página de categorías.
La página de categorías presenta el título del producto, la imagen del producto, la calificación del producto, el precio del producto y, lo más importante, la página de URL del producto. Para acceder a más información, como descripciones de productos, debe visitar la página de detalles del producto.
Analicemos la estructura de la página de detalles del producto.
Abra la URL de un producto, como https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L, utilizando Chrome u otro navegador moderno. Haga clic derecho en el título del producto y elija Inspeccionar. Se resaltará el formato HTML del título del producto.
Notarás que es una etiqueta span con su atributo id establecido en "productTitle".

De manera similar, haga clic derecho en el precio y seleccione Inspeccionar para ver el marcado HTML del precio.
El componente en dólares del precio está en una etiqueta de intervalo con la clase "un precio total", mientras que el componente de centavos está en otra etiqueta de intervalo con la clase "una fracción de precio".

También puede ubicar la calificación, la imagen y la descripción de la misma manera.
Una vez que haya recopilado esta información, agregue las siguientes líneas al código existente:
response = requests.get(url, headers=custom_headers)
soup = BeautifulSoup(response.text, 'lxml')Beautiful Soup ofrece un método distinto para seleccionar etiquetas utilizando los métodos de búsqueda. También admite selectores CSS como alternativa. Puede utilizar cualquiera de los dos enfoques para lograr el mismo resultado. En este tutorial, utilizaremos selectores CSS, un método universal para seleccionar elementos. Los selectores de CSS son compatibles con casi todas las herramientas de web scraping para extraer información de productos de Amazon.
Ahora está preparado para utilizar el objeto Soup para consultar información específica.
Extrayendo el nombre del producto
El nombre o título del producto se encuentra en un elemento span con la identificación 'productTitle'. Seleccionar elementos usando identificadores únicos es simple.
Considere el siguiente código como ejemplo:
title_element = soup.select_one('#productTitle') Pasamos el selector CSS al método select_one, que devuelve una instancia de elemento.
Para extraer información del texto, utilice el atributo de texto.
title = title_element.textCuando se imprima, es posible que observe algunos espacios en blanco. Para resolver esto, agregue una llamada a la función .strip() de la siguiente manera:
title = title_element.text.strip()Extracción de calificaciones de productos
Obtener calificaciones de productos de Amazon requiere un esfuerzo adicional.
Primero, establezca un selector para la calificación:
#acrPopoverA continuación, utilice la siguiente declaración para seleccionar el elemento que contiene la calificación:
rating_element = soup.select_one('#acrPopover')Tenga en cuenta que el valor de calificación real se encuentra dentro del atributo del título:
rating_text = rating_element.attrs.get('title')
print(rating_text)
# prints '4.6 out of 5 stars'Finalmente, emplee el método de reemplazo para obtener la calificación numérica:
rating = rating_text.replace('out of 5 stars', '')Extracción del precio del producto
El precio del producto se puede encontrar en dos ubicaciones: debajo del título del producto y dentro del cuadro Comprar ahora.
Cualquiera de estas etiquetas se puede utilizar para reducir los precios de los productos de Amazon.
Crea un selector CSS por el precio:
#price_inside_buyboxPase este selector CSS al método select_one de BeautifulSoup así:
price_element = soup.select_one('#price_inside_buybox')Ahora puedes imprimir el precio:
print(price_element.text)Extrayendo imagen
Para extraer la imagen predeterminada, utilice el selector CSS #landingImage. Con esta información, puedes escribir las siguientes líneas de código para obtener la URL de la imagen del atributo src:
image_element = soup.select_one('#landingImage')
image = image_element.attrs.get('src')Extrayendo la descripción del producto
El siguiente paso para extraer datos de productos de Amazon es obtener la descripción del producto.
El proceso sigue siendo consistente: cree un selector CSS y use el método select_one.
El selector CSS para la descripción es:
#productDescriptionEsto nos permite extraer el elemento de la siguiente manera:
description_element = soup.select_one('#productDescription')
print(description_element.text)Manejo de listado de productos
Hemos explorado la extracción de información del producto, pero deberá comenzar con la lista de productos o las páginas de categorías para acceder a los datos del producto.
Por ejemplo, https://www.amazon.com/b?node=12097479011 es la página de categorías para auriculares supraaurales.
