



Imagine-se como um explorador aventureiro, mergulhando de cabeça no vasto e misterioso reino da Amazônia – não na floresta tropical, mas no gigante do varejo online. A cada clique, você descobre tesouros inestimáveis, aprofundando-se no território desconhecido dos dados.
Nesta expedição emocionante, apresentamos um guia passo a passo para navegar na densa selva digital do web scraping da Amazon. Prepare-se para embarcar em uma jornada como nenhuma outra, munido de dicas e truques de especialistas para extrair informações valiosas com precisão incomparável.
Índice
- Quais dados extrair da Amazon
- Alguns requisitos básicos
- Configuração para raspagem
- Raspando informações de produtos da Amazon
- Como raspar várias páginas na Amazon
- Raspando a Amazon: Perguntas frequentes
- Conclusão
Então, reúna sua coragem, calce suas botas virtuais e vamos começar juntos nossa aventura baseada em dados!
Quais dados extrair da Amazon
Existem vários pontos de dados associados a um produto da Amazon, mas os principais elementos nos quais você deve se concentrar durante a raspagem incluem:
- Título do produto
- Custo
- Poupança (quando aplicável)
- Resumo do item
- Lista de recursos associados (se disponível)
- Pontuação da revisão
- Visuais do produto
Embora esses sejam os principais aspectos a serem considerados ao extrair um item da Amazon, é importante observar que as informações que você extrai podem variar dependendo de seus objetivos específicos.
Alguns requisitos básicos
Para preparar uma sopa, precisamos dos ingredientes certos. Da mesma forma, nosso novo web scraper requer componentes específicos.
- Pitão — Sua facilidade de uso e extensa coleção de bibliotecas tornam o Python a melhor escolha para web scraping. Se ainda não estiver instalado, consulte este guia.
- BeautifulSoup — Esta é uma das muitas bibliotecas de web scraping disponíveis para Python. Sua simplicidade e uso limpo o tornam uma escolha popular para web scraping. Depois de instalar o Python com sucesso, você pode instalar o Beautiful Soup executando: pip install bs4
- Compreensão básica de tags HTML — Consulte este tutorial para adquirir os conhecimentos necessários sobre tags HTML.
- Navegador da Web — Como precisamos filtrar muitas informações irrelevantes de um site, são necessários IDs e tags específicos para fins de filtragem. Um navegador como Google Chrome ou Mozilla Firefox é útil para identificar essas tags.
Configuração para raspagem
Para começar, certifique-se de ter o Python instalado. Se você não possui o Python 3.8 ou posterior, visite python.org para baixar e instalar a versão mais recente.
Em seguida, crie um diretório para armazenar seus arquivos de código de web scraping para a Amazon. Geralmente é uma boa ideia configurar um ambiente virtual para o seu projeto.
Use os seguintes comandos para criar e ativar um ambiente virtual no macOS e Linux:
$ python3 -m venv .env
$ source .env/bin/activatePara usuários do Windows, os comandos serão um pouco diferentes:
d:amazon>python -m venv .env
d:amazon>.envscriptsactivateAgora é hora de instalar os pacotes Python necessários.
Você precisará de pacotes para duas tarefas principais: obter o HTML e analisá-lo para extrair dados relevantes.
A biblioteca Requests é uma biblioteca Python de terceiros amplamente usada para fazer solicitações HTTP. Ele oferece uma interface simples e amigável para fazer solicitações HTTP a servidores web e receber respostas. É talvez a biblioteca mais conhecida para web scraping.
No entanto, a biblioteca Requests tem uma limitação: ela retorna a resposta HTML como uma string, o que pode ser difícil de pesquisar por elementos específicos, como listar preços, ao escrever código de web scraping.
É aí que entra o Beautiful Soup. Beautiful Soup é uma biblioteca Python projetada para web scraping que extrai dados de arquivos HTML e XML. Ele permite recuperar informações de uma página da web pesquisando tags, atributos ou texto específico.
Para instalar ambas as bibliotecas, use o seguinte comando:
$ python3 -m pip install requests beautifulsoup4Para usuários do Windows, substitua 'python3' por 'python', mantendo o restante do comando igual:
d:amazon>python -m pip install requests beautifulsoup4Observe que estamos instalando a versão 4 da biblioteca Beautiful Soup.
Agora vamos testar a biblioteca de scraping de solicitações. Crie um novo arquivo chamado amazon.py e insira o seguinte código:
import requests
url = 'https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L'
response = requests.get(url)
print(response.text)Salve o arquivo e execute-o no terminal.
