



将自己想象成一位富有冒险精神的探险家,一头扎进亚马逊广阔而神秘的领域——不是雨林,而是在线零售巨头。每次点击,您都会发现无价的宝藏,更深入地探索未知的数据领域。
在这次激动人心的探险中,我们将提供分步指南,帮助您在亚马逊网络抓取的密集数字丛林中导航。准备好踏上一场与众不同的旅程吧,借助专家的提示和技巧,以无与伦比的精度提取有价值的信息。
目录
所以,鼓起勇气,穿上虚拟靴,让我们一起开始数据驱动的冒险吧!
从亚马逊抓取哪些数据
与亚马逊产品相关的数据点有很多,但抓取时需要关注的关键要素包括:
- 产品名称
- 成本
- 节省(如适用)
- 项目概要
- 相关功能列表(如果有)
- 评分
- 产品视觉效果
虽然这些是抓取亚马逊商品时需要考虑的主要方面,但需要注意的是,您提取的信息可能会因您的具体目标而异。
一些基本要求
要煮一碗汤,我们需要合适的配料。同样,我们的新网页抓取工具也需要特定的组件。
- Python — 其用户友好性和广泛的库集合使 Python 成为网络抓取的首选。如果尚未安装,请参阅本指南。
- BeautifulSoup — 这是可用于 Python 的众多网络抓取库之一。其简单性和简洁的用法使其成为网络抓取的流行选择。成功安装Python后,您可以通过运行以下命令安装Beautiful Soup: pip install bs4
- HTML 标签的基本理解 — 查阅本教程以获取有关 HTML 标签的必要知识。
- 网页浏览器 — 由于我们需要从网站中过滤掉大量不相关的信息,因此需要特定的 id 和标签来进行过滤。 Google Chrome 或 Mozilla Firefox 等网络浏览器对于识别这些标签非常有用。
设置抓取
首先,确保您已安装 Python。如果您没有 Python 3.8 或更高版本,请访问 python.org 下载并安装最新版本。
接下来,创建一个目录来存储 Amazon 的网络抓取代码文件。为您的项目设置虚拟环境通常是个好主意。
使用以下命令在 macOS 和 Linux 上创建并激活虚拟环境:
$ python3 -m venv .env
$ source .env/bin/activate对于 Windows 用户,命令会略有不同:
d:amazon>python -m venv .env
d:amazon>.envscriptsactivate现在是时候安装必要的 Python 包了。
您将需要包来完成两个主要任务:获取 HTML 并解析它以提取相关数据。
Requests 库是一个广泛使用的第三方 Python 库,用于发出 HTTP 请求。它提供了一个简单易用的界面,用于向 Web 服务器发出 HTTP 请求并接收响应。它可能是最著名的 Web 抓取库。
但是,Requests 库有一个限制:它以字符串形式返回 HTML 响应,这在编写网页抓取代码时很难搜索特定元素,例如列出价格。
这就是 Beautiful Soup 的作用所在。Beautiful Soup 是一个专为网页抓取而设计的 Python 库,可从 HTML 和 XML 文件中提取数据。它允许您通过搜索标签、属性或特定文本从网页中检索信息。
要安装这两个库,请使用以下命令:
$ python3 -m pip install requests beautifulsoup4对于 Windows 用户,将“python3”替换为“python”,其余命令保持不变:
d:amazon>python -m pip install requests beautifulsoup4请注意,我们正在安装 Beautiful Soup 库的第 4 版。
现在让我们测试 Requests 抓取库。创建一个名为 amazon.py 的新文件并输入以下代码:
import requests
url = 'https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L'
