



Представьте себя отважным исследователем, ныряющим с головой в обширное и загадочное царство Амазонки — не тропических лесов, а гиганта онлайн-торговли. С каждым щелчком мыши вы открываете бесценные сокровища, углубляясь в неизведанную территорию данных.
В этой захватывающей экспедиции мы представляем пошаговое руководство по навигации в густых цифровых джунглях веб-парсинга Amazon. Приготовьтесь отправиться в путешествие, как никто другой, вооружившись советами и приемами экспертов, которые помогут извлечь ценную информацию с беспрецедентной точностью.
Оглавление
- Какие данные собирать с Amazon
- Некоторые основные требования
- Настройка парсинга
- Парсинг информации о продуктах Amazon
- Как парсить несколько страниц на Amazon
- Парсинг Amazon: часто задаваемые вопросы
- Заключение
Итак, наберитесь смелости, наденьте виртуальные ботинки и давайте вместе начнем наше приключение, основанное на данных!
Какие данные собирать с Amazon
Существует множество точек данных, связанных с продуктом Amazon, но ключевые элементы, на которых следует сосредоточиться при очистке, включают в себя:
- Название продукта
- Расходы
- Экономия (если применимо)
- Краткое описание товара
- Список связанных функций (если доступен)
- Оценка по отзывам
- Визуализация продукта
Хотя это основные аспекты, которые следует учитывать при очистке товара Amazon, важно отметить, что извлекаемая вами информация может варьироваться в зависимости от ваших конкретных целей.
Некоторые основные требования
Чтобы приготовить суп, нам нужны подходящие ингредиенты. Точно так же наш новый веб-скребок требует определенных компонентов.
- Питон — Удобство использования и обширная коллекция библиотек делают Python лучшим выбором для парсинга веб-страниц. Если он еще не установлен, обратитесь к этому руководству.
- BeautifulSoup — Это одна из многих библиотек веб-скрапинга, доступных для Python. Простота и чистота использования делают его популярным выбором для парсинга веб-страниц. После успешной установки Python вы можете установить Beautiful Soup, выполнив: pip install bs4
- Базовое понимание HTML-тегов — Обратитесь к этому руководству, чтобы получить необходимые знания о тегах HTML.
- Веб-браузер — Поскольку нам нужно отфильтровать много ненужной информации с веб-сайта, для фильтрации необходимы определенные идентификаторы и теги. Веб-браузер, такой как Google Chrome или Mozilla Firefox, полезен для идентификации этих тегов.
Настройка парсинга
Для начала убедитесь, что у вас установлен Python. Если у вас нет Python 3.8 или более поздней версии, посетите python.org, чтобы загрузить и установить последнюю версию.
Затем создайте каталог для хранения файлов кода веб-скрейпинга для Amazon. Обычно хорошей идеей является создание виртуальной среды для вашего проекта.
Используйте следующие команды для создания и активации виртуальной среды в macOS и Linux:
$ python3 -m venv .env
$ source .env/bin/activateДля пользователей Windows команды будут немного другими:
d:amazon>python -m venv .env
d:amazon>.envscriptsactivateТеперь пришло время установить необходимые пакеты Python.
Вам понадобятся пакеты для двух основных задач: получения HTML и его анализа для извлечения соответствующих данных.
Библиотека Requests — это широко используемая сторонняя библиотека Python для выполнения HTTP-запросов. Он предлагает простой и удобный интерфейс для отправки HTTP-запросов к веб-серверам и получения ответов. Это, пожалуй, самая известная библиотека для парсинга веб-страниц.
Однако у библиотеки Requests есть ограничение: она возвращает HTML-ответ в виде строки, из-за чего может быть сложно найти определенные элементы, например, список цен, при написании кода веб-скрапинга.