$ python3 amazon.pyNa maioria dos casos, você não conseguirá visualizar o HTML desejado. A Amazon bloqueará a solicitação e você receberá a seguinte resposta:
To discuss automated access to Amazon data please contact [email protected].Se você imprimir o response.status_code, verá que receberá um erro 503 em vez de um código de sucesso 200.
A Amazon sabe que esta solicitação não veio de um navegador e a bloqueia. Essa prática é comum em muitos sites. A Amazon pode bloquear suas solicitações e retornar um código de erro começando com 500 ou às vezes até 400.
Uma solução simples é enviar cabeçalhos com sua solicitação que imitem aqueles enviados por um navegador.
Às vezes, enviar apenas o agente do usuário é suficiente. Outras vezes, pode ser necessário enviar cabeçalhos adicionais, como o cabeçalho de idioma aceito.
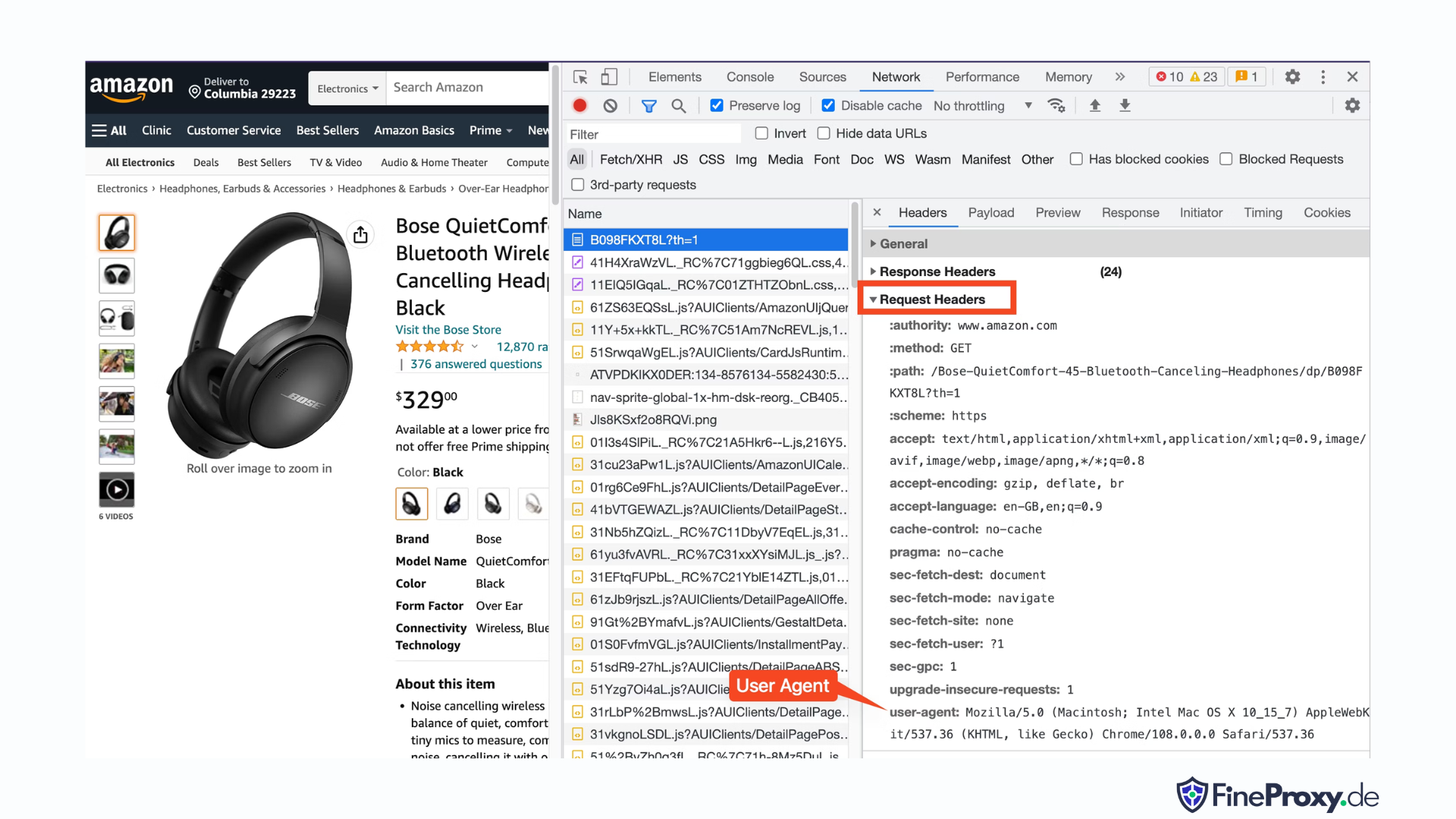
Para encontrar o user-agent enviado pelo seu navegador, pressione F12, abra a guia Rede e recarregue a página. Selecione a primeira solicitação e examine os cabeçalhos da solicitação.