response = requests.get(url)
print(response.text)保存文件并从终端运行它。
$ python3 amazon.py在大多数情况下,您将无法查看所需的 HTML。亚马逊将阻止该请求,您将收到以下响应:
To discuss automated access to Amazon data please contact [email protected].如果您打印 response.status_code,您会发现收到 503 错误而不是 200 成功代码。
亚马逊知道这个请求不是来自浏览器,因此会阻止它。这种做法在许多网站中很常见。亚马逊可能会阻止您的请求并返回以 500 开头的错误代码,有时甚至返回 400 开头的错误代码。
一个简单的解决方案是随您的请求发送标头,模仿浏览器发送的标头。
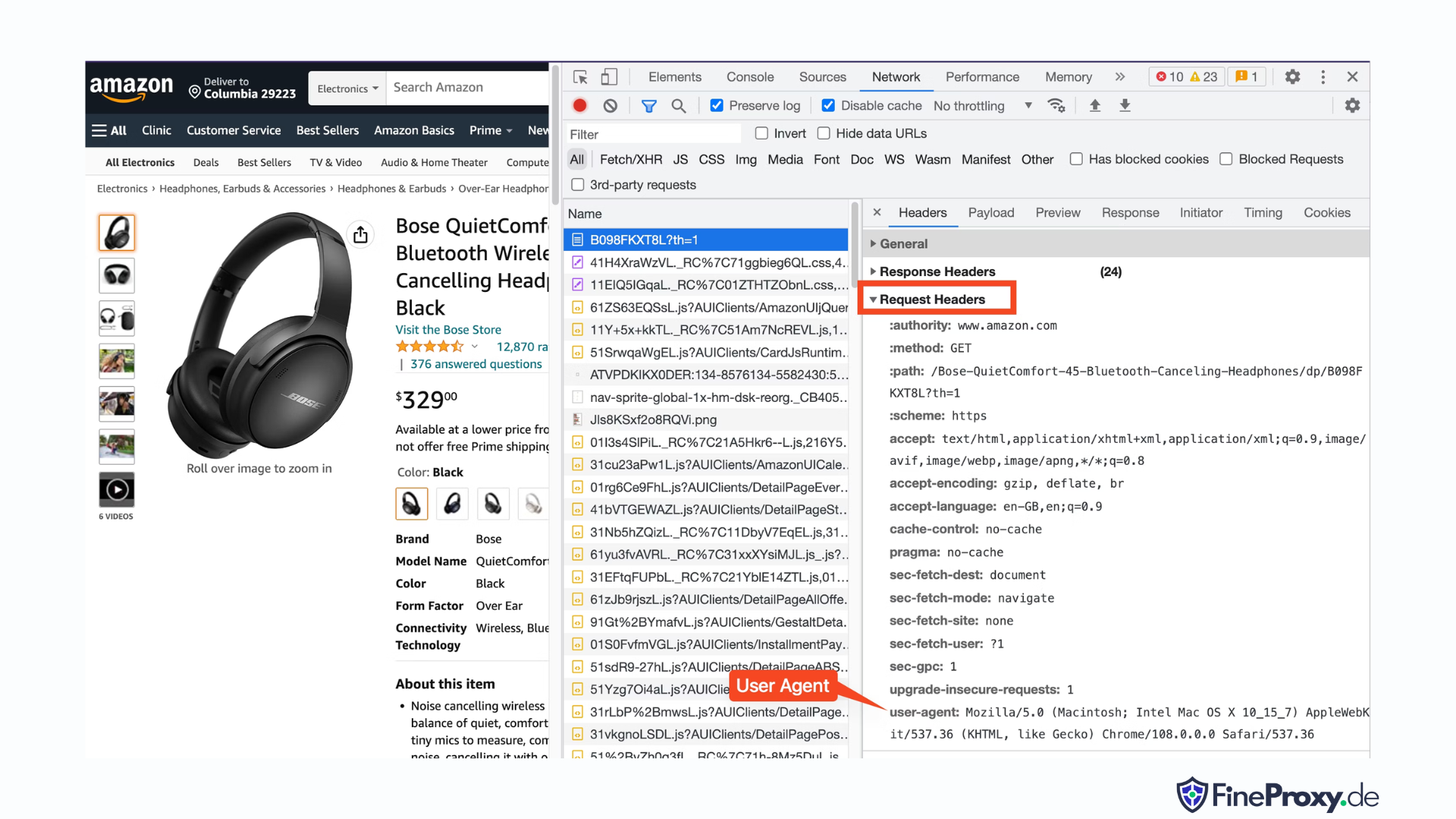
有时,仅发送用户代理就足够了。其他时候,您可能需要发送其他标头,例如接受语言标头。
要查找浏览器发送的用户代理,请按 F12,打开“网络”选项卡,然后重新加载页面。选择第一个请求并检查请求标头。
复制此用户代理并为标头创建一个字典,如本例所示,其中包含用户代理和接受语言标头:
custom_headers = { '
user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'accept-language': 'en-GB,en;q=0.9',
}然后您可以将该字典作为 get 方法中的可选参数发送:
response = requests.get(url, headers=custom_headers抓取亚马逊产品信息
在网页抓取亚马逊产品的过程中,您通常会接触两种类型的页面:类别页面和产品详细信息页面。
例如,访问 https://www.amazon.com/b?node=12097479011 或者在亚马逊上搜索 Over-Ear Headphones。显示搜索结果的页面称为类别页面。
类别页面显示产品标题、产品图片、产品评级、产品价格,以及最重要的产品 URL 页面。要访问更多信息,例如产品描述,您必须访问产品详细信息页面。
我们来分析一下商品详情页的结构。
打开产品 URL,例如 https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L,使用 Chrome 或其他现代浏览器。右键单击产品标题并选择检查。产品标题的 HTML 标记将突出显示。
您会注意到它是一个 span 标记,其 id 属性设置为“productTitle”。

同样,右键单击价格并选择“检查”以查看价格的 HTML 标记。
价格的美元部分位于具有“a-price-whole”类的跨度标签中,而美分部分位于具有“a-price-fraction”类的另一个跨度标签中。

您还可以以相同的方式找到评级、图像和描述。
收集到这些信息后,将以下几行添加到现有代码中:
response = requests.get(url, headers=custom_headers)
soup = BeautifulSoup(response.text, 'lxml')Beautiful Soup 提供了一种使用 find 方法选择标签的独特方法。它还支持 CSS 选择器作为替代方案。您可以使用任一方法来实现相同的结果。在本教程中,我们将使用 CSS 选择器,这是一种选择元素的通用方法。 CSS 选择器与几乎所有用于提取亚马逊产品信息的网络抓取工具兼容。
现在您准备使用 Soup 对象来查询特定信息。
提取产品名称
产品名称或标题可在 ID 为“productTitle”的 span 元素中找到。使用唯一的 id 选择元素很简单。