Вот тут-то и приходит на помощь Beautiful Soup. Beautiful Soup — это библиотека Python, предназначенная для парсинга веб-страниц и извлекающая данные из файлов HTML и XML. Он позволяет получать информацию с веб-страницы путем поиска тегов, атрибутов или определенного текста.
Чтобы установить обе библиотеки, используйте следующую команду:
$ python3 -m pip install requests beautifulsoup4Для пользователей Windows замените «python3» на «python», оставив остальную часть команды прежней:
d:amazon>python -m pip install requests beautifulsoup4Обратите внимание, что мы устанавливаем версию 4 библиотеки Beautiful Soup.
Теперь давайте протестируем библиотеку парсинга Requests. Создайте новый файл с именем amazon.py и введите следующий код:
import requests
url = 'https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L'
response = requests.get(url)
print(response.text)Сохраните файл и запустите его из терминала.
$ python3 amazon.pyВ большинстве случаев вы не сможете просмотреть нужный HTML-код. Amazon заблокирует запрос, и вы получите следующий ответ:
To discuss automated access to Amazon data please contact [email protected].Если вы распечатаете код ответа.status_code, вы увидите, что получаете ошибку 503 вместо кода успеха 200.
Amazon знает, что этот запрос пришел не из браузера, и блокирует его. Эта практика распространена среди многих веб-сайтов. Amazon может заблокировать ваши запросы и вернуть код ошибки, начинающийся с 500, а иногда даже с 400.
Простое решение — отправить вместе с вашим запросом заголовки, имитирующие заголовки, отправленные браузером.
Иногда достаточно отправить только пользовательский агент. В других случаях вам может потребоваться отправить дополнительные заголовки, например заголовок Accept-Language.
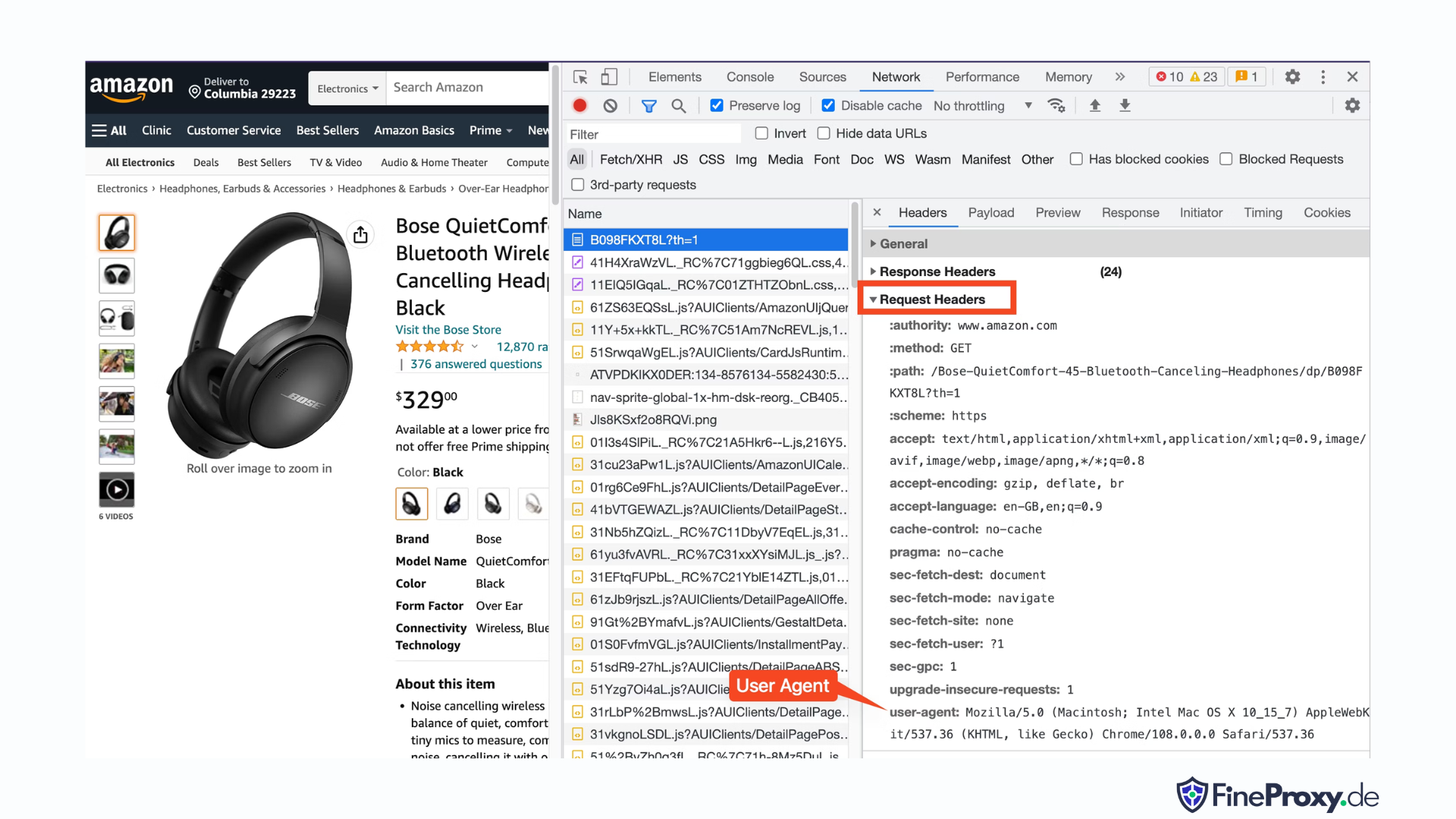
Чтобы найти пользовательский агент, отправленный вашим браузером, нажмите F12, откройте вкладку «Сеть» и перезагрузите страницу. Выберите первый запрос и просмотрите заголовки запроса.
Скопируйте этот пользовательский агент и создайте словарь для заголовков, как в этом примере с заголовками пользовательского агента и языка принятия:
custom_headers = { '