Si examina esta página, verá que todos los productos están contenidos dentro de un div que tiene un atributo único [data-asin]. Dentro de ese div, todos los enlaces de productos están en una etiqueta h2.
Con esta información el Selector CSS queda:
[data-asin] h2 aPuede leer el atributo href de este selector y ejecutar un bucle. Sin embargo, recuerda que los enlaces serán relativos. Deberá utilizar el método urljoin para analizar estos enlaces.
from urllib.parse import urljoin
...
def parse_listing(listing_url):
…
link_elements = soup_search.select("[data-asin] h2 a")
page_data = []
for link in link_elements:
full_url = urljoin(search_url, link.attrs.get("href"))
product_info = get_product_info(full_url)
page_data.append(product_info)Manejo de la paginación
El enlace a la página siguiente se encuentra en un enlace que contiene el texto "Siguiente". Puede buscar este enlace utilizando el operador contiene de CSS de la siguiente manera:
next_page_el = soup.select_one('a:contains("Next")')
if next_page_el:
next_page_url = next_page_el.attrs.get('href')
next_page_url = urljoin(listing_url, next_page_url)Exportación de datos de Amazon
Los datos extraídos se devuelven intencionalmente como un diccionario. Puede crear una lista que contenga todos los productos raspados.
def parse_listing(listing_url):
...
page_data = [] for link in link_elements:
...
product_info = get_product_info(full_url)
page_data.append(product_info)Luego puede usar estos datos de página para crear un objeto Pandas DataFrame:
df = pd.DataFrame(page_data)
df.to_csv('headphones.csv', index = False)Cómo raspar varias páginas en Amazon
La extracción de varias páginas en Amazon puede mejorar la eficacia de su proyecto de extracción web al proporcionar un conjunto de datos más amplio para analizar. Al orientar sus anuncios a varias páginas, deberá considerar la paginación, que es el proceso de dividir el contenido en varias páginas.
Aquí están 6 puntos clave a tener en cuenta al raspar varias páginas en Amazon:
- Identifique el patrón de paginación: Primero, analice la estructura de URL de la categoría o las páginas de resultados de búsqueda para comprender cómo Amazon pagina su contenido. Podría ser un parámetro de consulta (por ejemplo, “?página=2”) o un identificador único incrustado en la URL.
- Extraiga el enlace de la página "Siguiente": Localice el elemento (normalmente una etiqueta de anclaje) que contiene el enlace a la página siguiente. Utilice el selector CSS apropiado o el método Beautiful Soup para extraer el atributo href de este elemento, que es la URL de la página siguiente.
- Convierta URL relativas a URL absolutas: Dado que las URL extraídas pueden ser relativas, utilice el
urljoinfunción de laurllib.parsebiblioteca para convertirlas en URL absolutas. - Crea un bucle: Implemente un bucle que recorra las páginas, extrayendo los datos deseados de cada una. El bucle debe continuar hasta que no queden más páginas, lo que se puede determinar comprobando si el enlace de la página "Siguiente" existe en la página actual.
- Agregue retrasos entre solicitudes: Para evitar sobrecargar el servidor de Amazon o activar medidas anti-bot, introduzca retrasos entre solicitudes utilizando el
time.sleep()función de latimebiblioteca. Ajuste la duración del retraso para emular el comportamiento de navegación humana. - Manejo de CAPTCHA y bloques: Si encuentra CAPTCHA o bloques de IP mientras raspa varias páginas, considere usar servidores proxy para rotar direcciones IP o herramientas y servicios de raspado dedicados que puedan manejar estos desafíos automáticamente.
A continuación, encontrará un completo video tutorial de YouTube que lo guiará a través del proceso de extracción de datos de varias páginas en el sitio web de Amazon. El tutorial profundiza en el mundo del web scraping, enfocándose en técnicas que le permitirán recopilar de manera eficiente y efectiva información valiosa de numerosas páginas de Amazon.
A lo largo del tutorial, el presentador demuestra el uso de herramientas y bibliotecas esenciales, como Python, BeautifulSoup y solicitudes, al tiempo que destaca las mejores prácticas para evitar ser bloqueado o detectado por los mecanismos anti-bot de Amazon. El vídeo cubre temas esenciales como el manejo de la paginación, la gestión de límites de velocidad y la imitación del comportamiento de navegación humano.