以以下代码为例:
title_element = soup.select_one('#productTitle') 我们将 CSS 选择器传递给 select_one 方法,该方法返回一个元素实例。
要从文本中提取信息,请使用文本属性。
title = title_element.text打印时,您可能会注意到一些空格。要解决此问题,请添加 .strip() 函数调用,如下所示:
title = title_element.text.strip()提取产品评分
获得亚马逊产品评级需要一些额外的努力。
首先,建立评级的选择器:
#acrPopover接下来,使用以下语句选择包含评级的元素:
rating_element = soup.select_one('#acrPopover')请注意,实际评分值可在 title 属性中找到:
rating_text = rating_element.attrs.get('title')
print(rating_text)
# prints '4.6 out of 5 stars'最后,使用replace方法获得数值评分:
rating = rating_text.replace('out of 5 stars', '')提取产品价格
产品价格可以在两个位置找到——产品标题下方和立即购买框内。
这些标签中的任何一个都可以用来抓取亚马逊产品的价格。
创建价格的 CSS 选择器:
#price_inside_buybox将此 CSS 选择器传递给 BeautifulSoup 的 select_one 方法,如下所示:
price_element = soup.select_one('#price_inside_buybox')现在,您可以打印价格:
print(price_element.text)提取图像
要抓取默认图像,请使用 CSS 选择器 #landingImage。有了这些信息,您可以编写以下代码行来从 src 属性获取图像 URL:
image_element = soup.select_one('#landingImage')
image = image_element.attrs.get('src')提取产品描述
提取亚马逊产品数据的下一步是获取产品描述。
过程保持一致——创建一个 CSS 选择器并使用 select_one 方法。
描述的 CSS 选择器是:
#productDescription这使得我们可以按如下方式提取元素:
description_element = soup.select_one('#productDescription')
print(description_element.text)处理产品列表
我们已经探索了抓取产品信息,但您需要从产品列表或类别页面开始才能访问产品数据。
例如, https://www.amazon.com/b?node=12097479011 是耳罩式耳机的分类页面。
如果您查看此页面,您会发现所有产品都包含在具有唯一属性 [data-asin] 的 div 中。在该 div 中,所有产品链接都位于 h2 标签中。
有了这些信息,CSS 选择器就是:
[data-asin] h2 a您可以读取此选择器的 href 属性并运行循环。但是,请记住这些链接是相对的。您需要使用 urljoin 方法来解析这些链接。
from urllib.parse import urljoin
...
def parse_listing(listing_url):
…
link_elements = soup_search.select("[data-asin] h2 a")
page_data = []
for link in link_elements:
full_url = urljoin(search_url, link.attrs.get("href"))