user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'accept-language': 'en-GB,en;q=0.9',
}Затем вы можете отправить этот словарь в качестве необязательного параметра в методе get:
response = requests.get(url, headers=custom_headersПарсинг информации о продуктах Amazon
В процессе парсинга продуктов Amazon вы обычно используете страницы двух типов: страницу категории и страницу сведений о продукте.
Например, посетите https://www.amazon.com/b?node=12097479011 или найдите наушники-вкладыши на Amazon. Страница, отображающая результаты поиска, называется страницей категории.
На странице категории представлены название продукта, изображение продукта, рейтинг продукта, цена продукта и, что наиболее важно, страница URL-адресов продукта. Чтобы получить доступ к дополнительной информации, такой как описания продуктов, вам необходимо посетить страницу сведений о продукте.
Давайте проанализируем структуру страницы сведений о товаре.
Откройте URL-адрес продукта, например https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L, используя Chrome или другой современный браузер. Щелкните правой кнопкой мыши название продукта и выберите «Проверить». HTML-разметка названия продукта будет выделена.
Вы заметите, что это тег span с атрибутом id, установленным на «productTitle».

Аналогичным образом щелкните цену правой кнопкой мыши и выберите «Проверить», чтобы просмотреть HTML-разметку цены.
Долларовый компонент цены находится в теге диапазона с классом «a-price-whole», а компонент в центах находится в другом теге диапазона с классом «a-price-fraction».

Таким же образом вы также можете найти рейтинг, изображение и описание.
Собрав эту информацию, добавьте следующие строки в существующий код:
response = requests.get(url, headers=custom_headers)
soup = BeautifulSoup(response.text, 'lxml')Beautiful Soup предлагает особый метод выбора тегов с помощью методов поиска. В качестве альтернативы он также поддерживает селекторы CSS. Вы можете использовать любой подход для достижения одного и того же результата. В этом уроке мы будем использовать селекторы CSS — универсальный метод выбора элементов. Селекторы CSS совместимы практически со всеми инструментами веб-скрапинга для извлечения информации о продуктах Amazon.