Copie este agente de usuário e crie um dicionário para os cabeçalhos, como este exemplo com cabeçalhos de agente de usuário e linguagem de aceitação:
custom_headers = { '
user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'accept-language': 'en-GB,en;q=0.9',
}Você pode então enviar este dicionário como um parâmetro opcional no método get:
response = requests.get(url, headers=custom_headersRaspando informações de produtos da Amazon
No processo de web scraping de produtos da Amazon, você normalmente se envolverá com dois tipos de páginas: a página de categoria e a página de detalhes do produto.
Por exemplo, visite https://www.amazon.com/b?node=12097479011 ou pesquise fones de ouvido na Amazon. A página que exibe os resultados da pesquisa é conhecida como página de categoria.
A página da categoria apresenta o título do produto, a imagem do produto, a classificação do produto, o preço do produto e, o mais importante, a página de URLs do produto. Para acessar mais informações, como descrições de produtos, você deve visitar a página de detalhes do produto.
Vamos analisar a estrutura da página de detalhes do produto.
Abra o URL de um produto, como https://www.amazon.com/Bose-QuietComfort-45-Bluetooth-Canceling-Headphones/dp/B098FKXT8L, usando o Chrome ou outro navegador moderno. Clique com o botão direito no título do produto e escolha Inspecionar. A marcação HTML do título do produto será destacada.
Você notará que é uma tag span com seu atributo id definido como “productTitle”.

Da mesma forma, clique com o botão direito no preço e selecione Inspecionar para visualizar a marcação HTML do preço.
O componente dólar do preço está em uma etiqueta span com a classe “a-price-whole”, enquanto o componente centavos está em outra etiqueta span com a classe “a-price-fraction”.

Você também pode localizar a classificação, imagem e descrição da mesma maneira.
Depois de reunir essas informações, adicione as seguintes linhas ao código existente:
response = requests.get(url, headers=custom_headers)
soup = BeautifulSoup(response.text, 'lxml')Beautiful Soup oferece um método distinto de seleção de tags usando os métodos find. Ele também oferece suporte a seletores CSS como alternativa. Você pode usar qualquer uma das abordagens para obter o mesmo resultado. Neste tutorial, utilizaremos seletores CSS, um método universal para selecionar elementos. Os seletores CSS são compatíveis com quase todas as ferramentas de web scraping para extrair informações de produtos da Amazon.
Agora você está preparado para usar o objeto Soup para consultar informações específicas.
Extraindo o nome do produto
O nome ou título do produto é encontrado em um elemento span com o id 'productTitle'. Selecionar elementos usando IDs exclusivos é simples.
Considere o seguinte código como exemplo:
title_element = soup.select_one('#productTitle') Passamos o seletor CSS para o método select_one, que retorna uma instância do elemento.
Para extrair informações do texto, use o atributo text.
title = title_element.textQuando impresso, você poderá notar alguns espaços em branco. Para resolver isso, adicione uma chamada de função .strip() da seguinte maneira:
title = title_element.text.strip()Extraindo classificações de produtos
A obtenção de classificações de produtos da Amazon requer algum esforço adicional.
Primeiro, estabeleça um seletor para a classificação:
#acrPopoverA seguir, use a seguinte instrução para selecionar o elemento que contém a classificação:
rating_element = soup.select_one('#acrPopover')Observe que o valor real da classificação é encontrado no atributo title:
rating_text = rating_element.attrs.get('title')
print(rating_text)
# prints '4.6 out of 5 stars'Finalmente, empregue o método de substituição para obter a classificação numérica:
rating = rating_text.replace('out of 5 stars', '')Extraindo o preço do produto
O preço do produto pode ser encontrado em dois locais – abaixo do título do produto e na caixa Comprar Agora.
Qualquer uma dessas tags pode ser utilizada para reduzir os preços dos produtos da Amazon.
Crie um seletor CSS para o preço:
#price_inside_buyboxPasse este seletor CSS para o método select_one do BeautifulSoup assim:
price_element = soup.select_one('#price_inside_buybox')Agora você pode imprimir o preço:
print(price_element.text)Extraindo imagem
Para copiar a imagem padrão, use o seletor CSS #landingImage. Com essas informações, você pode escrever as seguintes linhas de código para obter o URL da imagem do atributo src:
image_element = soup.select_one('#landingImage')
image = image_element.attrs.get('src')Extraindo a descrição do produto
A próxima etapa na extração de dados de produtos da Amazon é obter a descrição do produto.