product_info = get_product_info(full_url)
page_data.append(product_info)处理分页
到下一页的链接位于包含文本“下一步”的链接中。您可以使用 CSS 的 contains 运算符搜索该链接,如下所示:
next_page_el = soup.select_one('a:contains("Next")')
if next_page_el:
next_page_url = next_page_el.attrs.get('href')
next_page_url = urljoin(listing_url, next_page_url)导出亚马逊数据
抓取的数据会以字典的形式返回。您可以创建一个包含所有抓取产品的列表。
def parse_listing(listing_url):
...
page_data = [] for link in link_elements:
...
product_info = get_product_info(full_url)
page_data.append(product_info)然后,您可以使用此 page_data 创建 Pandas DataFrame 对象:
df = pd.DataFrame(page_data)
df.to_csv('headphones.csv', index = False)如何在亚马逊上抓取多个页面
在亚马逊上抓取多个页面可以提供更广泛的数据集进行分析,从而提高您的网页抓取项目的效率。当以多个页面为目标时,您需要考虑分页,即将内容划分到多个页面的过程。
这里有 需要牢记的6个要点 在 Amazon 上抓取多个页面时:
- 识别分页模式: 首先,分析类别或搜索结果页面的 URL 结构,了解亚马逊如何对内容进行分页。这可能是查询参数(例如“?page=2”)或嵌入在 URL 中的唯一标识符。
- 提取“下一页”链接: 找到包含下一页链接的元素(通常是锚标记)。使用适当的 CSS 选择器或 Beautiful Soup 方法提取此元素的 href 属性,即下一页的 URL。
- 将相对 URL 转换为绝对 URL: 由于提取的 URL 可能是相对的,因此使用
urljoin函数从urllib.parse库将它们转换为绝对 URL。 - 创建循环: 实现一个迭代页面的循环,从每个页面中抓取所需的数据。循环应继续下去,直到没有更多页面为止,这可以通过检查当前页面上是否存在“下一页”页面链接来确定。
- 在请求之间添加延迟: 为了避免亚马逊服务器过载或触发反机器人措施,使用
time.sleep()函数从time库。调整延迟时间以模拟人类的浏览行为。 - 处理验证码和块: 如果在抓取多个页面时遇到 CAPTCHA 或 IP 阻止,请考虑使用代理来轮换 IP 地址或使用可以自动处理这些挑战的专用抓取工具和服务。
下面,您将看到一个全面的 YouTube 视频教程,该教程将指导您完成从亚马逊网站的多个页面提取数据的过程。该教程深入探讨了网络抓取的世界,重点介绍了一些技术,这些技术将使您能够高效、有效地从众多亚马逊页面收集有价值的信息。
在整个教程中,演示者演示了基本工具和库(例如 Python、BeautifulSoup 和请求)的使用,同时强调了避免被 Amazon 反机器人机制阻止或检测到的最佳做法。视频涵盖了处理分页、管理速率限制和模仿人类浏览行为等基本主题。
除了视频中提供的分步说明外,本教程还分享了一些有用的技巧和窍门,以优化您的网页抓取体验。这些技巧和窍门包括使用代理绕过 IP 限制、随机化 User-Agent 和请求标头,以及实施适当的错误处理以确保抓取过程顺畅且不间断。
抓取亚马逊:常见问题解答
当从流行的电子商务平台亚马逊提取数据时,需要注意一些事项。让我们深入探讨与抓取亚马逊数据相关的常见问题。
1. 抓取亚马逊数据合法吗?