Además de las instrucciones paso a paso proporcionadas en el vídeo, el tutorial también comparte consejos y trucos útiles para optimizar su experiencia de web scraping. Estos incluyen el uso de proxies para eludir las restricciones de IP, la aleatorización del User-Agent y los encabezados de solicitud, y la implementación de un manejo adecuado de errores para garantizar un proceso de scraping fluido e ininterrumpido.
Raspado de Amazon: preguntas frecuentes
Cuando se trata de extraer datos de Amazon, una popular plataforma de comercio electrónico, hay ciertas cosas que hay que tener en cuenta. Profundicemos en las preguntas frecuentes relacionadas con la extracción de datos de Amazon.
1. ¿Es legal eliminar Amazon?
La extracción de datos disponibles públicamente de Internet es legal, y esto incluye la extracción de Amazon. Puede extraer legalmente información como detalles de productos, descripciones, calificaciones y precios. Sin embargo, al recopilar reseñas de productos, debe tener cuidado con los datos personales y la protección de los derechos de autor. Por ejemplo, el nombre y el avatar del revisor pueden constituir datos personales, mientras que el texto de la reseña puede estar protegido por derechos de autor. Tenga siempre cuidado y busque asesoramiento legal al extraer dichos datos.
2. ¿Amazon permite el scraping?
Aunque el scraping de datos disponibles públicamente es legal, Amazon a veces toma medidas para evitarlo. Estas medidas incluyen solicitudes de limitación de velocidad, prohibición de direcciones IP y uso de huellas digitales del navegador para detectar robots de raspado. Amazon generalmente bloquea el web scraping con un código de respuesta de estado de éxito 200 OK y requiere que pase un CAPTCHA o muestra un mensaje de error HTTP 503 Servicio no disponible para comunicarse con ventas para obtener una API paga.
Hay formas de eludir estas medidas, pero el web scraping ético puede ayudar a evitar que se activen en primer lugar. El web scraping ético implica limitar la frecuencia de las solicitudes, utilizar agentes de usuario adecuados y evitar el scraping excesivo que podría afectar el rendimiento del sitio web. Al realizar un scraping ético, puedes reducir el riesgo de ser prohibido o enfrentar consecuencias legales y al mismo tiempo extraer datos útiles de Amazon.
3. ¿Es ético extraer datos de Amazon?
El scraping ético implica respetar el sitio web de destino. Si bien es poco probable que sobrecargues el sitio web de Amazon con demasiadas solicitudes, aun así debes seguir las pautas éticas de scraping. El scraping ético puede minimizar el riesgo de enfrentar problemas legales o lidiar con medidas anti-scraping.
4. ¿Cómo puedo evitar que me baneen mientras hago scraping de Amazon?
Para evitar que te prohíban al realizar scraping de Amazon, debes limitar tus tasas de solicitudes, evitar el scraping durante las horas pico, utilizar la rotación inteligente de proxy y utilizar encabezados y agentes de usuario adecuados para evitar la detección. Además, extraiga solo los datos que necesita y utilice bibliotecas o herramientas de scraping de terceros.
5. ¿Cuáles son los riesgos de eliminar el Amazonas?
La extracción de datos de Amazon conlleva riesgos potenciales, como acciones legales y suspensión de cuentas. Amazon utiliza medidas anti-bot para detectar y prevenir el scraping, incluidas prohibiciones de direcciones IP, limitación de velocidad y toma de huellas digitales del navegador. Sin embargo, al realizar un scraping ético, se pueden mitigar estos riesgos.
Conclusión
A medida que salimos del apasionante laberinto del web scraping de Amazon, es hora de tomarnos un momento para apreciar los invaluables conocimientos y habilidades que hemos reunido en este emocionante viaje. Con ProxyCompass como su guía de confianza, ha navegado con éxito por los giros y vueltas de la extracción de datos invaluables del gigante minorista. A medida que se aventure, utilizando su nueva experiencia con delicadeza, recuerde que la jungla digital nunca deja de evolucionar.
Mantenga la curiosidad, siga afilando su machete de web scraping y continúe conquistando el panorama en constante cambio de la extracción de datos. Hasta nuestra próxima expedición audaz, intrépido explorador, ¡que tus búsquedas basadas en datos sean fructíferas y gratificantes!