O processo permanece consistente – crie um seletor CSS e use o método select_one.
O seletor CSS para a descrição é:
#productDescriptionIsso nos permite extrair o elemento da seguinte forma:
description_element = soup.select_one('#productDescription')
print(description_element.text)Lidando com a lista de produtos
Exploramos a coleta de informações do produto, mas você precisará começar com a lista de produtos ou páginas de categoria para acessar os dados do produto.
Por exemplo, https://www.amazon.com/b?node=12097479011 é a página da categoria para fones de ouvido.
Se você examinar esta página, verá que todos os produtos estão contidos em uma div que possui um atributo exclusivo [data-asin]. Dentro dessa div, todos os links de produtos estão em uma tag h2.
Com essas informações, o Seletor CSS é:
[data-asin] h2 aVocê pode ler o atributo href deste seletor e executar um loop. Porém, lembre-se que os links serão relativos. Você precisará usar o método urljoin para analisar esses links.
from urllib.parse import urljoin
...
def parse_listing(listing_url):
…
link_elements = soup_search.select("[data-asin] h2 a")
page_data = []
for link in link_elements:
full_url = urljoin(search_url, link.attrs.get("href"))
product_info = get_product_info(full_url)
page_data.append(product_info)Lidando com paginação
O link para a próxima página está em um link contendo o texto “Próximo”. Você pode pesquisar este link usando o operador contains do CSS da seguinte maneira:
next_page_el = soup.select_one('a:contains("Next")')
if next_page_el:
next_page_url = next_page_el.attrs.get('href')
next_page_url = urljoin(listing_url, next_page_url)Exportando dados da Amazon
Os dados extraídos são retornados intencionalmente como um dicionário. Você pode criar uma lista contendo todos os produtos raspados.
def parse_listing(listing_url):
...
page_data = [] for link in link_elements:
...
product_info = get_product_info(full_url)
page_data.append(product_info)Você pode então usar este page_data para criar um objeto Pandas DataFrame:
df = pd.DataFrame(page_data)
df.to_csv('headphones.csv', index = False)Como raspar várias páginas na Amazon
A extração de várias páginas na Amazon pode aumentar a eficácia do seu projeto de web scraping, fornecendo um conjunto de dados mais amplo para análise. Ao segmentar várias páginas, você precisará considerar a paginação, que é o processo de divisão do conteúdo em várias páginas.
Aqui estão 6 pontos-chave para ter em mente ao copiar várias páginas na Amazon:
- Identifique o padrão de paginação: Primeiro, analise a estrutura do URL da categoria ou das páginas de resultados de pesquisa para entender como a Amazon pagina seu conteúdo. Pode ser um parâmetro de consulta (por exemplo, “?page=2”) ou um identificador exclusivo incorporado na URL.
- Extraia o link da página “Próximo”: Localize o elemento (geralmente uma tag âncora) que contém o link para a próxima página. Use o seletor CSS apropriado ou o método Beautiful Soup para extrair o atributo href deste elemento, que é o URL da próxima página.
- Converta URLs relativos em URLs absolutos: Como os URLs extraídos podem ser relativos, use o
urljoinfunção dourllib.parsebiblioteca para convertê-los em URLs absolutos. - Crie um loop: Implemente um loop que itere pelas páginas, extraindo os dados desejados de cada uma. O loop deve continuar até que não haja mais páginas restantes, o que pode ser determinado verificando se o link “Próxima página” existe na página atual.
- Adicione atrasos entre solicitações: Para evitar sobrecarregar o servidor da Amazon ou desencadear medidas anti-bot, introduza atrasos entre as solicitações usando o
time.sleep()função dotimebiblioteca. Ajuste a duração do atraso para emular o comportamento de navegação humano. - Lidando com CAPTCHAs e bloqueios: Se você encontrar CAPTCHAs ou blocos de IP ao copiar várias páginas, considere usar proxies para alternar endereços IP ou ferramentas e serviços de raspagem dedicados que possam lidar com esses desafios automaticamente.
Abaixo, você encontrará um tutorial em vídeo abrangente do YouTube que o orienta no processo de extração de dados de várias páginas do site da Amazon. O tutorial se aprofunda no mundo do web scraping, concentrando-se em técnicas que permitirão que você colete informações valiosas de várias páginas da Amazon de maneira eficiente e eficaz.