Теперь вы готовы использовать объект Soup для запроса конкретной информации.
Извлечение названия продукта
Название или название продукта находится в элементе span с идентификатором ProductTitle. Выбирать элементы по уникальным идентификаторам очень просто.
В качестве примера рассмотрим следующий код:
title_element = soup.select_one('#productTitle') Мы передаем селектор CSS методу select_one, который возвращает экземпляр элемента.
Чтобы извлечь информацию из текста, используйте атрибут text.
title = title_element.textПри печати вы можете заметить несколько пробелов. Чтобы решить эту проблему, добавьте вызов функции .strip() следующим образом:
title = title_element.text.strip()Извлечение рейтингов продуктов
Получение рейтингов продуктов Amazon требует некоторых дополнительных усилий.
Сначала установим селектор для рейтинга:
#acrPopoverЗатем используйте следующий оператор, чтобы выбрать элемент, содержащий рейтинг:
rating_element = soup.select_one('#acrPopover')Обратите внимание, что фактическое значение рейтинга находится в атрибуте title:
rating_text = rating_element.attrs.get('title')
print(rating_text)
# prints '4.6 out of 5 stars'Наконец, используйте метод replace для получения числового рейтинга:
rating = rating_text.replace('out of 5 stars', '')Извлечение цены продукта
Цену продукта можно найти в двух местах — под названием продукта и в поле «Купить сейчас».
Любой из этих тегов можно использовать для сбора цен на продукты Amazon.
Создайте CSS-селектор по цене:
#price_inside_buyboxПередайте этот CSS-селектор методу select_one BeautifulSoup следующим образом:
price_element = soup.select_one('#price_inside_buybox')Теперь вы можете распечатать цену:
print(price_element.text)Извлечение изображения
Чтобы очистить изображение по умолчанию, используйте селектор CSS #landingImage. Используя эту информацию, вы можете написать следующие строки кода, чтобы получить URL-адрес изображения из атрибута src:
image_element = soup.select_one('#landingImage')
image = image_element.attrs.get('src')Извлечение описания продукта
Следующим шагом в извлечении данных о продуктах Amazon является получение описания продукта.
Процесс остается последовательным — создайте селектор CSS и используйте метод select_one.
CSS-селектор для описания:
#productDescriptionЭто позволяет нам извлечь элемент следующим образом:
description_element = soup.select_one('#productDescription')
print(description_element.text)Обработка списка продуктов
Мы изучили сбор информации о продуктах, но вам нужно начать со списка продуктов или страниц категорий, чтобы получить доступ к данным о продуктах.
Например, https://www.amazon.com/b?node=12097479011 это страница категории полноразмерных наушников.
Если вы изучите эту страницу, вы увидите, что все продукты содержатся в блоке div с уникальным атрибутом [data-asin]. Внутри этого div все ссылки на продукты находятся в теге h2.
Благодаря этой информации селектор CSS:
[data-asin] h2 aВы можете прочитать атрибут href этого селектора и запустить цикл. Однако помните, что ссылки будут относительными. Вам нужно будет использовать метод urljoin для анализа этих ссылок.
from urllib.parse import urljoin
...
def parse_listing(listing_url):
…
link_elements = soup_search.select("[data-asin] h2 a")
page_data = []
for link in link_elements:
full_url = urljoin(search_url, link.attrs.get("href"))
product_info = get_product_info(full_url)
page_data.append(product_info)Обработка нумерации страниц
Ссылка на следующую страницу находится в ссылке, содержащей текст «Далее». Вы можете найти эту ссылку, используя оператор CSS contains следующим образом:
next_page_el = soup.select_one('a:contains("Next")')
if next_page_el:
next_page_url = next_page_el.attrs.get('href')
next_page_url = urljoin(listing_url, next_page_url)Экспорт данных Amazon
Собранные данные намеренно возвращаются в виде словаря. Вы можете создать список, содержащий все очищенные продукты.