从互联网上抓取公开数据是合法的,这包括抓取亚马逊。您可以合法地抓取产品详细信息、描述、评级和价格等信息。但是,在抓取产品评论时,您应该谨慎对待个人数据和版权保护。例如,评论者的姓名和头像可能构成个人数据,而评论文本可能受版权保护。抓取此类数据时请务必谨慎行事并寻求法律建议。
2.亚马逊允许抓取数据吗?
尽管抓取公开可用的数据是合法的,但亚马逊有时会采取措施防止抓取。这些措施包括限制请求速率、禁止 IP 地址以及使用浏览器指纹识别来检测抓取机器人。亚马逊通常会使用 200 OK 成功状态响应代码来阻止网络抓取,并要求您通过 CAPTCHA 或显示 HTTP 错误 503 服务不可用消息以联系销售人员获取付费 API。
有很多方法可以规避这些措施,但道德网络抓取可以帮助避免首先触发这些措施。符合道德的网络抓取涉及限制请求频率、使用适当的用户代理以及避免可能影响网站性能的过度抓取。通过道德地抓取,您可以降低被禁止或面临法律后果的风险,同时仍然从亚马逊提取有用的数据。
3. 抓取亚马逊数据合乎道德吗?
道德抓取涉及尊重目标网站。虽然您不太可能因过多的请求而导致亚马逊网站超载,但您仍然应该遵循道德抓取准则。道德抓取可以最大限度地减少面临法律问题或处理反抓取措施的风险。
4. 如何避免在抓取亚马逊数据时被禁止?
为了避免在抓取亚马逊数据时被禁止,您应该限制请求率,避免在高峰时段抓取数据,使用智能代理轮换,并使用适当的用户代理和标头来避免被检测到。此外,仅提取您需要的数据并使用第三方抓取工具或抓取库。
5. 抓取亚马逊数据的风险有哪些?
抓取亚马逊数据存在潜在风险,例如法律诉讼和账户暂停。亚马逊使用反机器人措施来检测和防止抓取,包括 IP 地址禁令、速率限制和浏览器指纹识别。但是,通过合乎道德地抓取,您可以减轻这些风险。
结论
当我们走出亚马逊网络抓取的迷宫时,是时候花点时间欣赏我们在这段令人振奋的旅程中积累的宝贵知识和技能了。有了 ProxyCompass 作为您值得信赖的向导,您已经成功地从零售巨头那里提取了无价的数据。当您继续冒险,巧妙地运用您新获得的专业知识时,请记住,数字丛林永远不会停止发展。
保持好奇心,不断磨砺你的网络抓取砍刀,并继续征服不断变化的数据提取领域。在我们下一次大胆的探险之前,无畏的探险家,愿您的数据驱动任务富有成果并有所回报!