Ao longo do tutorial, o apresentador demonstra o uso de ferramentas e bibliotecas essenciais, como Python, BeautifulSoup e solicitações, ao mesmo tempo em que destaca as melhores práticas para evitar ser bloqueado ou detectado pelos mecanismos anti-bot da Amazon. O vídeo cobre tópicos essenciais como manipulação de paginação, gerenciamento de limites de taxa e imitação de comportamento de navegação humano.
Além das instruções passo a passo fornecidas no vídeo, o tutorial também compartilha dicas e truques úteis para otimizar sua experiência de web scraping. Isso inclui o uso de proxies para contornar as restrições de IP, randomizar o User-Agent e os cabeçalhos de solicitação e implementar o tratamento de erros adequado para garantir um processo de raspagem tranquilo e ininterrupto.
Raspando a Amazon: Perguntas frequentes
Quando se trata de extrair dados da Amazon, uma plataforma popular de comércio eletrônico, há certas coisas que é preciso estar atento. Vamos mergulhar nas perguntas frequentes relacionadas à coleta de dados da Amazon.
1. É legal raspar a Amazon?
A extração de dados disponíveis publicamente na Internet é legal e isso inclui a extração da Amazon. Você pode coletar informações legalmente, como detalhes de produtos, descrições, classificações e preços. No entanto, ao coletar análises de produtos, você deve ter cuidado com os dados pessoais e a proteção de direitos autorais. Por exemplo, o nome e o avatar do revisor podem constituir dados pessoais, enquanto o texto da revisão pode estar protegido por direitos autorais. Sempre tenha cuidado e procure aconselhamento jurídico ao coletar esses dados.
2. A Amazon permite raspagem?
Embora a coleta de dados disponíveis publicamente seja legal, a Amazon às vezes toma medidas para evitar a coleta. Essas medidas incluem solicitações de limitação de taxa, proibição de endereços IP e uso de impressão digital do navegador para detectar bots de raspagem. A Amazon geralmente bloqueia web scraping com um código de resposta de status de sucesso 200 OK e exige que você passe um CAPTCHA ou mostra uma mensagem HTTP Error 503 Service Unavailable para entrar em contato com o setor de vendas de uma API paga.
Existem maneiras de contornar essas medidas, mas o web scraping ético pode ajudar a evitar o seu desencadeamento. A raspagem ética da web envolve limitar a frequência das solicitações, usar agentes de usuário apropriados e evitar raspagem excessiva que possa afetar o desempenho do site. Ao fazer scraping de forma ética, você pode reduzir o risco de ser banido ou enfrentar consequências legais e, ao mesmo tempo, extrair dados úteis da Amazon.
3. É ético extrair dados da Amazon?
Scraping eticamente envolve respeitar o site de destino. Embora seja improvável que você sobrecarregue o site da Amazon com muitas solicitações, você ainda deve seguir as diretrizes éticas de scraping. A raspagem ética pode minimizar o risco de enfrentar questões legais ou lidar com medidas anti-raspagem.
4. Como posso evitar ser banido ao fazer scraping na Amazon?
Para evitar ser banido ao fazer scraping na Amazon, você deve limitar suas taxas de solicitação, evitar scraping durante os horários de pico, usar a rotação de proxy inteligente e usar agentes de usuário e cabeçalhos apropriados para evitar a detecção. Além disso, extraia apenas os dados necessários e use ferramentas ou bibliotecas de raspagem de terceiros.
5. Quais são os riscos de destruir a Amazônia?
A coleta de dados da Amazon acarreta riscos potenciais, como ações legais e suspensão de contas. A Amazon usa medidas anti-bot para detectar e prevenir scraping, incluindo proibições de endereços IP, limitação de taxa e impressão digital do navegador. No entanto, ao raspar eticamente, você pode mitigar esses riscos.
Conclusão
À medida que emergimos do fascinante labirinto do web scraping da Amazon, é hora de reservar um momento para apreciar o conhecimento e as habilidades inestimáveis que reunimos nesta jornada emocionante. Com o ProxyCompass como seu guia confiável, você navegou com sucesso pelas voltas e reviravoltas da extração de dados inestimáveis do gigante do varejo. À medida que você se aventura, exercendo seu novo conhecimento com sutileza, lembre-se de que a selva digital nunca para de evoluir.
Fique curioso, continue afiando seu facão de web scraping e continue conquistando o cenário em constante mudança da extração de dados. Até nossa próxima expedição ousada, intrépido explorador, que suas buscas baseadas em dados sejam frutíferas e gratificantes!