def parse_listing(listing_url):
...
page_data = [] for link in link_elements:
...
product_info = get_product_info(full_url)
page_data.append(product_info)Затем вы можете использовать эти page_data для создания объекта Pandas DataFrame:
df = pd.DataFrame(page_data)
df.to_csv('headphones.csv', index = False)Как парсить несколько страниц на Amazon
Парсинг нескольких страниц на Amazon может повысить эффективность вашего проекта парсинга веб-страниц, предоставляя более широкий набор данных для анализа. При таргетинге на несколько страниц вам необходимо учитывать разбиение на страницы, то есть процесс разделения контента на несколько страниц.
Вот 6 ключевых моментов, о которых следует помнить при парсинге нескольких страниц на Amazon:
- Определите шаблон нумерации страниц: Сначала проанализируйте структуру URL-адресов страниц категорий или результатов поиска, чтобы понять, как Amazon разбивает свой контент на страницы. Это может быть параметр запроса (например, «?page=2») или уникальный идентификатор, встроенный в URL-адрес.
- Извлеките ссылку на страницу «Далее»: Найдите элемент (обычно тег привязки), содержащий ссылку на следующую страницу. Используйте соответствующий селектор CSS или метод Beautiful Soup, чтобы извлечь атрибут href этого элемента, который является URL-адресом следующей страницы.
- Преобразуйте относительные URL-адреса в абсолютные URL-адреса: Поскольку извлеченные URL-адреса могут быть относительными, используйте
urljoinфункция отurllib.parseбиблиотека для преобразования их в абсолютные URL-адреса. - Создайте цикл: Реализуйте цикл, который перебирает страницы, извлекая нужные данные из каждой. Цикл должен продолжаться до тех пор, пока не останется больше страниц, что можно определить, проверив, существует ли ссылка «Следующая» страница на текущей странице.
- Добавьте задержки между запросами: Чтобы избежать перегрузки сервера Amazon или запуска мер по борьбе с ботами, введите задержки между запросами с помощью
time.sleep()функция отtimeбиблиотека. Отрегулируйте продолжительность задержки, чтобы имитировать поведение человека в Интернете. - Обработка CAPTCHA и блоков: Если вы столкнулись с CAPTCHA или блокировкой IP-адресов при парсинге нескольких страниц, рассмотрите возможность использования прокси-серверов для ротации IP-адресов или специальных инструментов и сервисов парсинга, которые могут решать эти проблемы автоматически.
Ниже вы найдете подробное видеоруководство YouTube, которое проведет вас через процесс извлечения данных с нескольких страниц веб-сайта Amazon. Учебное пособие глубоко погружается в мир парсинга веб-страниц, уделяя особое внимание методам, которые позволят вам эффективно и результативно собирать ценную информацию с многочисленных страниц Amazon.
На протяжении всего руководства ведущий демонстрирует использование основных инструментов и библиотек, таких как Python, BeautifulSoup и запросы, а также выделяет лучшие практики, позволяющие избежать блокировки или обнаружения механизмами защиты от ботов Amazon. В видео рассматриваются такие важные темы, как обработка нумерации страниц, управление ограничениями скорости и имитация человеческого поведения при просмотре.
В дополнение к пошаговым инструкциям, представленным в видео, в руководстве также приводятся полезные советы и приемы, которые помогут оптимизировать процесс парсинга веб-страниц. К ним относятся использование прокси-серверов для обхода ограничений IP, рандомизация заголовков User-Agent и запросов, а также реализация правильной обработки ошибок для обеспечения плавного и непрерывного процесса очистки.
Парсинг Amazon: часто задаваемые вопросы
Когда дело доходит до извлечения данных из Amazon, популярной платформы электронной коммерции, нужно помнить о некоторых вещах. Давайте углубимся в часто задаваемые вопросы, связанные со сбором данных Amazon.
1. Законно ли парсить Amazon?
Сбор общедоступных данных из Интернета является законным, включая сбор данных с Amazon. Вы можете на законных основаниях собирать такую информацию, как сведения о продуктах, описания, рейтинги и цены. Однако при парсинге обзоров продуктов следует соблюдать осторожность в отношении личных данных и защиты авторских прав. Например, имя и аватар рецензента могут представлять собой персональные данные, а текст отзыва может быть защищен авторскими правами. Всегда соблюдайте осторожность и обращайтесь за юридической консультацией при сборе таких данных.
2. Разрешает ли Amazon парсинг?
Хотя сбор общедоступных данных является законным, Amazon иногда принимает меры для предотвращения сбора данных. Эти меры включают ограничение скорости запросов, запрет IP-адресов и использование снятия отпечатков пальцев браузера для обнаружения парсинг-ботов. Amazon обычно блокирует парсинг веб-страниц с помощью кода ответа об успешном статусе 200 OK и требует от вас пройти CAPTCHA или отображает сообщение об ошибке HTTP 503, служба недоступна, чтобы связаться с отделом продаж для получения платного API.
Есть способы обойти эти меры, но этический парсинг веб-страниц может помочь в первую очередь избежать их запуска. Этический парсинг веб-сайтов предполагает ограничение частоты запросов, использование соответствующих пользовательских агентов и избежание чрезмерного парсинга, который может повлиять на производительность веб-сайта. Этично соблюдая парсинг, вы можете снизить риск быть забаненным или столкнуться с юридическими последствиями, сохраняя при этом полезные данные из Amazon.
3. Этично ли очищать данные Amazon?
Этический парсинг подразумевает уважение к целевому веб-сайту. Хотя маловероятно, что вы перегрузите веб-сайт Amazon слишком большим количеством запросов, вам все равно следует следовать этическим принципам парсинга. Этический парсинг может свести к минимуму риск столкнуться с юридическими проблемами или принять меры против парсинга.
4. Как мне избежать бана при парсинге Amazon?
Чтобы избежать блокировки при парсинге Amazon, вам следует ограничить частоту запросов, избегать парсинга в часы пик, использовать интеллектуальную ротацию прокси-серверов и использовать соответствующие пользовательские агенты и заголовки, чтобы избежать обнаружения. Кроме того, извлекайте только те данные, которые вам нужны, и используйте сторонние инструменты очистки или библиотеки очистки.
5. Каковы риски парсинга Amazon?
Сбор данных Amazon несет в себе потенциальные риски, такие как судебные иски и блокировка учетной записи. Amazon использует меры по борьбе с ботами для обнаружения и предотвращения парсинга, включая блокировку IP-адресов, ограничение скорости и снятие отпечатков пальцев браузера. Однако, соблюдая этические нормы парсинга, вы можете снизить эти риски.
Заключение
Когда мы выходим из увлекательного лабиринта веб-скрапинга Amazon, пришло время воспользоваться моментом, чтобы оценить бесценные знания и навыки, которые мы накопили в этом волнующем путешествии. Используя ProxyCompass в качестве вашего надежного руководства, вы успешно справились с тонкостями извлечения бесценных данных из гиганта розничной торговли. Отправляясь вперед, с изяществом применяя свой вновь обретенный опыт, помните, что цифровые джунгли никогда не перестают развиваться.
Сохраняйте любопытство, продолжайте оттачивать свое мачете для парсинга веб-страниц и продолжайте покорять постоянно меняющийся ландшафт извлечения данных. До нашей следующей смелой экспедиции, бесстрашный исследователь, пусть твои поиски, основанные на данных, будут плодотворными и полезными!

